基于DSP的Max-Log-MAP算法实现与优化
时间:05-27
来源:《现代电子技术》 作者:郭 晋,闫 涛
点击:
4.1 C6000系列芯片的结构与特点
TMS320C6000系列DSP是TI公司推出的一种基于VLIW技术,具有8个功能单元的数字信号处理器,其CPU采用哈佛结构,程序总线与数据总线分开,取指令与执行指令可以并行运行,VLIW技术的使用可以使指令获取、指令分配、指令执行和数据存储等操作形成多级流水,在同一时钟周期多条指令交迭地在不同功能单元内处理。C6000系列芯片在每个时钟周期内可以同时执行8条指令。
4.2 基于DSP的各算法模块代码优化
4.2.1 BMU模块
BMU算法模块为单循环语句,由于循环体内的指令较少,为了更多地同时利用CPU资源,一个有效的做法即是将循环展开,这样在减少循环次数的同时可以使更多的操作形成流水(pipeline),充分发挥多个功能单元的并行处理能力。优化后的代码如下:
由于状态度量的递推具有递归性,即本时刻递推得到的数值将用作下一时刻的递推初值,因此对于该算法模块的数据读入读出操作是一个值得考虑的问题。从3.2节SMU的程序分析可知,FSM的读写致使CPU寄存器与数据存储器之间频繁的进行load与store操作,为了减少该操作的指令消耗,我们引入3组临时变量FSM_tempj,FSMj_old和FSMj_new(j=0,1,…,7)用来存储FSM的计算结果,这样在下次递推时CPU可以直接从内部的寄存器读取数据,避免了从数据存储器的load操作。优化后的代码结构如下:
4.2.3 LLRU模块
对于LLRU算法模块的代码优化主要从减少加减操作指令入手,这涉及到对算法的改进。前文提到每一时刻的转移路径有16条,如果采用3.3节的程序结构,对分支度量要进行16次加减操作。考虑到分支度量只有4种取值,结合RSC(13,15)网格图的映射关系,按照分支度量的取值将转移路径分为4组,这4组分别对于分支度量的加减操作先不予处理,即先选最大后再进行相应的分支度量加减操作,这样每一次循环可以将分支度量的加减操作由原来的16次减少至4次,故可以大大降低CPU资源的消耗。相应的优化代码结构如下:
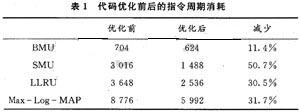
我们使用合众达公司的SEED-C6416仿真开发板,采用C6416-T系列DSP芯片在CCS 3.1编译环境下对各个算法模块及整个Max-Log-MAP算法进行了编译与硬件仿真,Turbo码的信息帧长选为144 b,代码的数据类型定义为int型,编译选项设置为-03-mt-pm。使用CCS附带的定时器(Timer)功能,对优化前后代码消耗的指令周期进行了测试,结果如表1所示。
5 结 语
本文研究了基于标准C语言的Turbo码Max-Log-MAP译码算法的软件编程与实现方法,并结合TMS320C6000系列DSP芯片的结构与特点深入探讨了代码的优化设计,通过循环展开、数据存取优化、算法的改进等措施提高代码的效率,测试结果表明,经过优化的代码可以大大降低CPU的指令周期消耗,从而获得了比较高效的处理性能。
TMS320C6000系列DSP是TI公司推出的一种基于VLIW技术,具有8个功能单元的数字信号处理器,其CPU采用哈佛结构,程序总线与数据总线分开,取指令与执行指令可以并行运行,VLIW技术的使用可以使指令获取、指令分配、指令执行和数据存储等操作形成多级流水,在同一时钟周期多条指令交迭地在不同功能单元内处理。C6000系列芯片在每个时钟周期内可以同时执行8条指令。
4.2 基于DSP的各算法模块代码优化
4.2.1 BMU模块
BMU算法模块为单循环语句,由于循环体内的指令较少,为了更多地同时利用CPU资源,一个有效的做法即是将循环展开,这样在减少循环次数的同时可以使更多的操作形成流水(pipeline),充分发挥多个功能单元的并行处理能力。优化后的代码如下:
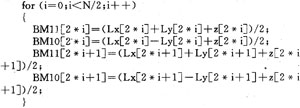
由于状态度量的递推具有递归性,即本时刻递推得到的数值将用作下一时刻的递推初值,因此对于该算法模块的数据读入读出操作是一个值得考虑的问题。从3.2节SMU的程序分析可知,FSM的读写致使CPU寄存器与数据存储器之间频繁的进行load与store操作,为了减少该操作的指令消耗,我们引入3组临时变量FSM_tempj,FSMj_old和FSMj_new(j=0,1,…,7)用来存储FSM的计算结果,这样在下次递推时CPU可以直接从内部的寄存器读取数据,避免了从数据存储器的load操作。优化后的代码结构如下:
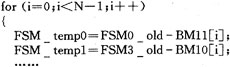
4.2.3 LLRU模块
对于LLRU算法模块的代码优化主要从减少加减操作指令入手,这涉及到对算法的改进。前文提到每一时刻的转移路径有16条,如果采用3.3节的程序结构,对分支度量要进行16次加减操作。考虑到分支度量只有4种取值,结合RSC(13,15)网格图的映射关系,按照分支度量的取值将转移路径分为4组,这4组分别对于分支度量的加减操作先不予处理,即先选最大后再进行相应的分支度量加减操作,这样每一次循环可以将分支度量的加减操作由原来的16次减少至4次,故可以大大降低CPU资源的消耗。相应的优化代码结构如下:

我们使用合众达公司的SEED-C6416仿真开发板,采用C6416-T系列DSP芯片在CCS 3.1编译环境下对各个算法模块及整个Max-Log-MAP算法进行了编译与硬件仿真,Turbo码的信息帧长选为144 b,代码的数据类型定义为int型,编译选项设置为-03-mt-pm。使用CCS附带的定时器(Timer)功能,对优化前后代码消耗的指令周期进行了测试,结果如表1所示。
5 结 语
本文研究了基于标准C语言的Turbo码Max-Log-MAP译码算法的软件编程与实现方法,并结合TMS320C6000系列DSP芯片的结构与特点深入探讨了代码的优化设计,通过循环展开、数据存取优化、算法的改进等措施提高代码的效率,测试结果表明,经过优化的代码可以大大降低CPU的指令周期消耗,从而获得了比较高效的处理性能。
DSP Max-Log-MAP 算法实现与优化 相关文章:
- 在采用FPGA设计DSP系统中仿真的重要性 (06-21)
- 基于 DSP Builder的FIR滤波器的设计与实现(06-21)
- 达芬奇数字媒体片上系统的架构和Linux启动过程(06-02)
- FPGA的DSP性能揭秘(06-16)
- 用CPLD实现DSP与PLX9054之间的连接(07-23)
- DSP+FPGA结构在雷达模拟系统中的应用(01-02)