FPGA时序收敛分析
您编写的代码是不是虽然在仿真器中表现正常,但是在现场却断断续续出错?要不然就是有可能在您使用更高版本的工具链进行编译时,它开始出错。您检查自己的测试平台,并确认测试已经做到 100% 的完全覆盖,而且所有测试均未出现任何差错,但是问题仍然顽疾难除。
虽然设计人员极其重视编码和仿真,但是他们对芯片在 FGPA 中的内部操作却知之甚少,这是情有可原的。因此,不正确的逻辑综合和时序问题(而非逻辑错误)成为大多数逻辑故障的根源。
但是,只要设计人员措施得当,就能轻松编写出能够创建可预测、可靠逻辑的 FPGA 代码。
在 FPGA 设计过程中,需要在编译阶段进行逻辑综合与相关时序收敛。而包括 I/O 单元结构、异步逻辑和时序约束等众多方面,都会对编译进程产生巨大影响,致使其每一轮都会在工具链中产生不同的结果。为了更好、更快地完成时序收敛,我们来进一步探讨如何消除这些差异。
I/O 单元结构
所有 FPGA 都具有可实现高度定制的 I/O 引脚。定制会影响到时序、驱动强度、终端以及许多其它方面。如果您未明确定义 I/O 单元结构,则您的工具链往往会采用您预期或者不希望采用的默认结构。如下 VHDL 代码的目的是采用“sda: inout std_logic;”声明创建一个称为 sda 的双向 I/O 缓冲器。

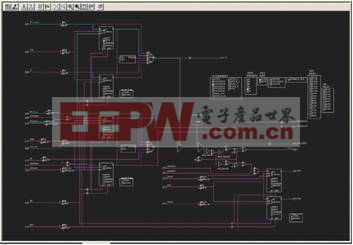
图1 – FPGA 编辑器视图显示了部分双向I/O散布在I/O缓冲器之外。
当综合工具发现这组代码时,其中缺乏如何实施双向缓冲器的明确指示。因此,工具会做出最合理的猜测。
实现上述任务的一种方法是,在 FPGA 的 I/O 环上采用双向缓冲器(事实上,这是一种理想的实施方式)。另一种选择是采用三态输出缓冲器和输入缓冲器,二者都在查询表 (LUT) 逻辑中实施。最后一种可行方法是,在 I/O 环上采用三态输出缓冲器,同时在 LUT 中采用输入缓冲器,这是大多数综合器选用的方法。这三种方法都可以生成有效逻辑,但是后两种实施方式会在I/O 引脚与 LUT 之间传输信号时产生更长的路由延迟。此外,它们还需要附加的时序约束,以确保时序收敛。FPGA 编辑器清晰表明:在图 1 中,我们的双向 I/O 有一部分散布在 I/O 缓冲器之外。
教训是切记不要让综合工具猜测如何实施代码的关键部分。即使综合后的逻辑碰巧达到您的预期,在综合工具进入新版本时情况也有可能发生改变。应当明确定义您的 I/O 逻辑和所有关键逻辑。以下 VHDL 代码显示了如何采用 Xilinx® IOBUF 原语对 I/O 缓冲器进行隐含定义。另外需要注意的是,采用相似方式明确定义缓冲器的所有电气特性。

在图 2 中,FPGA 编辑器明确显示,我们已完全在 I/O 缓冲器内部实施了双向 I/O。
异步逻辑的劣势
异步代码会产生难以约束、仿真及调试的逻辑。异步逻辑往往产生间歇性错误,而且这些错误几乎无法重现。另外,无法生成用于检测异步逻辑所导致的错误的测试平台。
虽然异步逻辑看起来可能容易检测,但是,事实上它经常不经检测;因此,设计人员必须小心异步逻辑在设计中隐藏的许多方面。所有钟控逻辑都需要一个最短建立与保持时间,而且这一点同样适用于触发器的复位输入。以下代码采用异步复位。在此无法为了满足触发器的建立与保持时间需求而应用时序约束。
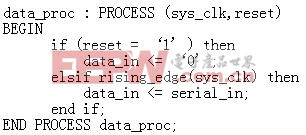
下列代码采用同步复位。但是,大多数系统的复位信号都可能是按键开关,或是与系统时钟无关的其它信号源。尽管复位信号大部分情况是静态的,而且长期处于断言或解除断言状态,不过其水平仍然会有所变化。相当于系统时钟上升沿,复位解除断言可以违反触发器的建立时间要求,而对此无法约束。

只要我们明白无法直接将异步信号馈送到我们的同步逻辑中,就很容易解决这个问题。以下代码创建一个称为 sys_reset 的新复位信号,其已经与我们的系统时钟 sys_clk 同步化。在异步逻辑采样时会产生亚稳定性问题。我们可以采用与阶梯的前几级进行了’与’运算的梯形采样降低此问题的发生几率。

至此,假定您已经慎重实现了所有逻辑的同步化。不过,如果您不小心,则您的逻辑很容易与系统时钟脱节。切勿让您的工具链使用系统时钟所用的本地布线资源。那样做的话您就无法约束自己的逻辑。切记要明确定义所有的重要逻辑。
以下 VHDL 代码采用赛灵思 BUFG 原语强制 sys_clk 进入驱动低延迟网络 (low-skew net) 的专用高扇出缓冲器。

某些设计采用单个主时钟的分割版本来处理反序列化数据。以下 VHDL 代码(nibble_proc进程)举例说明了按系统时钟频率的四分之一采集的数据。


看起来好像一切都已经同步化,但是 nibble_proc 采用乘积项 divide_by_4 对来自时钟域sys_clk_bufg 的 nibble_wide_data 进行采样。由于路由延迟,divde_by_4 与 sys_clk_bufg 之间并无明确的相位关系。将 divide_by_4 转移到 BUFG 也于事无补,因为此进程会产生路由延迟。解决方法是将 nibble_proc 保持在 sys_clk_bufg 域,并且采用 divide_by_4 作为限定符,如下所示。
- 基于赛灵思Spartan-3A DSP的安全视频分析(02-17)
- 关于Linux操作系统的NTFS和内核分析(05-19)
- Linux 2.4.x内核软中断机制(04-06)
- 基于DSP的人脸识别系统设计(04-26)
- 3D图形芯片的算法原理分析(07-16)
- 解析:视频图像智能分析处理技术(08-08)