10Gbps线速转发引擎的并行流水线设计与实现
当前,线路传输技术发展迅速,光传输技术更是进步飞速,无论是单波长载荷速率还是单纤可用波长数量,都以惊人的速度增长。目前,已出现各种10Gbps的接口类型,如POS、LAN、WAN等。作为T比特路由器的核心部分,转发引擎的线速报文转发能力决定了路由器所能够支持的最高端口速率。T比特路由器中线速转发引擎必须支持10Gbps接口,而传统的报文处理结构由于单包处理时间过长,已无法满足线速转发的性能需求。
1 线速转发引擎的结构设计
转发引擎是高性能T比特路由器的关键部分之一,其设计的合理性、性能的优劣直接影响路由器的整体性能。当前,业界的硬件转发引擎主要有两种方案:一种是基于网络处理器的转发引擎,一种是基于FPGA平台的转发引擎。本设计采用FPGA作为设计平台,如此选择主要是出于以下两点考虑:
(1)目前支持端口速率为10Gbps的线速处理的商用网络处理器还不成熟,尤其是没有自主知识产权、安全性弱、受芯片提供商的制约,所以网络处理器并不是最佳选择;
(2)采用FPGA是为设计单片转发系统(SOC)奠定基础,最终目的是要实现我国自主的高性能网络处理器。
数据包的10Gbps线速转发,报文转发率达到31.25Mpps以上,支持IPv4、IPv6和MPLS三种类型报文的处理,支持IPv4、IPv6优先级分类,支持组播以及1M路由表项等,都是T比特路由器必须实现的关键技术指标。为此,10Gbps线速转发引擎采用基于大规模FPGA、TCAM和SRAM的全硬件流水并行结构,利用硬件的高速特性和高可靠性,实时处理路由分组的各项信息并对路由分组进行硬件线速转发。
下面给出一种基于FPGA的转发引擎结构,该引擎采用并行处理方式和流水线结构,有效地降低了报文的处理时间,实现了对多协议报文的支持,达到了10Gbps线速转发的性能需求。
2 并行处理结构的设计
并行机制就是对同一段时间内需要处理的每个任务各采用一个处理通道的并行方式进行操作,从而使多个任务所需的处理时间降至最少。转发引擎要进行报头分析、QoS实现、安全检测、直连检查、单播查表、组播查表等处理。并行处理方式就是按照各个功能模块之间在处理顺序上的关联性,将以上的功能模块进行并行处理;并尽可能对并行技术进行进一步挖掘。以报头分析模块为例,可进一步分为版本号检查、TTL检查、地址范围检查、有效负载长度检查等四个小模块,进而进行小模块的并行处理。并行处理结构如图1所示。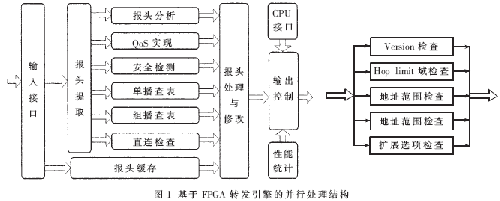
采用并行处理技术之后的总处理时间只是其中关键并行模块的处理时间,关键并行模块是指所有并行处理模块中处理时间最长的模块。
3 流水线机制的设计
若要在数据速率高达10Gbps的条件下实现IPv6最短包(长度为40字节)的线速转发,则转发引擎处理一个数据包的最长时间为:IP报文长度(字节)×8(比特)/端口速率(Gbps)=40×8/10=32ns。即使采用100MHz的时钟,处理时间也只有3.2个周期,要在如此短的时间里完成复杂的IP报文处理,必须采用流水线设计。
3.1 系统级流水线
基于FPGA的转发引擎内部各大模块间的流水线,本文称为系统级流水线。转发引擎的系统级流水线结构如图2所示。
该流水线结构将转发处理分为接口转换、报头提取、路由查表、报头处理与修改、输出控制等五个流水操作子进程。它们都是在时间上先后执行的串行任务单元,且前后子进程之间的操作相互独立。转发引擎采用流水线操作以后,只要各子进程能满足给定接口速率下最短报文的处理时间要求,则整个转发引擎就支持该接口速率。
3.2 流水线查表设计
在该流水线各段中,需要时间最长的功能段为路由查表。在查表模块进一步引入流水线设计,可以减少整个转发处理的流水时间,使之能够满足路由器性能要求。
硬件查表通常由TCAM完成,传统的TCAM查表流程如图3所示。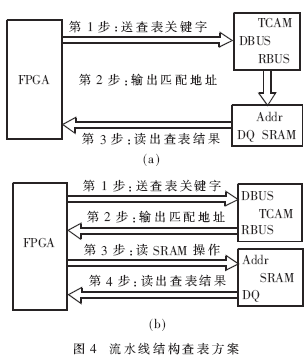
传统查表由TCAM搜索和TCAM读表项两个操作串行进行,无流水线操作,整个过程需要十几个时钟周期。
在本文提出的由TCAM和SRAM共同完成路由查表的流水线结构中,查表分两级进行:由TCAM完成搜索过程,再由SRAM读出查表结果。这样可将查表时间缩短为4个周期。
在本流水查表方案中,TCAM表项仅存储查表关键字,查表结果则存储在SRAM的相应地址空间中。对于单播查表,目的IP地址作为查表关键字保存在TCAM的某个地址中,目的接口号作为查表结果则保存在SRAM中的相应地址空间中,这样就构成一条完整的单播表项。其流程如图4所示。
图4给出了两种流水线设计方案,它们的区别主要在于是否将TCAM的RBUS直接连接到SRAM的地址总线上。
(1) 方案(a)是将TCAM的RBUS直接作为SRAM的读取地址,优点是PCB制作略为简单,减少FPGA中User I/O资源紧张的问题,缺点是写表项的时间较长。因为写SRAM表项必须通过相应的TCAM操作才能进行,即写TCAM表项和写SRAM表项均通过TCAM来完成,所以写一条完整表项的时间为二者处理时间之和。
(2)方案(b)是将TCAM的结果总线RBUS与SRAM的地址总线通过FPGA连接起来,虽然增加了PCB制作的难度,但由于写表项时TCAM和SRAM的写操作可同时进行,因而写一条完整表项的时间为这二者处理时间的较大值。通常TCAM的读写时间远大于SRAM的读写时间。
通过TCAM写SRAM表项的时间往往与单独写TCAM表项的时间相当,即方案(a)写表项的时间大大超过方案(b),因而方案(b)具有更好的线速转发性能。
- 在采用FPGA设计DSP系统中仿真的重要性 (06-21)
- 基于 DSP Builder的FIR滤波器的设计与实现(06-21)
- 基于FPGA的快速并行FFT及其在空间太阳望远镜图像锁定系统中的应用(06-21)
- 3DES算法的FPGA高速实现(06-21)
- 用FPGA实现FFT算法(06-21)
- FPGA的DSP性能揭秘(06-16)