下一代数据包处理技术架构选择
每种架构都有其长处。通常情况是,每个系统供应商的设计决策归根到底都是平台的预期任务。从本质上讲,决策过程就是根据应用选择架构的过程。
数据包处理背景
数据包处理是数据密集型操作,需要优化的硬件。在宽带互联网出现之前,通用处理器既被用于控制会话处理又肩负用户流量的数据包处理。
但是,由数据和控制平面共享中央处理单元(CPU)资源的作法已被证明难以满足随带宽需求增长带来的更高要求。对于交换机和路由器来说,数据平面的数据包处理任务已转交给定制的固定功能ASIC或可编程网络处理器单元(NPU)。从而把通用CPU解放出来以专门应对控制平面任务。
有几家NPU供应商一直在试图针对2-4层包处理任务优化通用处理器,并提供集成了网络硬件(即物理层、媒体存取控制器和表存储器)以及用于特定任务(即散列)的硬件引擎的多核架构。在20世纪末20世纪初,MMC、C-Port和英特尔的IXP部门等机构开发了这类器件。
虽然这些产品各有不同,但它们的基本架构是相同的。通过降低复杂性,处理器核能够得到简化,从而使得器件内可以集成数十个处理器核以满足更高的并行要求。
除了极少数例外,这些NPU供应商在商业上都不成功。根本原因是这些NPU不能有效地满足超过10Gbps的网络应用对处理能力和存储器访问方面的要求。
现在,当我们迈进2010年,我们看到了旨在应对网络处理市场的新一代多核供应商的出现。虽然CMOS技术、存储器带宽和时钟周期性能得到了提升,但它们仍基于同样的基本架构。因此,这些新兴公司能期待获得更大的成功吗?
这将取决于它们针对的是哪类应用。现在的网络节点不仅处理2-4层的数据包,也需在更高层进行处理以支持服务和增加安全性。我们将研究其中的差异,以及对任何给定应用来说,为什么某些架构比其它架构效果更好。
线速包处理
2-4层数据包处理不同于其它网络应用(表1)。首先,能对所有大小的数据包进行线速处理是一个关键目标。现代路由器和交换机被设计为拥有广泛的网络功能,服务提供商期望能同时获得这些功能且不降低性能。

第二,数据平面将数据包视为独立个体,允许高度并行的处理。对一个100Gbps应用来说,网络处理器需要每秒处理1.5亿个数据包以确保线速性能。处理器10μs的延时相当于1,500个数据包的并行处理时间。
第三,数据平面程序需要高I/O存储器访问带宽以完成表查询转发、状态更新及其它处理。在高速平台上,数据包到达间隔时间非常短,因而对存储器延时提出了苛刻要求。对于小型数据包来说,执行这些任务的存储器带宽是链路带宽的数倍。
最后,当今网络的功耗很高。出于运营成本和环保两方面的考虑,服务提供商在煞费苦心地追求最佳的每瓦性能。考虑到包处理的特点,应以线速性能条件下、每瓦功率可实现的最高性能来衡量最有效的架构。
服务和安全处理特征
与数据包处理相近的市场是服务和安全处理。这些应用具有与2-4层数据包处理不同的特点。因此,可实施其它的硬件设计优化。
在客户机-服务器方式中,这些应用终止和处理主机至主机协议,或在中间网络节点(即防火墙、负载均衡器、入侵和防御系统)上处理重组的净载数据包数据。这些产品必须能够跨数据包边界工作,因为它们通常需要在更大的数据量上进行更大规模的操作,这将导致数据并行性较低。另一方面,相对所处理的数据而言,这类所需的I/O存储器带宽较低。
架构比较
NPU承诺可提供定制ASIC的性能,且具有通用处理器的可编程能力。但是,比较处理器的性能较困难,因为理论上的最大值通常与真实世界关联不大。此外,有效利用可用处理性能的能力,以及与处理容量相关的I/O存储器的利用情况也是影响处理器性能的因素。
因此,这种比较必须从设计层面开始。我们首先从一个通用多核NPU架构开始。多核NPU架构衍生于通用处理器架构,该架构希望通过增加处理器核来实现更高的并行处理能力。降低复杂性并移除当今通用处理器架构内不必要的功能(即浮点指令)可实现这一目标。
多核NPU架构对处理器核进行了专门分组。这些内核或被分组到各个并行池或以串行方式进行流水线排列(图1)。NPU供应商在设计时,允许架构对这种分组实施严格控制以优化性能。
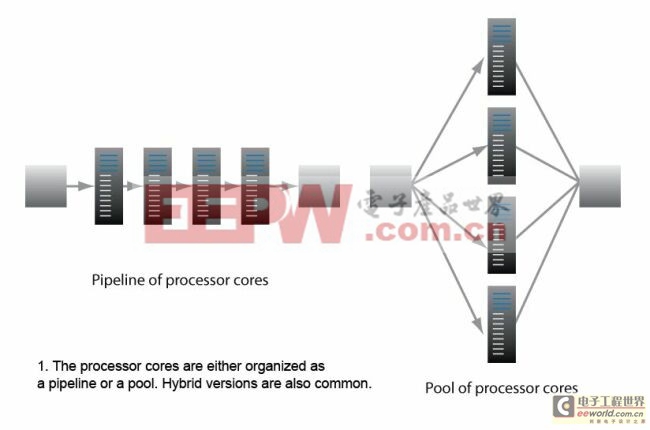
图1:处理器核采用流水线或者并行池架构,混合模式也很常见。
如果定义得较松散,这种分组就允许程序员更自由地在内核间划分任务,最终结果是以性能控制为代价提供更大的灵活性。在许多情况下,多核网络处理
模拟电路 模拟芯片 德州仪器 放大器 ADI 模拟电子 相关文章:
- 12位串行A/D转换器MAX187的应用(10-06)
- AGC中频放大器设计(下)(10-07)
- 低功耗、3V工作电压、精度0.05% 的A/D变换器(10-09)
- PIC16C5X单片机睡眠状态的键唤醒方法(11-16)
- 用简化方法对高可用性系统中的电源进行数字化管理(10-02)
- 利用GM6801实现智能快速充电器设计(11-20)