cpld fpga 区别
/br>
经常会看到在状态机设计中别人使用各种不同的编码方式,那么一般情况下,这种编码方式的选择依据是什么?
我们知道,在数字逻辑设计中最常用的有三种编码方式:二进制,格雷码 Gray,独热编码One-hot One hot 编码使用一组码元,每一个码元仅有1bit有效,例如
IDLE = 0001,
WRITE = 0010,
READ = 0100,
WAIT = 1000
这种编码的译码部分可以最简,因此可以总结出One-hot编码的特点:
组合逻辑最少,触发器最多,工作时钟频率可以做到最高。
FPGA 的一个最小结构单元(CLB/LE)中含有查找表(实现组合逻辑)和DFF(实现时序逻辑),布局布线最好的结果是同一个结构单元中的查找表和DFF都使用,但是大部分情况是仅使用其中一种资源,这样另外的资源就是闲置而浪费。而CPLD中DFF资源本来就很少,由此可见One-hot编码更适合于 FPGA设计,而不适合CPLD设计,在CPLD中应该选择二进制编码。
IC设计中,应该综合考虑。因为One-hot编码使用DFF会大大增加设计面积(die size),因此在时序可以满足的条件下尽可能使用二进制编码。就面积与速度的折中考虑来说Gray码是最好的选择,当然Gray码还有其他很多好的特性,暂时不属于这次讨论的范畴。一般的综合工具对状态机进行综合时都可以让用户对这三种编码进行选择。基本依据就以上所说。
二进制与格雷码之间的转换
自然二进制码转换成二进制格雷码,其法则是保留自然二进制码的最高位作为格雷码的最高位,而次高位格雷码为二进制码的高位与次高位相异或,而格雷码其余各位与次高位的求法相类似
二进制格雷码转换成自然二进制码,其法则是保留格雷码的最高位作为自然二进制码的最高位,而次高位自然二进制码为高位自然二进制码与次高位格雷码相异或,而自然二进制码的其余各位与次高位自然二进制码的求法相类似
通过减少寄存器间的逻辑延时来提高工作频率,或通过流水线设计来优化数据处理时的数据通路来满足高速环境下FPGA或CPLD中的状态机设计要求。本文给出了采用这些技术的高速环境状态机设计的规范及分析方法和优化方法,并给出了相应的示例。
为了使FPGA或CPLD中的状态机设计满足高速环境要求,设计工程师需要认识到以下几点:寄存器资源和逻辑资源已经不是问题的所在,状态机本身所占用的FPGA或CPLD逻辑资源或寄存器资源非常小;状态机对整体数据流的是串行操作,如果希望数据处理的延时非常小,就必须提高操作的并行程度,压缩状态机中状态转移的路径长度;高速环境下应合理分配状态机的状态及转移条件。本文将结合实际应用案例来说明。
状态机设计规范
1. 使用一位有效的方式进行状态编码
状态机中状态编码主要有三种:连续编码(sequential encoding)、一位有效(one-hot encoding)方式编码以及不属于这两种的编码。例如,对于一个5个状态(State0~State4)的状态机,连续编码方式状态编码为:State0-000、State1-001、State2-010、State3-011、State4-100。一位有效方式为下为:State0-00001、State1-00010、State2-00100、State3-01000、State4-10000。对于自行定义的编码则差别很大,例如试图将状态机的状态位直接作为输出所需信号,这可能会增加设计难度。
使用一位有效编码方式使逻辑实现更简洁,因为一个状态只需要用一位来指示,而为此增加的状态寄存器数目相对于整个设计来说可以忽略。一位有效至少有两个含义:对每个状态位,该位为1对应唯一的状态,判断当前状态是否为该状态,只需判断该状态位是否为1;如果状态寄存器输入端该位为1,则下一状态将转移为该状态,判断下一状态是否为该状态,只需判断表示下一状态的信号中该位是否为1。
2. 合理分配状态转移条件
在状态转移图中,每个状态都有对应的出线和入线,从不同状态经不同的转移条件到该状态的入线数目不能太多。以采用与或逻辑的CPLD设计来分析,如果这样的入线太多则将会需要较多的乘积项及或逻辑,这就需要更多级的逻辑级联来完成,从而增加了寄存器间的延迟;对于FPGA则需要多级查找表来实现相应的逻辑,同样会增加延迟。状态机的应用模型如图1所示。 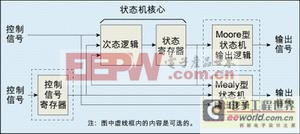
状态机设计的分析方法
状态机设计的分析方法可以分为两种:一种是流程处理分析,即分析数据如何分步处理,将相应处理的步骤依次定为不同状态,该方法能够分析非常复杂的状态机,类似于编写一个软件程序的分析,典型设计如读写操作和数据包字节分析;另一种方法是关键条件分析,即根据参考信号的逻辑条件来确定相应的状态,这样的参考信号如空或满指示、起始或结束、握手应答信号等。这两种分析方法并没有严格的界限,在实际的状态机设计分析时往往是这两种方法结合使用。下面分别说明这两种分析方法。
1. 流程处理分析
例如,在一个读取ZBT SRAM中数据包的设计中,要根据读出的数据中EOP(End of Packet)信号是否为1来决定一个包的读操作是否结束,由于读取数据的延后,这样就会从ZBT SRAM中多读取数据,为此可以设计一个信号VAL_out来过滤掉多读的数据。 
根据数据到达的先后及占用的时钟周期数,可以设计如图2所示的状态机(本文设定:文字说明及插图中当前状态表示为s_State[n:0],为状态寄存器的输出;下一状态next_State[n:0],为状态寄存器的输入;信号之间的逻辑关系采用Verilog语言(或C语言)中的符号表示;#R表示需要经过一级寄存器,输出信号对应寄存器的输出端)。该状态机首先判断是否已经到达包尾,如果是,则依次进入6个等待状态,等待状态下的数据无效,6个等待状态结束后将正常处理数据。
2. 关键条件分析
图3为一个路由器线卡高速数据包分发处理的框图,较高速率的数据包经过分发模块以包为单位送往两个较低速率数据通路(即写入FIFO1或FIFO2)。
对于分发模块设计,关键参考信号是EOP及快满信号AF1、AF2,参考EOP可以实现每次处理一个包,参考AF1、AF2信号可以决定相应的包该往哪个FIFO中写入。分发算法为:FIFO1未满(AF1=0),数据包将写入FIFO1;如果FIFO1将满且FIFO2未满(AF1=1,且AF2=0),则下一数据包将写入FIFO2;如果FIFO1、FIFO2都将满(AF1=1且AF2=1),则进入丢包状态。状态机描述如图4所示:UseFifo1状态下数据包将写入FIFO1,UseFifo2状态下数据包将写入FIFO2,丢包状态下数据包被丢弃,提供丢包计数使能DropCountEnable。
状态机的进一步优化
1. 利用一位有效编码方式HSPACE=12 alt="cpld fpga 区别 ">
如前所述,状态机的工作频率跟状态机中各个状态对应的不同转移条件的入线数目有关。如果到一个状态的转移条件相同但入线数非常多,其逻辑实现很可能并不复杂。在一位有效编码方式下,对于某个状态,如果其他所有状态经相同的转移条件到该状态,那么其逻辑实现可以很好地化简。
例4:一位有效编码方式下状态位s_State[n:0]中,
s_State[1] | s_State[2] | ... | s_State[n]=1与 s_State[0]=1等价,那么
next_State[0]=(s_State[0]S) | (s_State[1]T) | (s_State[2]T) | ... | (s_State[n]) 可以化简为:
next_State[0]=(s_State[0]S) | ((~s_State[0])T),右端输入信号数目大大减少。
2. 利用寄存器的使能信号
多数FPGA或CPLD寄存器提供使能端,如果所有的状态机转移必须至少满足某个条件,那么这个条件可以通过使能信号连接实现,从而可以降低寄存器输入端的逻辑复杂度。如上例中不同状态间转移必须以EOP为1作为前提,因而可以将该信号作为使能信号来设计。
3. 结合所选FPGA或CPLD内部逻辑单元结构编写代码
以Xilinx FPGA为例,一个单元内2个4输入查找表及相关配置逻辑可以实现5个信号输入的最复杂的逻辑,或8~9个信号的简单逻辑(例如全与或者全或),延时为一级查找表及配置逻辑延时;如果将相邻单元的4个4输入查找表输出连接到一个4输入查找表,那么可以实现最复杂的6输入逻辑,此时需要两级查找表延时及相关配置逻辑延时。更复杂的逻辑需要更多的级连来实现。针对高速状态机的情况,可以尽量将状态寄存器输入端的逻辑来源控制在7个信号以内,从而自主控制查找表的级连级数,提高设计的工作频率。
4. 通过修改状态机
如果一个状态机达不到工作频率要求,则必须根据延时最大路径修改设计,通常的办法有:改变状态设置,添加新状态或删除某些状态,简化转移条件及单个状态连接的转移数目;修改转移条件设置,包括改变转移条件的组合,以及将复杂的逻辑改为分级经寄存器输出由寄存器信号再形成的逻辑,后者将会改变信号时序,因而可能需要改变状态设置。
5. 使用并行逻辑
很多情况下要参考的关键信号可能非常多,如果参考这些关键信号直接设计状态机所得到的结果可能很复杂,个别状态的出线或入线将会非常多,因而将降低工作频率。可以考虑通过设计并行逻辑来提供状态机的关键信号以及所需的中间结果,状态机负责维护并行逻辑以及产生数据处理的流程。并行逻辑应分级设计,级间为寄存器,从而减少寄存器到寄存器的延时。
图5为一个使用并行逻辑的状态机,该设计用于使用单一数据总线将FIFO1~4中的数据发送到4个数据通路上去,该设计中并行逻辑产生每次操作时的通路及FIFO选择结果,状态机负责控制每次操作的流程:在“Idle”状态下,如果FIFO1~4中有数据包供读取,则进入“Schedule”状态;获得调度结果后“Schedule”经过一个“Wait”状态,然后进入“ReadData”状态读取数据,同时开始计数,计数到达所指定数值或者读到数据包尾时进入空闲状态“Idle”,依次循环下去。
流水线设计
流水线(Pipelining)设计是将一个时钟周期内执行的逻辑操作分成几步较小的操作,并在较高速时钟下完成。图6a中逻辑被分为图6b中三小部分,如果它的Tpd为T,则该电路最高时钟频率为1/T,而在图6b中假设每部分的Tpd为T/3,则其时钟频率可提高到原来的3倍,因而单位时间内的数据流量可以达到原来的三倍。代价是输出信号相对于输入滞后3个周期,时序有所改变(图6b中输出信号的总延时与图6a中一样,但数据吞吐量提高了),同时增加了寄存器资源,而FPGA具有丰富的寄存器资源。
本文所强调的通过减少寄存器间的逻辑延时来提高状态机的工作频率,与流水线设计的出发点一样,不同的是流水线所强调的是数据处理时的数据通路优化,而本文所强调的是状态机中控制逻辑的优化
- 基于DSP和CPLD的移相全桥软开关电源数字控制器(06-02)
- 基于CPLD的MIDI音乐播放器的设计(06-16)
- 基于CPLD的电器定时开关控制系统设计(08-17)
- 基于CPLD和VS1011E解码器的电梯语音系统设计(11-26)
- 基于DSP和CPLD的软开关电源数字控制器(01-14)
- ADS8323与高速FIFO接口电路的CPLD实现(03-26)