零基础学FPGA (十八) 谈可编程逻辑设计思想与技巧!对您肯定有用!
时间:02-17
来源:互联网
点击:
今天给大家带来的是我们在FPGA设计中经常要遇到的设计技巧与思想,即乒乓操作,串并转换,流水线操作和跨时钟域信号的同步问题。
之前也看过一些书,也在网上找过一些资料,不过小墨发现大部分都是理论讲解,仅仅是给一个框图就没事了,或者是好几个网站的资料都是一样的,都是复制的一个地方的,仅仅是讲解,没有实例,要不就是某个网站提供源码,但是要注册,还要花什么积分,没有积分还得要钱...很不利于初学者的学习(人与人之间怎么就不能多点信任呢~还要钱...)。所以小墨想写这么一篇文章来介绍一下这4种思想,理论部分书上多得是,我就不过多的解释,主要给大家讲一些实例型的帮大家理解。
一、乒乓操作
乒乓操作主要用于数据流的处理,是用面积换取速度的体现之一,要知道面积与速度的互换贯穿FPGA设计的始终,下面先给一个框图

我先来解释一下乒乓操作的过程:
首先数据需要通过一个2选一数据选择器,在第一个时钟周期将数据缓存到缓存模块1,常用的缓存模块可以是fifo,双口RAM(DPRAM),单口RAM(SPRAM),第二个时钟周期的时候,数据流开始往缓存模块2里面写数据,与此同时,预处理模块会从缓存模块1里面读取数据,到了第三个时钟周期数据流再往缓存模块1里面写数据,与此同时,预处理模块2开始从缓存模块2读取数据,周而复始...这样,输入数据流和输出数据流按节拍来回切换,可以使数据没有停顿的进行传输,使传输速率大大提高。
小墨同学发现,在给这个框图配实例的时候,几乎所有的网站都是这个解释,我用红字标出,个人感觉解释的不怎么样,还有些地方是错的
[color=] 假设端口 A 的输入数据流的速率为 100Mbps ,乒乓操作的缓冲周期是 10ms 。以下分析各个节点端口的数据速率。
[color=] A 端口处输入数据流速率为 100Mbps ,在第 1 个缓冲周期 10ms 内,通过 “ 输入数据选择单元 ” ,从 B1 到达 DPRAM1 。 B1 的数据速率也是 100Mbps , DPRAM1 要在 10ms 内写入 1Mb 数据。同理,在第 2 个 10ms ,数据流被切换到 DPRAM2 ,端口 B2 的数据速率也是 100Mbps , DPRAM2 在第 2 个 10ms 被写入 1Mb 数据。在第 3 个 10ms ,数据流又切换到 DPRAM1 , DPRAM1 被写入 1Mb 数据。
[color=] 仔细分析就会发现到第 3 个缓冲周期时,留给 DPRAM1 读取数据并送到 “ 数据预处理模块 1” 的时间一共是 20ms 。有的工程师困惑于 DPRAM1 的读数时间为什么是 20ms ,这个时间是这样得来的:首先,在在第 2 个缓冲周期向 DPRAM2 写数据的 10ms 内, DPRAM1 可以进行读操作;另外,在第 1 个缓冲周期的第 5ms 起 ( 绝对时间为 5ms 时刻 ) , DPRAM1 就可以一边向 500K 以后的地址写数据,一边从地址 0 读数,到达 10ms 时, DPRAM1 刚好写完了 1Mb 数据,并且读了 500K 数据,这个缓冲时间内 DPRAM1 读了 5ms ;在第 3 个缓冲周期的第 5ms 起 ( 绝对时间为 35ms 时刻 ) ,同理可以一边向 500K 以后的地址写数据一边从地址 0 读数,又读取了 5 个 ms ,所以截止 DPRAM1 第一个周期存入的数据被完全覆盖以前, DPRAM1 最多可以读取 20ms 时间,而所需读取的数据为 1Mb ,所以端口 C1 的数据速率为: 1Mb/20ms=50Mbps 。因此, “ 数据预处理模块 1” 的最低数据吞吐能力也仅仅要求为 50Mbps 。同理, “ 数据预处理模块 2” 的最低数据吞吐能力也仅仅要求为 50Mbps 。换言之,通过乒乓操作, “ 数据预处理模块 ” 的时序压力减轻了,所要求的数据处理速率仅仅为输入数据速率的 1/2 。
虽然各个网站上都是这么解释的,但是个人感觉解释的不怎么样,下面我用我自己的理解给大家解释一下这个例子
先看我给大家画的一个图,虽然画的不怎么样

这里我们只计算缓存模块1的速率
首先看第一个周期10ms,数据流往缓存模块1里面写数据,到第5ms时,预处理模块1开始从缓存模块1里面读数据,到10ms时,缓存模块1写了1M数据,读了5K数据,下面切换到第二个周期,由于在第二个周期的时候预处理模块1还可以从缓存模块1里面读数据,所以到第15ms时,缓存模块1里面的数据被读完

到了第三个时钟周期,也就是从第20ms开始数据流往缓存模块1写数据,到第25ms时,预处理模块开始从缓存模块读数据,直到35ms时才读完,这样我们来算一下,在第一个时钟周期读了5K数据,注意我上面画的时钟周期数,就是那个半圆形的,
在第三个时钟周期读了5k数据,注意每个时钟周期只有5K,另外5K到了下一个时钟周期了,所以我们不考虑,我们只考虑缓存模块1的速率。再看一下时间,从第10ms读完第一个5K,到第30ms读完第2个5k,共用了20ms,读了1M数据,所以速率为1M/20ms=50M/s。
下面再给大家讲一个实例,具体代码我会附在文章后面
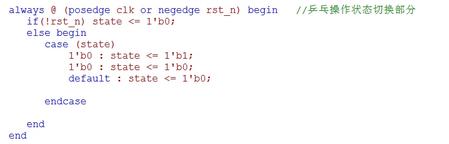
用state来控制乒乓操作的来回切换

根据刚才讲的,控制缓存器的读写,这里只列些部分代码,具体代码请大家在文章后面下载
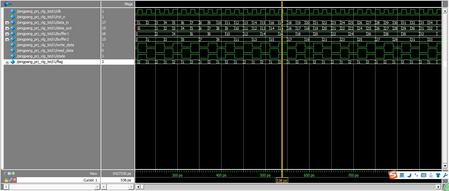
下面附上仿真时序图,我在testbench中将数据设为从0 递增的,可以看到仿真波形中是将奇偶数分开的,证明我们代码是正确的
二、串并转换
串并转换总的来说就是将串行输入信号转换为并行输出,也是用面积换取速度的一种方法,串并转换总的来说比较简单,小墨就只给大家讲一下我自己写的代码吧
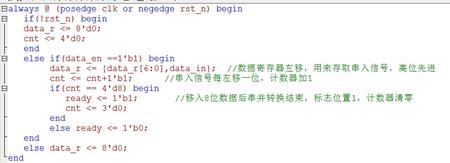
首先要先对串入信号进行采集,加入我们是8位一输出,每进来一位数据,我们便将原数据左移一位,保证数据是高位在前
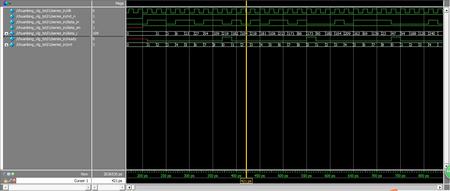
然后再将数据并行输出即可,下面附上仿真波形,我在testbench中给串入信号设为随机数,看仿真图的,第一串信号为1101_1011,一位一位的移进寄存器可以由波形的,分别是1,3,6……所以我们的代码是正确的
三、流水线操作
流水线操作是高速设计中的一种常用手段,如果摸个设计的处理流程分为若干个步骤,而且数据处理是单向流的,也就是没有反馈或者迭代运算,前一个步骤是后一个步骤的输出,我们就可以采用流水线设计的方法来提高设计速率。
举个例子,假如我们要计算A+B+C的值,如果不用流水线操作的话,那么需要先计算A+B的值,再计算A+B+C的值,需要两个时钟周期,如果我用了流水线操作那么我需要在两个always块中分别计算sum1= A+B,sum2= sum1+C,由于两个always块是并行的,输出数据只需要等待一个时钟周期,以后就可以有数据源源不断的输出,就像流水线一样,从而提高系统速率
下面我们来设计一个实例,假如我要采集一系列的32位数据,要对它进行处理,处理方式假如是,先对这个数据进行加16运算,再进行压缩为16位数据运算,再进行减10运算
,最后进行取低8位运算,采用流水线设计的话,输出结果只需要等待几个时钟周期,以后就会有源源不断地数据输出,流程框图如下,代码请在后面下载

我在testbench中定义输入信号是随机的32位信号,分别进行分级处理,每处理完一级要给下一级发使能信号,并把数据送到下一级,例如当第一级使能信号到来时,数据为29,29加16为45,即第一级输出信号,对45取前16位仍为45,45减10为35,35取低8位仍为35,对照波形,证明我们的设计是对的
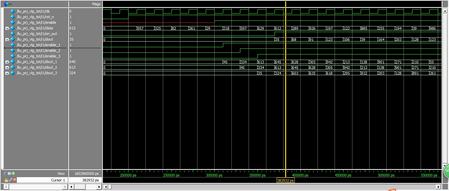
四、跨时钟域信号同步
先来看一张图
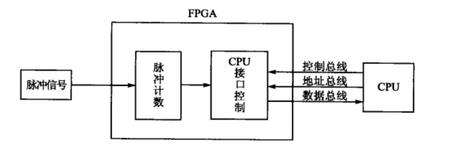
这个图的意思就是,脉冲信号为一个时钟信号,FPGA要对其进行计数,在CPU给FPGA发送读信号的时候,将计数器的值送至CPU的数据总线, 这里就涉及三个时钟信号,一个脉冲信号,一个CPU的读信号,一个FPGA的自身时钟,这三个时钟是不同步的,我们这样想,假如在脉冲计数的时钟,cnt是自加1的,由于三个时钟不同步,CPU的读信号随时都有可能来,加入当cnt自加的时候,也就是cnt = cnt +1,这是对cnt的写状态,突然来一个CPU的读信号,即那么就要把cnt送到数据总线,即data

要解决同步问题,我们可以用FIFO,DPRAM 进行同步,即用其他时钟域对fifo进行写操作,再用FPGA对fifo进行读操作,但要注意是否有数据溢出,还有一种方法就是边沿脉冲检测法,这里我们讲第二种
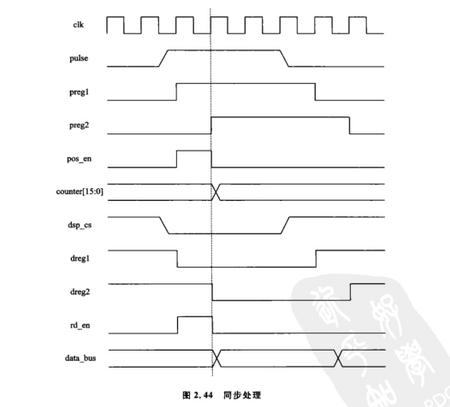
即采用两级寄存器,这两级寄存器均有FPGA的时钟控制,具体操作就是将不同域的信号都先赋值给第一级寄存器,再在另一个always块中把第一级寄存器的值赋给第二级寄存器,如果是信号是高脉冲,那么就把第二级寄存器取反与第一级寄存器相与,便会得到一个高的脉冲采样信号,用这个信号在检测其他域信号的到来,如果是信号是低脉冲,那么就把第一级寄存器取反与第二级寄存器相与,同样得到一个高的脉冲采样信号,用这个信号在检测其他域信号的到来,小墨同学把它记为“上2下1”原则,方便记忆~
具体代码在前面键盘部分已经有所讲解,这里就不副代码了
写了好几个小时,手都敲酸了,还望各位大神多多指教,有什么讲的不对的地方还请指出,一起进步~
之前也看过一些书,也在网上找过一些资料,不过小墨发现大部分都是理论讲解,仅仅是给一个框图就没事了,或者是好几个网站的资料都是一样的,都是复制的一个地方的,仅仅是讲解,没有实例,要不就是某个网站提供源码,但是要注册,还要花什么积分,没有积分还得要钱...很不利于初学者的学习(人与人之间怎么就不能多点信任呢~还要钱...)。所以小墨想写这么一篇文章来介绍一下这4种思想,理论部分书上多得是,我就不过多的解释,主要给大家讲一些实例型的帮大家理解。
一、乒乓操作
乒乓操作主要用于数据流的处理,是用面积换取速度的体现之一,要知道面积与速度的互换贯穿FPGA设计的始终,下面先给一个框图
我先来解释一下乒乓操作的过程:
首先数据需要通过一个2选一数据选择器,在第一个时钟周期将数据缓存到缓存模块1,常用的缓存模块可以是fifo,双口RAM(DPRAM),单口RAM(SPRAM),第二个时钟周期的时候,数据流开始往缓存模块2里面写数据,与此同时,预处理模块会从缓存模块1里面读取数据,到了第三个时钟周期数据流再往缓存模块1里面写数据,与此同时,预处理模块2开始从缓存模块2读取数据,周而复始...这样,输入数据流和输出数据流按节拍来回切换,可以使数据没有停顿的进行传输,使传输速率大大提高。
小墨同学发现,在给这个框图配实例的时候,几乎所有的网站都是这个解释,我用红字标出,个人感觉解释的不怎么样,还有些地方是错的
[color=] 假设端口 A 的输入数据流的速率为 100Mbps ,乒乓操作的缓冲周期是 10ms 。以下分析各个节点端口的数据速率。
[color=] A 端口处输入数据流速率为 100Mbps ,在第 1 个缓冲周期 10ms 内,通过 “ 输入数据选择单元 ” ,从 B1 到达 DPRAM1 。 B1 的数据速率也是 100Mbps , DPRAM1 要在 10ms 内写入 1Mb 数据。同理,在第 2 个 10ms ,数据流被切换到 DPRAM2 ,端口 B2 的数据速率也是 100Mbps , DPRAM2 在第 2 个 10ms 被写入 1Mb 数据。在第 3 个 10ms ,数据流又切换到 DPRAM1 , DPRAM1 被写入 1Mb 数据。
[color=] 仔细分析就会发现到第 3 个缓冲周期时,留给 DPRAM1 读取数据并送到 “ 数据预处理模块 1” 的时间一共是 20ms 。有的工程师困惑于 DPRAM1 的读数时间为什么是 20ms ,这个时间是这样得来的:首先,在在第 2 个缓冲周期向 DPRAM2 写数据的 10ms 内, DPRAM1 可以进行读操作;另外,在第 1 个缓冲周期的第 5ms 起 ( 绝对时间为 5ms 时刻 ) , DPRAM1 就可以一边向 500K 以后的地址写数据,一边从地址 0 读数,到达 10ms 时, DPRAM1 刚好写完了 1Mb 数据,并且读了 500K 数据,这个缓冲时间内 DPRAM1 读了 5ms ;在第 3 个缓冲周期的第 5ms 起 ( 绝对时间为 35ms 时刻 ) ,同理可以一边向 500K 以后的地址写数据一边从地址 0 读数,又读取了 5 个 ms ,所以截止 DPRAM1 第一个周期存入的数据被完全覆盖以前, DPRAM1 最多可以读取 20ms 时间,而所需读取的数据为 1Mb ,所以端口 C1 的数据速率为: 1Mb/20ms=50Mbps 。因此, “ 数据预处理模块 1” 的最低数据吞吐能力也仅仅要求为 50Mbps 。同理, “ 数据预处理模块 2” 的最低数据吞吐能力也仅仅要求为 50Mbps 。换言之,通过乒乓操作, “ 数据预处理模块 ” 的时序压力减轻了,所要求的数据处理速率仅仅为输入数据速率的 1/2 。
虽然各个网站上都是这么解释的,但是个人感觉解释的不怎么样,下面我用我自己的理解给大家解释一下这个例子
先看我给大家画的一个图,虽然画的不怎么样
这里我们只计算缓存模块1的速率
首先看第一个周期10ms,数据流往缓存模块1里面写数据,到第5ms时,预处理模块1开始从缓存模块1里面读数据,到10ms时,缓存模块1写了1M数据,读了5K数据,下面切换到第二个周期,由于在第二个周期的时候预处理模块1还可以从缓存模块1里面读数据,所以到第15ms时,缓存模块1里面的数据被读完
到了第三个时钟周期,也就是从第20ms开始数据流往缓存模块1写数据,到第25ms时,预处理模块开始从缓存模块读数据,直到35ms时才读完,这样我们来算一下,在第一个时钟周期读了5K数据,注意我上面画的时钟周期数,就是那个半圆形的,
在第三个时钟周期读了5k数据,注意每个时钟周期只有5K,另外5K到了下一个时钟周期了,所以我们不考虑,我们只考虑缓存模块1的速率。再看一下时间,从第10ms读完第一个5K,到第30ms读完第2个5k,共用了20ms,读了1M数据,所以速率为1M/20ms=50M/s。
下面再给大家讲一个实例,具体代码我会附在文章后面
用state来控制乒乓操作的来回切换
根据刚才讲的,控制缓存器的读写,这里只列些部分代码,具体代码请大家在文章后面下载
下面附上仿真时序图,我在testbench中将数据设为从0 递增的,可以看到仿真波形中是将奇偶数分开的,证明我们代码是正确的
二、串并转换
串并转换总的来说就是将串行输入信号转换为并行输出,也是用面积换取速度的一种方法,串并转换总的来说比较简单,小墨就只给大家讲一下我自己写的代码吧
首先要先对串入信号进行采集,加入我们是8位一输出,每进来一位数据,我们便将原数据左移一位,保证数据是高位在前
然后再将数据并行输出即可,下面附上仿真波形,我在testbench中给串入信号设为随机数,看仿真图的,第一串信号为1101_1011,一位一位的移进寄存器可以由波形的,分别是1,3,6……所以我们的代码是正确的
三、流水线操作
流水线操作是高速设计中的一种常用手段,如果摸个设计的处理流程分为若干个步骤,而且数据处理是单向流的,也就是没有反馈或者迭代运算,前一个步骤是后一个步骤的输出,我们就可以采用流水线设计的方法来提高设计速率。
举个例子,假如我们要计算A+B+C的值,如果不用流水线操作的话,那么需要先计算A+B的值,再计算A+B+C的值,需要两个时钟周期,如果我用了流水线操作那么我需要在两个always块中分别计算sum1= A+B,sum2= sum1+C,由于两个always块是并行的,输出数据只需要等待一个时钟周期,以后就可以有数据源源不断的输出,就像流水线一样,从而提高系统速率
下面我们来设计一个实例,假如我要采集一系列的32位数据,要对它进行处理,处理方式假如是,先对这个数据进行加16运算,再进行压缩为16位数据运算,再进行减10运算
,最后进行取低8位运算,采用流水线设计的话,输出结果只需要等待几个时钟周期,以后就会有源源不断地数据输出,流程框图如下,代码请在后面下载
我在testbench中定义输入信号是随机的32位信号,分别进行分级处理,每处理完一级要给下一级发使能信号,并把数据送到下一级,例如当第一级使能信号到来时,数据为29,29加16为45,即第一级输出信号,对45取前16位仍为45,45减10为35,35取低8位仍为35,对照波形,证明我们的设计是对的
四、跨时钟域信号同步
先来看一张图
这个图的意思就是,脉冲信号为一个时钟信号,FPGA要对其进行计数,在CPU给FPGA发送读信号的时候,将计数器的值送至CPU的数据总线, 这里就涉及三个时钟信号,一个脉冲信号,一个CPU的读信号,一个FPGA的自身时钟,这三个时钟是不同步的,我们这样想,假如在脉冲计数的时钟,cnt是自加1的,由于三个时钟不同步,CPU的读信号随时都有可能来,加入当cnt自加的时候,也就是cnt = cnt +1,这是对cnt的写状态,突然来一个CPU的读信号,即那么就要把cnt送到数据总线,即data
要解决同步问题,我们可以用FIFO,DPRAM 进行同步,即用其他时钟域对fifo进行写操作,再用FPGA对fifo进行读操作,但要注意是否有数据溢出,还有一种方法就是边沿脉冲检测法,这里我们讲第二种
即采用两级寄存器,这两级寄存器均有FPGA的时钟控制,具体操作就是将不同域的信号都先赋值给第一级寄存器,再在另一个always块中把第一级寄存器的值赋给第二级寄存器,如果是信号是高脉冲,那么就把第二级寄存器取反与第一级寄存器相与,便会得到一个高的脉冲采样信号,用这个信号在检测其他域信号的到来,如果是信号是低脉冲,那么就把第一级寄存器取反与第二级寄存器相与,同样得到一个高的脉冲采样信号,用这个信号在检测其他域信号的到来,小墨同学把它记为“上2下1”原则,方便记忆~
具体代码在前面键盘部分已经有所讲解,这里就不副代码了
写了好几个小时,手都敲酸了,还望各位大神多多指教,有什么讲的不对的地方还请指出,一起进步~
- 基于FPGA的片上系统的无线保密通信终端(02-16)
- 基于Virtex-5 FPGA设计Gbps无线通信基站(05-12)
- 基于FPGA的DVI/HDMI接口实现(05-13)
- 基于ARM的嵌入式系统中从串配置FPGA的实现(06-09)
- 采用EEPROM对大容量FPGA芯片数据实现串行加载(03-18)
- 赛灵思:可编程逻辑不仅已是大势所趋,而且势不可挡(07-24)