使用赛灵思Vivado设计套件的九大理由
时间:10-24
来源:互联网
点击:
理由二:Vivado以可预测的结果提供稳健可靠的性能和低功耗
出于纳米级IC设计的物理原因,互联已经成为28nm及更高工艺节点的可编程逻辑器件架构的性能瓶颈。Vivado设计套件采用先进的布局布线算法,可突破该性能瓶颈,而且点击鼠标即可得到高性能结果。
Vivado设计套件的分析型布局布线算法能够同步优化包括时序、互联使用和走线长度在内的多重变量,提供可预测的设计收敛。同时,Vivado的实现引擎可保证在逻辑利用率高的大型器件上得到的结果和在器件利用率较低的设计上得到的结果一样优异。此外,在系统设计规模随着系统功能的增加而逐步增大的情况下,Vivado既能保持高性能结果,还能提高各次运行结果间的一致性。
如图2所示,与同类竞争工具相比,Vivado设计套件可随着利用率的提升提供更出色的性能,同时还能处理更大规模的设计。
注:如图2所示,同类竞争工具的结果的平均变动要比使用Vivado设计套件得到的结果大四倍。另外,值得注意的是同类竞争解决方案在填满器件时,可用性能下降了一半。与此形成鲜明对比的是,Vivado设计套件在受测的不同设计上得到的结果一致,性能保持稳定。最后还需要注意是同类竞争解决方案不能处理Vivado设计套件能够成功处理的大型系统。同类竞争解决方案很快就不堪重负。

图2:以复制次数为标准的性能对比
Vivado降低系统功耗
Vivado设计套件提供了业界一流的系统功耗分析与优化工具。从架构或器件选择阶段开始,设计人员就可以运用准确且易用性无与伦比的Xilinx Power Estimator(XPE,赛灵思功耗评估器)电子数据表来确定系统功耗。设计人员不仅能够通过XPE的快速 评估(Quick Estimate)和IP向导轻松入门,而且还能够简单并排比较多种实现方案,帮助设计团队微调设置,以便地为各种场景精确建模。
当设计进入编译阶段,Vivado设计套件继续提供准确的功耗分析和估算。Vivado设计套件开箱即用,能够在不给系统设计的时序造成负面影响的情况下自动降低设计的功耗。如果用户还需要进一步降低功耗,可以使用Vivado设计套件独有功能,充分利用赛灵思7系列精细粒度时钟门控技术,进一步降低整个系统设计或部分设计的功耗。
这种Vivado设计套件实现的智能时钟门控优化技术能够平均降低动态功耗18%,如图3所示。
Vivado设计套件提供了一系列无与伦比功能与特性,可帮助用户轻松完成对设计的分析工作。用户可以甄别出功耗最大的模块,从而明确从哪些模块切入,高效而明显降低系统功耗。所有这些功能都内置在通用Vivado集成设计环境(IDE)中,所以设计团队仅借助一款统一的工具套件,就可一次性最小化系统功耗。
系统功耗是设计大多数产品时应考虑的一个重要因素,Vivado设计套件提供的领先一代设计工具是对赛灵思All Programmable器件的有力补充和完善。
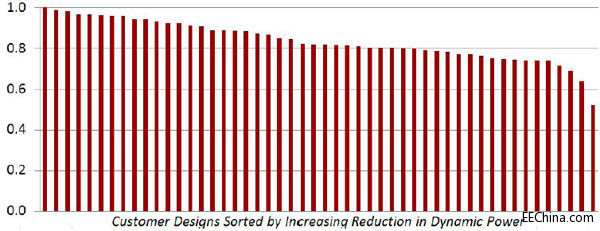
图3:运用智能时钟门控优化实现的动态功耗比率(按动态功耗降幅分类)
理由三:Vivado设计套件提供了无与伦比的运行时间和存储器利用率
从设计人员生产力考虑,设计工具应能够快速运行,最好是快到每天能够完成多次编译,这样设计团队就能够迅速得到最终设计。从一开始Vivado设计套件就是为高速运行设计的,比同类竞争的可编程逻辑设计工具的速度明显要快得多。
同样以之前讨论过的OpenCores以太网MAC模块设计为例。图4说明,随着实例数量的增加,Vivado设计套件的运行时间比竞争对手的软件快三倍。此外,数据还表明,Vivado的运行时间的增减可以预测,即运行时间只单调地随设计规模增减。与此形成鲜明对比的是,同类竞争软件的运行时间无规律性。例如94个实例的设计完成的速度比使用84个实例的设计快。
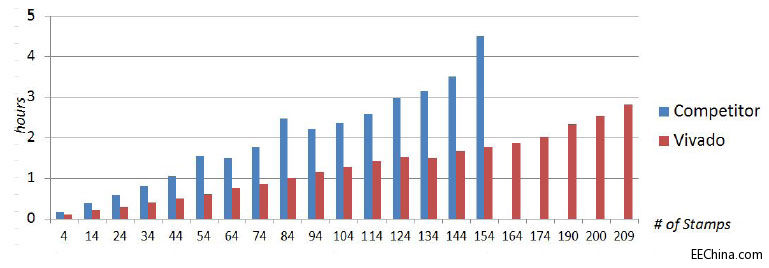
图4:运行时间比较
Vivado内存占用更小
Vivado设计套件采用先进高效的数据模型和结构,内存占用极小且明显低于同类竞争解决方案的内存占用。此处仍以OpenCores以太网MAC模块为例。要成功运行规模最大的设计(154个实例),竞争软件需要占用16GB的RAM,相比之下运行同样规模大小的设计,Vivado设计套件占用的内存要小三分之二(见图5)。内存占用减少意味着Vivado设计套件拥有明显的生产力优势,因为设计人员在编译较大型系统设计时不会耗尽内存。
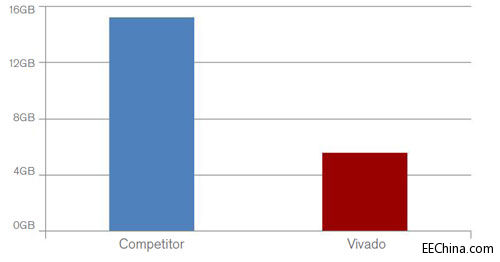
图5:内存占用
加快系统集成
理由四:使用Vivado高层次综合生成基于C语言的IP
如今的无线、医疗、军用和消费类应用均比以往更加尖端,使用的算法也比以往更加复杂。业界算法开发的金标准就是采用C、C++和SystemC高级编程语言。过去设计流程中需要经过一个缓慢且容易出错的步骤来将用C、C++或SystemC语言编写的算法转换为适合于综合的Verilog或VHDL硬件描述。而现在Vivado设计套件系统版本中提供的Vivado高层次综合功能可轻松地自动完成这一步骤。
您以往可能听说过C语言级硬件综合。不管您听说过什么,C语言级算法综合已成为系统级设计的捷径。当前有超过400名用户正在成功利用Vivado高层次综合(HLS)技术开发符合C、C++和SystemC语言规范的赛灵思All Programmable器件用IP硬核。
Vivado HLS通过下列功能,让系统和设计架构师走上IP硬核开发的捷径:
出于纳米级IC设计的物理原因,互联已经成为28nm及更高工艺节点的可编程逻辑器件架构的性能瓶颈。Vivado设计套件采用先进的布局布线算法,可突破该性能瓶颈,而且点击鼠标即可得到高性能结果。
Vivado设计套件的分析型布局布线算法能够同步优化包括时序、互联使用和走线长度在内的多重变量,提供可预测的设计收敛。同时,Vivado的实现引擎可保证在逻辑利用率高的大型器件上得到的结果和在器件利用率较低的设计上得到的结果一样优异。此外,在系统设计规模随着系统功能的增加而逐步增大的情况下,Vivado既能保持高性能结果,还能提高各次运行结果间的一致性。
如图2所示,与同类竞争工具相比,Vivado设计套件可随着利用率的提升提供更出色的性能,同时还能处理更大规模的设计。
注:如图2所示,同类竞争工具的结果的平均变动要比使用Vivado设计套件得到的结果大四倍。另外,值得注意的是同类竞争解决方案在填满器件时,可用性能下降了一半。与此形成鲜明对比的是,Vivado设计套件在受测的不同设计上得到的结果一致,性能保持稳定。最后还需要注意是同类竞争解决方案不能处理Vivado设计套件能够成功处理的大型系统。同类竞争解决方案很快就不堪重负。
图2:以复制次数为标准的性能对比
Vivado降低系统功耗
Vivado设计套件提供了业界一流的系统功耗分析与优化工具。从架构或器件选择阶段开始,设计人员就可以运用准确且易用性无与伦比的Xilinx Power Estimator(XPE,赛灵思功耗评估器)电子数据表来确定系统功耗。设计人员不仅能够通过XPE的快速 评估(Quick Estimate)和IP向导轻松入门,而且还能够简单并排比较多种实现方案,帮助设计团队微调设置,以便地为各种场景精确建模。
当设计进入编译阶段,Vivado设计套件继续提供准确的功耗分析和估算。Vivado设计套件开箱即用,能够在不给系统设计的时序造成负面影响的情况下自动降低设计的功耗。如果用户还需要进一步降低功耗,可以使用Vivado设计套件独有功能,充分利用赛灵思7系列精细粒度时钟门控技术,进一步降低整个系统设计或部分设计的功耗。
这种Vivado设计套件实现的智能时钟门控优化技术能够平均降低动态功耗18%,如图3所示。
Vivado设计套件提供了一系列无与伦比功能与特性,可帮助用户轻松完成对设计的分析工作。用户可以甄别出功耗最大的模块,从而明确从哪些模块切入,高效而明显降低系统功耗。所有这些功能都内置在通用Vivado集成设计环境(IDE)中,所以设计团队仅借助一款统一的工具套件,就可一次性最小化系统功耗。
系统功耗是设计大多数产品时应考虑的一个重要因素,Vivado设计套件提供的领先一代设计工具是对赛灵思All Programmable器件的有力补充和完善。
图3:运用智能时钟门控优化实现的动态功耗比率(按动态功耗降幅分类)
理由三:Vivado设计套件提供了无与伦比的运行时间和存储器利用率
从设计人员生产力考虑,设计工具应能够快速运行,最好是快到每天能够完成多次编译,这样设计团队就能够迅速得到最终设计。从一开始Vivado设计套件就是为高速运行设计的,比同类竞争的可编程逻辑设计工具的速度明显要快得多。
同样以之前讨论过的OpenCores以太网MAC模块设计为例。图4说明,随着实例数量的增加,Vivado设计套件的运行时间比竞争对手的软件快三倍。此外,数据还表明,Vivado的运行时间的增减可以预测,即运行时间只单调地随设计规模增减。与此形成鲜明对比的是,同类竞争软件的运行时间无规律性。例如94个实例的设计完成的速度比使用84个实例的设计快。
图4:运行时间比较
Vivado内存占用更小
Vivado设计套件采用先进高效的数据模型和结构,内存占用极小且明显低于同类竞争解决方案的内存占用。此处仍以OpenCores以太网MAC模块为例。要成功运行规模最大的设计(154个实例),竞争软件需要占用16GB的RAM,相比之下运行同样规模大小的设计,Vivado设计套件占用的内存要小三分之二(见图5)。内存占用减少意味着Vivado设计套件拥有明显的生产力优势,因为设计人员在编译较大型系统设计时不会耗尽内存。
图5:内存占用
加快系统集成
理由四:使用Vivado高层次综合生成基于C语言的IP
如今的无线、医疗、军用和消费类应用均比以往更加尖端,使用的算法也比以往更加复杂。业界算法开发的金标准就是采用C、C++和SystemC高级编程语言。过去设计流程中需要经过一个缓慢且容易出错的步骤来将用C、C++或SystemC语言编写的算法转换为适合于综合的Verilog或VHDL硬件描述。而现在Vivado设计套件系统版本中提供的Vivado高层次综合功能可轻松地自动完成这一步骤。
您以往可能听说过C语言级硬件综合。不管您听说过什么,C语言级算法综合已成为系统级设计的捷径。当前有超过400名用户正在成功利用Vivado高层次综合(HLS)技术开发符合C、C++和SystemC语言规范的赛灵思All Programmable器件用IP硬核。
Vivado HLS通过下列功能,让系统和设计架构师走上IP硬核开发的捷径:
赛灵思 ARM 自动化 SoC FPGA Xilinx 电子 C语言 Verilog VHDL 仿真 DSP 显示器 机器视觉 滤波器 嵌入式 收发器 相关文章:
- 赛灵思:可编程逻辑不仅已是大势所趋,而且势不可挡(07-24)
- FPGA可帮助搜索引擎降低功耗和碳排放(09-12)
- 基于Spartan-3A DSP的安全视频分析(05-01)
- 赛灵思新版视频入门套件加快视频开发速度(05-29)
- 赛灵思“授之以渔”理论:危机中如何巧降成本(06-04)
- 赛灵思详解新近推出的FPGA领域设计平台(12-16)