FPGA是实现绿色搜索技术的关键
时间:10-18
来源:互联网
点击:
- 高级 FPGA 编程
Mitrionics SDK 可提供 Mitrion-C 作为高级语言,专用于满足在 FPGA 上快速开发应用之需。不过,作为后缀的 C 有些误导作用。尽管这种语言采用了 C 风格的语法,但实际上是一种遵循函数编程风格的单赋值数据流语言。Mitrion-C 原生支持广泛(矢量)而深入(管道)的并行功能,因而非常适用于处理数据流的算法,例如过滤以及其他众多类型的文本和数据挖掘算法等。
Mitrion-C 还提供了一种流数据类型,可配合 foreach looping 构造实现流水线操作;此外,还提供矢量数据类型以支持数据并行工作,以及支持顺序列表的列表数据类型。具体而言,用户可过滤foreach loop 的流输出,生成较小的流,如以下 Mitrion-C 代码示例所示。此外,程序人员还能用元组结构 (tuple construct) 创建功能强大的数据类型。最后还有一个需要指出的特性是,该语言能支持可变宽度整数和浮点数。

为了在 FPGA 上高效实施评分操作,我们必须解决的关键问题是高效查询配置文件以及文档流的高效 I/O 流。
对于文档中的每个词,应用都要查询配置文件中相应的词并获得词加权 (term weight)。由于大多数查询都找不到结果(即大多数文档的大多数词不会出现在配置文件中),因此必须首先丢弃否定词。鉴于此,我们在 FPGA Block RAM 中采用了 Bloom 过滤器 。BRAM 的内部带宽越高,拒绝否定词的结果就越快。由于需要查询,因此配置文件必须作为某种散列函数进行实施。不过,由于配置文件的大小不能提前知道,因而我们不可能构建出完美的散列函数。不完美的散列函数会出现冲突问题,进而降低性能。
为了解决这一问题,我们采用了分档方案,即将外部 SRAM 分区为 bin,每个 bin 都可包含固定数量的配置文件词。Bin 的大小决定了可处理的冲突数。如需给 bin 分配配置文件词,只需将词 ID 的较下部分作为存储器地址,从而避免了实际的散列操作。
让 SRAM 存储器容量设定为 NM 配置文件词。词 ID 是一个无符号的整数,其范围取决于词汇量,就我们的例子而言约为 400 万个词,需要 24 位。词加权为 8.32 定点数,因而配置文件词需要 64 位。RC100 上的 SRAM 包括 4 个 16 MB 存储库,因此 NM="223"。Bins 的数量 nb="NM/b" 和 bin 地址用词 ID“t”进行计算,即 (t&(nb-1)).b。
Bin 的占用概率 x 由组合决定,置换决定 bin 的数量 nb 和描述词的数量 np。这样,我们就能计算 bin 溢出的概率就是 bin 大小的函数(即 bin 的数量),即 NM="b".nb。bin 尺寸越大,查询就越慢,但是,由于 SRAM 存储库包括 4 个独立的 64 位可寻址双端口 SRAM,我们实际上可以并行查询四个配置文件词。因此,相对性能会降低 1/ceil(b/4)。我们的分析结果显示,即便对最大型的配置文件来说(16K,我们研究所用的最大配置文件为 12K,不过通常配置文件比这都要小得多),b=4时(最佳性能),bin 溢出概率为 10-9。换言之,描述词被丢弃的概率不到 10 亿分之一。应注意的是,由于我们假定词汇量无限大,因而这一估算还是保守数字。
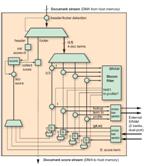
图 3 —— 过滤应用的 FPGA 实施示意图
通过将文档表述为“词袋”,文档流就是文档 ID、文档词对组 (document term pair set) 等对列表。从物理上说,FPGA 以每秒 1.6 GB 的速度从 NUMAlin 接受 128 位字流。因此,文档流必须在字流上编码。可将文档词对 di =(ti,fi) 编码为 32 位:24 位用于词 ID(支持 1,600 万个词的词汇库),8 位用于词的频率。这样,我们就能将 4 个对组合到 128 位字中。要标示文档的起点与终点,我们需要插入包含文档 ID(64 位)和标志符(64 位)的报头与脚注字 (footer word)。
如上所述采用查询表架构和文档流格式,实际的查询和评分系统(图 3)会非常直接。我们只需扫描输入流以检查报头和脚注字即可。报头字将文档得分设为 0,而脚注字则收集并输出文档得分。对于文档中的每四个配置文件词,Bloom 过滤器首先丢弃否定词结果,再从 SRAM 读取四个配置文件词。并行计算并添加(图 4)每个词的得分。实际上,四分之三的配置文件词 ID 不会匹配于文档词 ID;只对第四个进行实际计算。将文档中所有词的得分进行累加,最后得分流在输出到主机存储器之前与限值进行比较过滤。
主机—FPGA 接口将文档流从存储器缓冲器中传输至 FPGA,并将得分流返回至客户端中。一旦从客户端接收到配置文档 ID 表,子进程即从主进程中分叉出来,以构建实际的配置文件,将其载入 SRAM 并在 FPGA 上运行算法。每个子进程都会产生一个独立的输出线程,以对从 FPGA 获得的得分进行缓冲,并通过 TCP/IP 将这些得分传输到客户端,从而使用网络对得分流进行多路复用。若没有该线程,网络吞吐量的波动就会降低系统性能。这种主机接口架构的主要优势在于,它具有很高的可扩展性,能轻松满足大量 FPGA 的需求。
FPGA 电子 赛灵思 总线 Linux VHDL 仿真 电路 相关文章:
- 基于FPGA的片上系统的无线保密通信终端(02-16)
- 基于Virtex-5 FPGA设计Gbps无线通信基站(05-12)
- 基于FPGA的DVI/HDMI接口实现(05-13)
- 基于ARM的嵌入式系统中从串配置FPGA的实现(06-09)
- 采用EEPROM对大容量FPGA芯片数据实现串行加载(03-18)
- 赛灵思:可编程逻辑不仅已是大势所趋,而且势不可挡(07-24)