WCDMA速率适配算法的FPGA实现
时间:07-11
来源:互联网
点击:
图3 下行未编码和卷积编码以及重复的Turbo编码的TrCH的速率匹配
另外,协议给出的确定参数的算法依编码方式及链路的不同而不同。也就是说,Turbo编码与卷积编码、下行链路与上行链路在确定适配参数的算法上有区别。具体的确定算法可以参考3G相应的协议。
速率适配的FPGA实现
通过对编码复接的方案研究发现,直接根据协议流程对数据流各个步骤(一共大约11个步骤)直接进行处理将会大大增加系统复杂度,这样每个步骤之间都需对数据进行缓存,而移动环境下系统支持的最高速率可达384Kbps,对于TTI=20ms的业务,平均每步需要的缓存为7.68K,所需要的总存储量是巨大的。而且这中间,数据流频繁的写入读出所导致的处理时延也是难以忍受的。因此,如果将某些步骤合并起来,就能减少不必要的数据存取工作,从而节省存储量,缩短处理延时。
上行链路的速率匹配按10ms数据帧为单位进行,而下行链路则是以TTI为单位针对一个无线帧的数据比特进行的。虽然算法上一致,但是考虑到上下行各自的步骤合并情况,在实际处理上还是有很大区别的。下面以下行144Kb/s速率适配为例介绍一下其FPGA的实现方法。
144Kb/s速率适配过程大致分为两个模块:凿图样产生模块和保留比特搬移转换模块。在实现过程中,用到的存储资源是两个RAM—一个用来存“凿”图样、另一个用来存原来的数据,两个DCFIFO(双时钟FIFO)用来存比特收集后的两帧数据。
凿孔图样产生模块
由于144Kb/s业务信道编码用的是Turbo编码,凿孔时只针对两个分量编码器输出的校验比特,因此需先进行比特分离再分块进行凿孔操作(系统比特块自动保留不进行凿孔操作)。我们采用了一种凿孔图样控制方式,所有待速率适配比特都对应一个P比特,P=1表示凿去,P=0表示保留,以此种方式产生凿孔图样来控制保留比特的搬移。具体实现框图如图4所示。主要硬件结构包括一个加法器、一个减法器、一个数值比较器、一个计数器和一个选通控制模块及参数初始化模块。
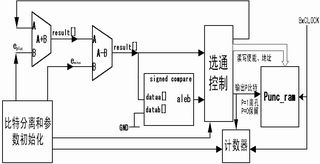
图4 凿孔图样产生
该结构工作过程如下:首先,比特分离和参数初始化模块主要完成模块计数和eini、eminus、eplus等参数的初始化设置。
在减法器端,当前误差值e减去eminus,该数值同时送给数值比较器和选通控制模块。减法器的输出结果和0值作比较,如果结果小于零则记P比特为1;如果结果大于零则记P比特为0,同时将减法器的输出结构作为当前加法器的A端输入值。P比特则在选通控制模块产生的读写使能、地址信号线的驱动下写入Punc_ram。另外用一个计数器来对比特数进行记录,以控制整个流程的结束时刻。系统时钟为8倍码片时钟,计数器和Punc_ram都采用同步控制,加法器、减法器及比较器都不采用同步时钟延时。
保留比特搬移转换模块
凿图样产生以后,接下来的操作就是保留比特的搬移和转换,并进行第一次交织和无线帧分段。按照3GPP协议,对于TTI=20ms的144Kb/s业务,其交织模式是<0,1>,亦即顺序输出。
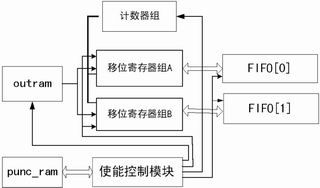
图5 保留比特搬移转换
实现的流程图如图5。假定TURBO编码后待的比特流存在out_ram中,这里进行的操作关键是凿孔图样的读出和out_ram的读出应该是同步一致进行(在同一个时钟上升沿开始),用Punc_ram的输出来作为积攒比特的使能信号。用移位寄存器组和计数器实现比特积攒,每等到满16bit时,就进行串并转换,同时产生一个fifo写使能脉冲,把一个字的内容写入fifo;等到满一帧(复接前的数据帧)的时候,转向对下一个fifo进行写操作。到一个数据帧4205bit结束时,积攒比特不满16的补零表示,串并转换为一个字写入fifo。
资源使用和时延分析
按照上面的实现方式,主要占用的是存储资源,现代FPGA中的ESB(嵌入式系统块)可以很容易地实现各种类型的存储模块,包括双端口RAM、ROM、FIFO及CAM块。下面主要进行的是时延分析。
按照上面的流程可以大致估算一个比特从“凿孔”图样产生到比特搬移完成所用的时间。所选工作时钟速率为8倍码片速率3.84MHz,一个时钟周期约为32.4ns。凿孔图样模块中的加法器、减法器、选通控制大概需要3个时钟周期,9516个凿孔图样的产生需要大致925ns;保留比特搬移模块主要是数据比特的直接搬移,对于最后一个比特而言,假定它是保留比特,从搬移开始到最终写入FIFO,经过了大致9516+16=9532个时钟周期,耗时大约308ns。对整个流程用MAXPUSII仿真,总共耗时1.336ms,考虑到中间的缓冲控制和使能控制延迟,仿真结果和计算值大致吻合。对于TTI=20ms的业务,完全满足处理要求。
- 基于FPGA的片上系统的无线保密通信终端(02-16)
- 基于Virtex-5 FPGA设计Gbps无线通信基站(05-12)
- 基于FPGA的DVI/HDMI接口实现(05-13)
- 基于ARM的嵌入式系统中从串配置FPGA的实现(06-09)
- 采用EEPROM对大容量FPGA芯片数据实现串行加载(03-18)
- 赛灵思:可编程逻辑不仅已是大势所趋,而且势不可挡(07-24)