AI进入爆发期,千亿芯片市场空间
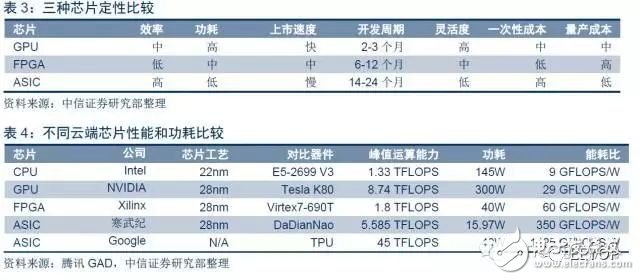
GPU不断适应AI的进化路径,未来进化方向:从"开环"到"专精"。目前云端应用范围最广、效率最高的AI芯片仍是GPU。但AI芯片并非只有GPU一种路径,ASIC与FPGA相关厂商相继推出针对人工智能计算的芯片。谷歌推出ASIC芯片TPU2代,性能达到45 TFLOPS(一个TFLOPS等于每秒万亿次的浮点运算),而功耗仅仅40W。国内公司寒武纪推出的ASIC芯片DaDianNao性能达到5.585 TFLOPS,功耗仅为15.97W。众多专属ASIC芯片的推出,可能威胁到未来GPU的霸主地位。英伟达显然意识到这一点,不断推动技术创新,推出性能更加强劲、更适合AI运算的产品,不断对其GPU进行深度优化,向更专精AI运算方向努力。2017年5月,英伟达发布旗舰芯片Tesla V100,对比上一代TeslaP100,最大变化就是增加了与深度学习高度相关的Tensor单元,Tensor性能可以达到120TFLOPS。GPU不断适应AI的进化路径,从从"开环通用"到"AI专精"方向进化,性能不断提高,加之生态环境的先发优势,预计未来2~3年,GPU仍是人工智能云端市场最重要的组成部分。

云端ASIC:以TPU为代表,性能取胜,争夺未来AI制高点
2.1发展趋势:ASIC—未来人工智能专属核心芯片
ASIC目前在AI方向上的发展尚处于早期。ASIC全称专用集成电路,是应针对特定场景、需求、算法而设计的专用芯片。目前人工智能类 ASIC 的发展仍处于早期。根本原因是目前人工智能算法尚未定型,迭代较快,而ASIC设计一旦设计制造完成后功能就基本固定,相对GPU、FPGA而言不够灵活,且开发周期长、初期成本高。人工智能ASIC芯片公司需要既具备人工智能算法框架,又擅长芯片研发,进入门槛较高。
ASIC性能、能耗和大规模量产成本均显著优于GPU和FPGA,是未来云端人工智能重要发展方向。针对特定云端应用,作为全定制设计的ASIC芯片,性能和能耗都要优于FPGA 和 GPU。谷歌最近研发出人工智能ASIC TPU,和传统的GPU相比性能提升15倍,更是CPU 浮点性能的30倍。由于ASIC兼具性能和功耗双重优点,加之大规模量产条件下ASIC单片成本大幅下降,我们判断其定会成为人工智能未来的核心芯片。
2.2生态格局:谷歌TPU为目前自用最强ASIC,期待生态完善后外供
TPU:目前谷歌自用最强ASIC芯片,期待生态完善后外供。随着 AlphaGo 横扫人类顶尖棋手,谷歌在AlphaGo 中应用的 ASIC 芯片TPU受到业界热捧,谷歌于 2016年 Google I/O 大会上正式介绍第一代 TPU 产品,在今年5 月的开发者 I/O 大会上, Google 正式公布了第二代 TPU,又称为 Cloud TPU,其最大的特色在于相比初代TPU, 它既可以用于训练神经网络,又可以用于推理,这既为推理阶段进行了优化,也为训练阶段进行了优化。在性能方面,第二代 TPU 可以达到 45 TFLOPs 的浮点性能。和传统的 GPU 相比提升 15 倍,更是CPU浮点性能的30倍。生态方面,目前TPU仅支持自身的开源 TensorFlow 机器学习框架和生态系统。这和生态系统非常完善的GPU相比有一定的不足。不过谷歌也意识到了这个不足,为了弥补生态上面的不足,谷歌提出了TensorFlow Research Cloud计划,为愿意分享自己工作成果的研究人员免费提供1000个Cloud TPU。相信随着TPU生态的不断完善,性能更加强悍的TPU将成为云端人工智能的未来。

3.云端FGPA:云端的有效补充,低延时场景具备充分优势
3.1 会变形的万能芯片,未来云端AI的最好补充
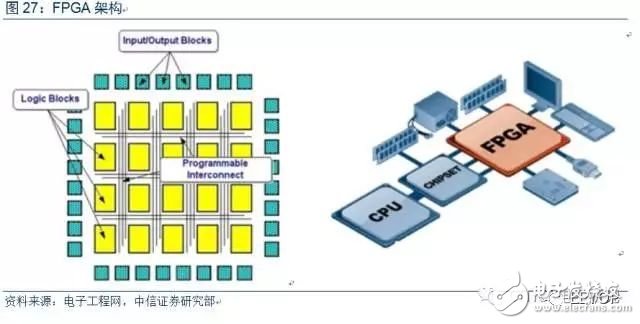
FPGA可编程,灵活性高。FPGA(Field-Programmable Gate Array),即现场可编程门阵列,它是在PAL、CPLD等可编程器件的基础上进一步发展的产物。FPGA内部包含大量重复的IOB(输入输出模块)、CLB(可配置逻辑块,内部是基本的逻辑门电路,与门、或门等)和布线信道等基本单元。FPGA在出厂时是"万能芯片",用户可根据自身需求,用硬件描述语言(HDL)对FPGA的硬件电路进行设计;每完成一次烧录,FPGA内部的硬件电路就有了确定的连接方式,具有了一定的功能。FPGA可随意定制内部逻辑的阵列,并且可以在用户现场进行即时编程,以修改内部的硬件逻辑,从而实现任意逻辑功能。
3.2 核心优势:在云端算法性能高、功耗和延迟低
FPGA无指令、无共享内存,并行计算效率高。CPU、GPU都属于冯·诺依曼结构,需要指令译码执行、共享内存,是传统意义上的"软件编程"。而FPGA每个逻辑单元的功能在重编程(烧写)时就已经确定,不需要指令,属于"硬件编程";FPGA每个逻辑单元与周围逻辑单元的连接在重编程时就已经确定,也不需要通过共享内存来通信。FPGA利用硬件并行的优势,打破顺序执行的模式,因此在每个时钟周期
- 解密英伟达Tesla P100、GP100、DRIVE PX2平台(04-26)
- 人工智能处理器三强Intel/NVIDIA/AMD谁称霸?(07-23)
- 2016年人工智能与深度学习领域的十大收购(07-26)
- 人工智能实现的流派 FPGA vs. ASIC看好谁?(08-27)
- IBM沃森能否在人工智能领域突破重围?(09-19)
- 英特尔与高通将在汽车芯片市场再次对决(上)(10-03)