漫谈游戏的深度学习算法,从FPS和RTS角度分析
Q 学习 [31] 的双 DQN 通过学习两个价值网络降低观测到的过高估计值,两个价值网络在更新时互为目标网络 [113]。
Dueling DQN 使用的网络在卷积层后可以分成两个流,分别估计状态值 V π (s) 和动作优势(action-advantage)Aπ (s, a),使 Qπ (s, a) = V π (s) + Aπ (s, a) [116]。Dueling DQN 优于双 DQN,且能够连接优先经验回放。
本节还描述了 Advantage Actor-Critic (A3C) 算法、使用渐进神经网络的 A3C 算法 [88]、非监督强化和辅助学习(UNsupervised REinforcement and Auxiliary Learning,UNREAL)算法、进化策略(Evolution Strategies,ES)等算法。
B. Montezuma‘s Revenge(略)
C. 竞速游戏
Chen et al 认为基于视觉的自动驾驶通常存在两种范式 [15]:(1)直接学习将图像映射到动作的端到端系统(行为反射);(2)分析传感器数据,制定明智决策的系统(介导感知)。
策略梯度方法,如 actor-critic [17] 和确定性策略梯度(Deterministic Policy Gradient,DPG)[98],可以在高维、持续的动作空间中学习策略。深度确定性策略梯度是一种实现回放记忆和独立目标网络的策略梯度方法,二者都极大提升了 DQN。深度确定性策略梯度方法曾用于利用图像训练 TORCS 的端到端 CNN 网络 [64]。
前面提到的 A3C 方法也被应用于竞速游戏 TORCS,仅使用像素作为输入 [69]。
D. 第一人称射击游戏
使用同步定位与地图构建(Simultaneous Localization and Mapping,SLAM)从屏幕和深度缓冲区获取位置推断和物体映射,这二者也能改善 DQN 在《毁灭战士》游戏中的效果 [8]。
死亡竞赛的冠军使用了直接未来预测(Direct Future Prediction,DFP)方法,该方法的效果优于 DQN 和 A3C [18]。DFP 使用的架构有三个流:一个用于屏幕像素,一个用于描述智能体当前状态的低维评估,一个用于描述智能体的目标,即优先评估的线性结合。
3D 环境中的导航是 FPS 游戏所需的一个重要技巧,并且已经被广泛研究。CNN+LSTM 网络使用 A3C 训练,A3C 用预测像素深度和环闭合的额外输出扩展而成,显示出显著改善 [68]。
内在好奇心单元(Intrinsic Curiosity Module,ICM)包括多个神经网络,在每个时间步内基于智能体无法预测动作结果来计算内在奖励。
E. 开放世界游戏
分层深度强化学习网络(Hierarchical Deep Reinforcement Learning Network,H-DRLN)架构实现终身学习框架,该框架能够在游戏《我的世界》的简单任务中迁移知识,比如导航、道具收集和布局任务 [108]。H-DRLN 使用一个变种策略振荡 [87] 来保留学得的知识,并将其封装进整个网络。
F. 即时战略游戏
即时战略(RTS)游戏的环境更加复杂,玩家必须在部分可观测的地图中实时同步控制多个智能体。
即时战略主要有以下几种方法:
独立 Q 学习(IQL)将多智能体强化学习问题简化,智能体学习一种策略,可以独立控制单元,而将其他智能体当作环境的一部分 [107]。
多智能体双向协调网络(BiCNet)基于双向 RNN 实现一种向量化的 actor-critic 框架,其中一个向度适用于每一个智能体,其输出为一系列操作 [82]。
Counterfactual multi-agent(COMA)策略梯度是一种 actor-critic 方法,该方法具备一个中心化的 critic 和多个去中心化的 actor,用 critic 网络计算出的反事实基线(counterfactual baseline)来解决多智能体信度分配的问题 [21]。
G. Physics Games(略)
H. 基于文本的游戏
这类游戏中的状态和操作都以文本的形式呈现,是一种特殊的电子游戏类型。研究者专门设计了一种叫作 LSTM-DQN [74] 的网络架构来玩这类游戏。使用 LSTM 网络可以把文本从世界状态转换成向量表征,评估所有可能的状态动作对(state-action pair)的 Q 值。
开放性挑战
深度学习,特别是深度强化学习方法,在电子游戏中取得了卓越的成果,但是仍然存在大量重要的开放性挑战。本节我们将对此进行概述。
A. 通用电子游戏
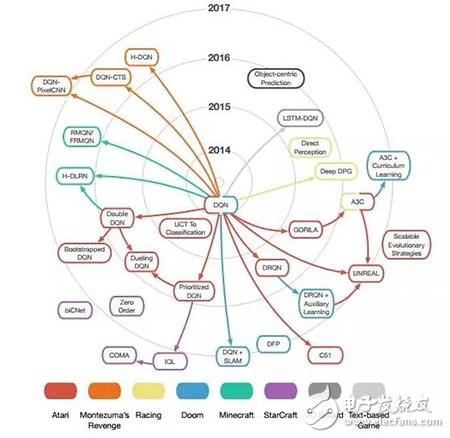
图 3. 本文讨论的深度学习技术的影响力图
图 3中每一个节点代表一个算法,颜色代表游戏基准,与中心的距离代表原始论文在 arXiv 上的发表时间,箭头表示技术之间的关系,每一个节点指向所有使用或修改过该技术的节点。本论文未讨论的影响力则不在图中出现。
B. 稀疏奖励的游戏
C. 多智能体学习
D. 计算资源
E. 深度学习方法在游戏产业中的应用情况
F. 游戏开发交互工具
G.
- 机器学习算法盘点:人工神经网络、深度学习(07-02)
- 2016年人工智能与深度学习领域的十大收购(07-26)
- AI/机器学习/深度学习三者的区别是什么?(09-10)
- 深度学习的硬件架构解析(10-18)
- 麻省理工科技评论评选的14大医疗领域突破科技(上)(10-14)
- 探秘机器人是如何进行深度学习的(09-18)