解读决策树与随机森林模型的概念
决策树,是机器学习中一种非常常见的分类方法,也可以说是所有算法中最直观也最好理解的算法。
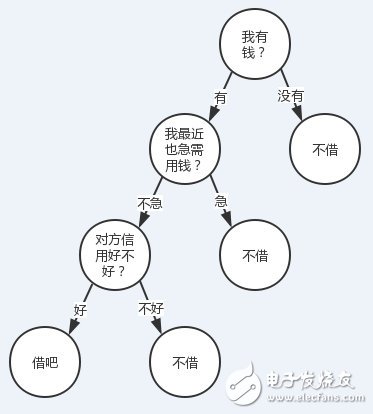
有人找我借钱(当然不太可能。。。),借还是不借?我会结合根据我自己有没有钱、我自己用不用钱、对方信用好不好这三个特征来决定我的答案。
我们把转到更普遍一点的视角,对于一些有特征的数据,如果我们能够有这么一颗决策树,我们也就能非常容易地预测样本的结论。所以问题就转换成怎么求一颗合适的决策树,也就是怎么对这些特征进行排序。
在对特征排序前先设想一下,对某一个特征进行决策时,我们肯定希望分类后样本的纯度越高越好,也就是说分支结点的样本尽可能属于同一类别。
所以在选择根节点的时候,我们应该选择能够使得"分支结点纯度最高"的那个特征。在处理完根节点后,对于其分支节点,继续套用根节点的思想不断递归,这样就能形成一颗树。这其实也是贪心算法的基本思想。那怎么量化"纯度最高"呢?熵就当仁不让了,它是我们最常用的度量纯度的指标。其数学表达式如下:
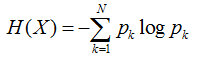
其中N表示结论有多少种可能取值,p表示在取第k个值的时候发生的概率,对于样本而言就是发生的频率/总个数。
熵越小,说明样本越纯。
以一个两点分布样本X(x=0或1)的熵的函数图像来说明吧,横坐标表示样本值为1的概率,纵坐标表示熵。
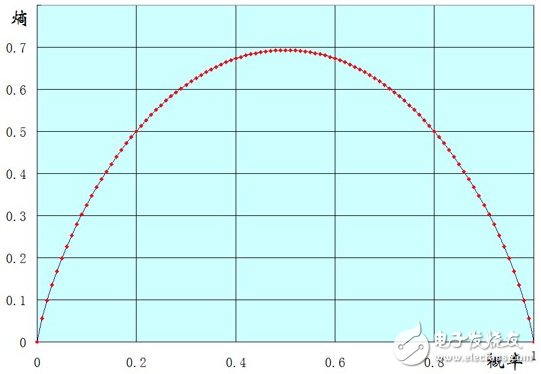
可以看到到当p(x=1)=0时,也就是说所有的样本都为0,此时熵为0.
当p(x=1)=1时,也就是说所有的样本都为1,熵也为0.
当p(x=1)=0.5时,也就是样本中0,1各占一半,此时熵能取得最大值。
扩展一下,样本X可能取值为n种(x1。。。。xn)。可以证明,当p(xi)都等于1/n 时,也就是样本绝对均匀,熵能达到最大。当p(xi)有一个为1,其他都为0时,也就是样本取值都是xi,熵最小。
决策树算法
ID3
假设在样本集X中,对于一个特征a,它可能有(a1,a2。。。an)这些取值,如果用特征a对样本集X进行划分(把它当根节点),肯定会有n个分支结点。刚才提了,我们希望划分后,分支结点的样本越纯越好,也就是分支结点的"总熵"越小越好。
因为每个分支结点的个数不一样,因此我们计算"总熵"时应该做一个加权,假设第i个结点样本个数为W(ai),其在所有样本中的权值为W(ai) / W(X)。所以我们可以得到一个总熵:
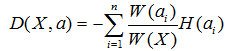
这个公式代表含义一句话:加权后各个结点的熵的总和。这个值应该越小,纯度越高。
这时候,我们引入一个名词叫信息增益G(X,a),意思就是a这个特征给样本带来的信息的提升。公式就是: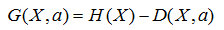 ,由于H(X)对一个样本而言,是一个固定值,因此信息增益G应该越大越好。寻找使得信息增益最大的特征作为目标结点,并逐步递归构建树,这就是ID3算法的思想,好了以一个简单的例子来说明信息增益的计算:
,由于H(X)对一个样本而言,是一个固定值,因此信息增益G应该越大越好。寻找使得信息增益最大的特征作为目标结点,并逐步递归构建树,这就是ID3算法的思想,好了以一个简单的例子来说明信息增益的计算:

上面的例子,我计算一下特征1的信息增益
首先计算样本的熵H(X)
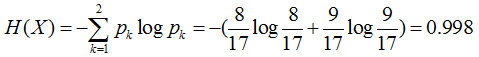
再计算总熵,可以看到特征1有3个结点A、B、C,其分别为6个、6个、5个
所以A的权值为6/(6+6+5), B的权值为6/(6+6+5), C的为5/(6+6+5)
因为我们希望划分后结点的纯度越高越好,因此还需要再分别计算结点A、B、C的熵
特征1=A:3个是、3个否,其熵为
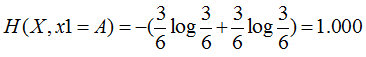
特征1=B:2个是、4个否,其熵为
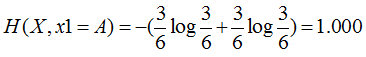
特征1=C:4个是、1个否,其熵为
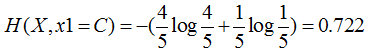
这样分支结点的总熵就等于:

特征1的信息增益就等于0.998-0.889=0.109
类似地,我们也能算出其他的特征的信息增益,最终取信息增益最大的特征作为根节点。
以上计算也可以有经验条件熵来推导:G(X,A)=H(X) - H(X|A),这部分有兴趣的同学可以了解一下。
C4.5
在ID3算法中其实有个很明显的问题。
如果有一个样本集,它有一个叫id或者姓名之类的(唯一的)的特征,那就完蛋了。设想一下,如果有n个样本,id这个特征肯定会把这个样本也分成n份,也就是有n个结点,每个结点只有一个值,那每个结点的熵就为0。就是说所有分支结点的总熵为0,那么这个特征的信息增益一定会达到最大值。因此如果此时用ID3作为决策树算法,根节点必然是id这个特征。但是显然这是不合理的。。。
当然上面说的是极限情况,一般情况下,如果一个特征对样本划分的过于稀疏,这个也是不合理的(换句话就是,偏向更多取值的特征)。为了解决这个问题,C4.5算法采用了信息增益率来作为特征选取标准。
所谓信息增益率,是在信息增益基础上,除了一项split informaTIon,来惩罚值更多的属性。
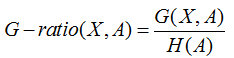
而这个split informaTIon其实就是特征个数的熵H(A)。
为什么这样可以减少呢,以
- 机器学习算法盘点:人工神经网络、深度学习(07-02)
- 自动驾驶技术到底什么时候能成熟?(09-12)
- AI/机器学习/深度学习三者的区别是什么?(09-10)
- 人工智能与机器学习差别与联系(10-07)
- Facebook人工智能母体技术解析(04-11)
- 一文汇总大数据四大方面十五大关键技术(10-11)