解读决策树与随机森林模型的概念
上面id的例子来理解一下。如果id把n个样本分成了n份,那id这个特征的取值的概率都是1/n,文章引言已经说了,样本绝对均匀的时候,熵最大。
因此这种情况,以id为特征,虽然信息增益最大,但是惩罚因子split informaTIon也最大,以此来拉低其增益率,这就是C4.5的思想。
CART
决策树的目的最终还是寻找到区分样本的纯度的量化标准。在CART决策树中,采用的是基尼指数来作为其衡量标准。基尼系数直观的理解是,从集合中随机抽取两个样本,如果样本集合越纯,取到不同样本的概率越小。这个概率反应的就是基尼系数。
因此如果一个样本有K个分类。假设样本的某一个特征a有n个取值的话,其某一个结点取到不同样本的概率为: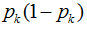
因此k个分类的概率总和,我们称之为基尼系数:
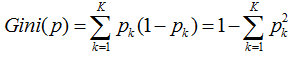
而基尼指数,则是对所有结点的基尼系数进行加权处理
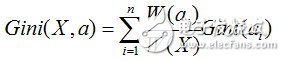
计算出来后,我们会选择基尼系数最小的那个特征作为最优划分特征。
剪枝
剪枝的目的其实就是防止过拟合,它是决策树防止过拟合的最主要手段。决策树中,为了尽可能争取的分类训练样本,所以我们的决策树也会一直生长。但是呢,有时候训练样本可能会学的太好,以至于把某些样本的特有属性当成一般属性。这时候就我们就需要主动去除一些分支,来降低过拟合的风险。
剪枝一般有两种方式:预剪枝和后剪枝。
预剪枝
一般情况下,只要结点样本已经100%纯了,树才会停止生长。但这个可能会产生过拟合,因此我们没有必要让它100%生长,所以在这之前,设定一些终止条件来提前终止它。这就叫预剪枝,这个过程发生在决策树生成之前。
一般我们预剪枝的手段有:
1、限定树的深度
2、节点的子节点数目小于阈值
3、设定结点熵的阈值等等。
后剪枝
顾名思义,这个剪枝是在决策树建立过程后。后剪枝算法的算法很多,有些也挺深奥,这里提一个简单的算法的思想,就不深究啦。
Reduced-Error Pruning (REP)
该剪枝方法考虑将树上的每个节点都作为修剪的候选对象,但是有一些条件决定是否修剪,通常有这几步:
1、删除其所有的子树,使其成为叶节点。
2、赋予该节点最关联的分类
3、用验证数据验证其准确度与处理前比较
如果不比原来差,则真正删除其子树。然后反复从下往上对结点处理。这个处理方式其实是处理掉那些"有害"的节点。
随机森林
随机森林的理论其实和决策树本身不应该牵扯在一起,决策树只能作为其思想的一种算法。
为什么要引入随机森林呢。我们知道,同一批数据,我们只能产生一颗决策树,这个变化就比较单一了。还有要用多个算法的结合呢?
这就有了集成学习的概念。
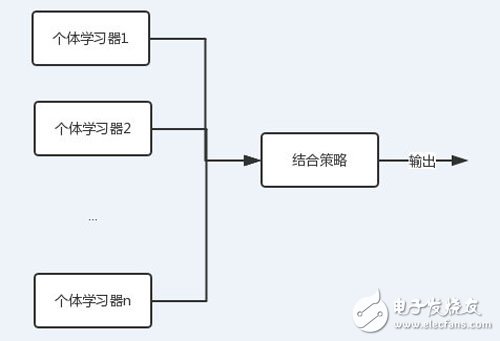
图中可以看到,每个个体学习器(弱学习器)都可包含一种算法,算法可以相同也可以不同。如果相同,我们把它叫做同质集成,反之则为异质。
随机森林则是集成学习采用基于bagging策略的一个特例。
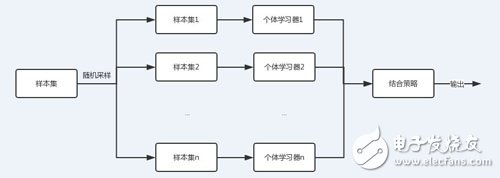
从上图可以看出,bagging的个体学习器的训练集是通过随机采样得到的。通过n次的随机采样,我们就可以得到n个样本集。对于这n个样本集,我们可以分别独立的训练出n个个体学习器,再对这n个个体学习器通过集合策略来得到最终的输出,这n个个体学习器之间是相互独立的,可以并行。
注:集成学习还有另一种方式叫boosTIng,这种方式学习器之间存在强关联,有兴趣的可以了解下。
随机森林采用的采样方法一般是是Bootstap sampling,对于原始样本集,我们每次先随机采集一个样本放入采样集,然后放回,也就是说下次采样时该样本仍有可能被采集到,经过一定数量的采样后得到一个样本集。由于是随机采样,这样每次的采样集是和原始样本集不同的,和其他采样集也是不同的,这样得到的个体学习器也是不同的。
随机森林最主要的问题是有了n个结果,怎么设定结合策略,主要方式也有这么几种:
加权平均法:
平均法常用于回归。做法就是,先对每个学习器都有一个事先设定的权值wi,
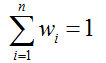
然后最终的输出就是:
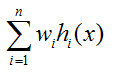
当学习器的权值都为1/n时,这个平均法叫简单平均法。
投票法:
投票法类似我们生活中的投票,如果每个学习器的权值都是一样的。
那么有绝对投票法,也就是票数过半。相对投票法,少数服从多数。
如果有加权,依然是少数服从多数,只不过这里面的数是加权后的。
例子
以一个简单的二次函数的代码来看看决策树怎么用吧。
训练数据是100个随机的真实的平方数据,不同的深度将会得到不同的曲线
测试数据也是随机数据,但是不同深度的树的模型,产生的预测值也不太一样。如图
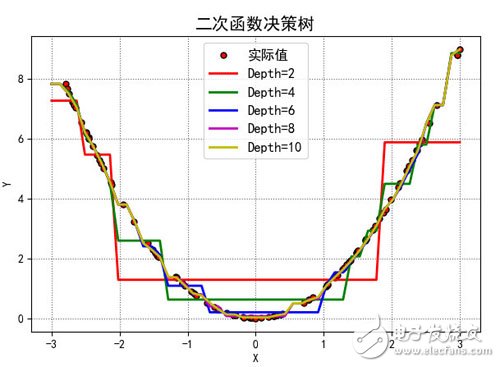
这幅
- 机器学习算法盘点:人工神经网络、深度学习(07-02)
- 自动驾驶技术到底什么时候能成熟?(09-12)
- AI/机器学习/深度学习三者的区别是什么?(09-10)
- 人工智能与机器学习差别与联系(10-07)
- Facebook人工智能母体技术解析(04-11)
- 一文汇总大数据四大方面十五大关键技术(10-11)