嵌入式系统中的目标识别技术
目标检测和识别是计算机视觉系统的一个必不可少的组成部分。在计算机视觉中,首先是将场景分解成计算机可以看到和分析的组件。
计算机视觉的第一步是特征提取,即检测图像中的关键点并获取有关这些关键点的有意义信息。特征提取过程本身包含四个基本阶段:图像准备、关键点检测、描述符生成和分类。实际上,这个过程会检查每个像素,以查看是否有特征存在于该像素中。
特征提取算法将图像描述为指向图像中的关键元素的一组特征向量。本文将回顾一系列的特征检测算法,在这个过程中,看看一般目标识别和具体特征识别在这些年经历了怎样的发展。
早期特征检测器
Scale Invariant Feature Transform (SIFT)以及 Good Features To Track (GFTT) 是特征提取技术的早期实现。但这些属于计算密集型算法,涉及到大量的浮点运算,所以它们不适合实时嵌入式平台。
以SIFT为例,这种高精度的算法,在许多情况下都能产生不错的结果。它会查找具有子像素精度的特征,但只保留类似于角落的特征。而且,尽管 SIFT 非常准确,但要实时实现也很复杂,并且通常使用较低的输入图像分辨率。
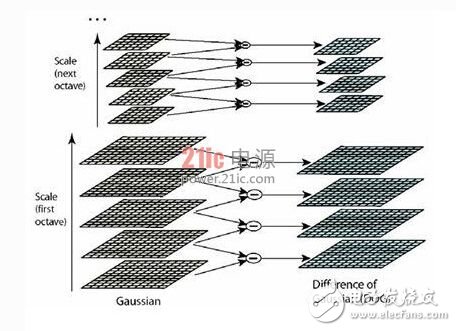
SIFT是一种计算密集型算法
因此,SIFT 在目前并不常用,它主要是用作一个参考基准来衡量新算法的质量。因为需要降低计算复杂度,所以最终导致要开发一套更容易实现的新型特征提取算法。
二代算法
Speeded Up Robust Features (SURF) 是最早考虑实现效率的特征检测器之一。它使用不同矩形尺寸中的一系列加法和减法取代了 SIFT 中浩繁的运算。而且,这些运算容易矢量化,需要的内存较少。
接下来,Histograms of Oriented Gradients (HOG) 这种在汽车行业中常用的热门行人检测算法可以变动,采用不同的尺度来检测不同大小的对象,并使用块之间的重叠量来提高检测质量,而不增加计算量。它可以利用并行存储器访问,而不像传统存储系统那样每次只处理一个查找表,因此根据内存的并行程度加快了查找速度。
然后,Oriented FAST and Rotated BRIEF (ORB) 这种用来替代 SIFT 的高效算法将使用二进制描述符来提取特征。ORB 将方向的增加与 FAST 角点检测器相结合,并旋转BRIEF描述符,使其与角方向对齐。二进制描述符与FAST和Harris Corner 等轻量级函数相结合产生了一个计算效率非常高而且相当准确的描述图。
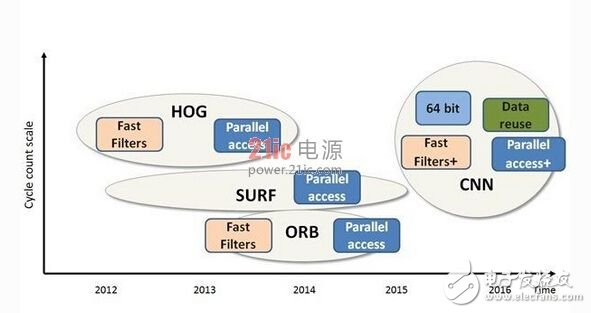
SURF和ORB等计算效率超高的算法为 CNN 之类的功能更强大的框架提供了实现的可能
CNN:嵌入式平台目标识别的下一个前沿领域
配有摄像头的智能手机、平板电脑、可穿戴设备、监控系统和汽车系统采用智能视觉功能将这个行业带到了一个十字路口,需要更先进的算法来实现计算密集型应用,从而提供更能根据周边环境智能调整的用户体验。因此,需要再一次降低计算复杂度来适应这些移动和嵌入式设备中使用的强大算法的严苛要求。
不可避免地,对更高精度和更灵活算法的需求会催生出矢量加速深度学习算法,如卷积神经网络 (CNN),用于分类、定位和检测图像中的目标。例如,在使用交通标志识别的情况下,基于 CNN 的算法在识别准确度上胜过目前所有的目标检测算法。除了质量高之外,CNN 与传统目标检测算法相比的主要优点是,CNN 的自适应能力非常强。它可以在不改变算法代码的情况下快速地被重新"训练(tuning)"以适应新的目标。因此,CNN 和其他深度学习算法在不久的将来就会成为主流目标检测方法。
CNN 对移动和嵌入式设备有非常苛刻的计算要求。卷积是 CNN 计算的主要部分。CNN 的二维卷积层允许用户利用重叠卷积,通过对同一输入同时执行一个或多个过滤器来提高处理效率。所以,对于嵌入式平台,设计师应该能够非常高效地执行卷积,以充分利用 CNN 流。
事实上,CNN 严格来说并不是一种算法,而是一种实现框架。它允许用户优化基本构件块,并建立一个高效的神经网络检测应用。因为 CNN 框架是对每个像素逐一计算,而且逐像素计算是一种要求非常苛刻的运算,所以它需要更多的计算量。
不懈改进视觉处理器
CEVA 已找到两种其他方法来提高计算效率,同时仍继续开发即将采用的算法,如 CNN。第一种是并行随机内存访问机制,它支持多标量功能,允许矢量处理器来管理并行负载能力。第二种是滑动窗口机制,它可以提高数据的利用率并防止相同的数据被多次重复加载。大多数成像过滤器和大型输入帧卷积中都有大量的数据重叠。这种数据重叠会随着处理器的矢量化程度增加而增加,可用于减少处理器和存储器之间的数据流量,从而能降低功耗。这种机
- 嵌入式系统在电源设计中的运用(09-20)
- 一种小型智能化UPS系统的嵌入式设计方案(09-16)
- 基于无线传感器网络的嵌入式远程测控系统研究(10-17)
- 嵌入式工业以太网控制器的设计和应用(10-17)
- 基于4G通信的嵌入式数据通信系统设计(10-10)
- 嵌入式CPU卡在医用便携式监护仪中的应用及设计(09-23)