雷达信号处理:FPGA还是GPU?
应指出,基准测试的矩阵大小并不相同。田纳西州大学的结果来自[512 × 512]的矩阵,而Altera基准测试的Cholesky是[360x360],QRD则高达[450x450]。原因是,矩阵规模较小时,GPU效率非常低,因此,在这些应用中,不应该使用它们来加速CPU。作为对比,在规模较小的矩阵时,FPGA的工作效率非常高。雷达系统对吞吐量的要求很高,每秒数千个矩阵,因此,效率非常关键。采用了小矩阵,甚至要求把大矩阵分解成小矩阵以便进行处理。
而且,Altera基准测试是基于每个Cholesky内核的。每个可参数赋值的Cholesky内核支持选择矩阵大小,矢量大小和通道数量。矢量大小大致决定了FPGA资源。较大的[360 × 360]矩阵使用了较长的矢量,支持FPGA中实现一个内核,达到91 GFLOP。较小的[60 × 60]矩阵使用的资源更少,因此,可以实现两个内核,总共是2 × 42 = 84 GFLOP。最小的[30 × 30]矩阵支持实现三个内核,总共是3 × 25 = 75 GFLOP。
FPGA看起来更适合解决数据规模较小的问题,很多雷达系统都是这种情况。GPU之所以效率低,是因为计算负载随N3而增大,数据I/O随N2增大,最终,随着数据的增加,GPU的I/O瓶颈不再是问题。此外,随着矩阵规模的增大,由于每个矩阵的处理量增大,矩阵每秒吞吐量会大幅度下降。在某些点,吞吐量变得非常低,以至于无法满足雷达系统的实时要求。
对于FFT,计算负载增加至N log2 N,而数据I/O随N增大而增大。对于规模较大的数据,GPU是高效的计算引擎。作为对比,对于所有规模的数据,FPGA都是高效的计算引擎,更适合大部分雷达应用,这些应用中,FFT长度适中,但是吞吐量很大。
GPU和FPGA设计方法
GPU可以通过使用Nvidia专用CUDA语言或开放标准OpenCL语言来编程。这些语言在能力上非常相似,最大的不同在于CUDA只能用在Nvidia GPU上。
FPGA通常使用HDL语言Verilog或VHDL进行编程。这些语言的最新版虽然采用了浮点数定义,但都不太适合支持浮点设计。例如,在System Verilog中,短实数变量对应于IEEE单精度(浮点),实数变量对应于IEEE双精度。
DSP Builder高级模块库
使用传统的方法将浮点数据通路综合到FPGA的效率非常低,如Xilinx FPGA在Cholesky算法上使用了Xilinx浮点内核产生函数的低性能显示,。而Altera采两种不同的方法。首先是使用DSP Builder高级模块库,这是基于Mathworks的设计输入方法。这一工具支持定点和浮点数,支持7种不同精度的浮点处理,包括IEEE半、单和双精度实现。它还支持矢量化,这是高效实现线性代数所需要的。最重要的是,它能够将浮点电路高效的映射到目前的定点FPGA体系结构中,如基准测试所示,规模中等的28 nm FPGA,Cholesky算法接近了100 GFLOP。作为对比,在不具有综合能力的规模相似的Xilinx FPGA上,实现Cholesky相同算法,性能只有20 GFLOP。
面向FPGA的OpenCL
GPU编程人员较为熟悉OpenCL。面向FPGA的OpenCL编译意味着,面向AMD或Nvidia GPU编写的OpenCL代码可以编译到FPGA中。而且,Altera的OpenCL编译器支持GPU程序使用FPGA,无需具备典型的FPGA设计技巧。
使用支持FPGA的OpenCL,相对于GPU有几个关键优势。首先,GPU的I/O是有限制的。所有输入和输出数据必须由主CPU通过PCI Express® (PCIe®)接口进行传输。结果延时会让GPU处理引擎暂停,因此,降低了性能。
面向FPGA的OpenCL扩展
FPGA以各种宽带I/O功能而知名。这些功能支持数据通过千兆以太网(GbE)和Serial RapidIO® (SRIO),或直接从模数转换器(ADC)和数模转换器(DAC)输入输出FPGA。Altera定义了OpenCL标准的供应商专用扩展,以支持流操作。这种扩展对于雷达系统非常关键,数据能够从定点前端波束成形直接输出,支持浮点处理阶段的数字下变频处理,实现脉冲压缩,多普勒,STAP, 动目标显示(MTI),以及图2所示的其他功能。通过这种方法,数据流在通过GPU加速器之前,避免了CPU瓶颈问题,从而降低了总处理延时。
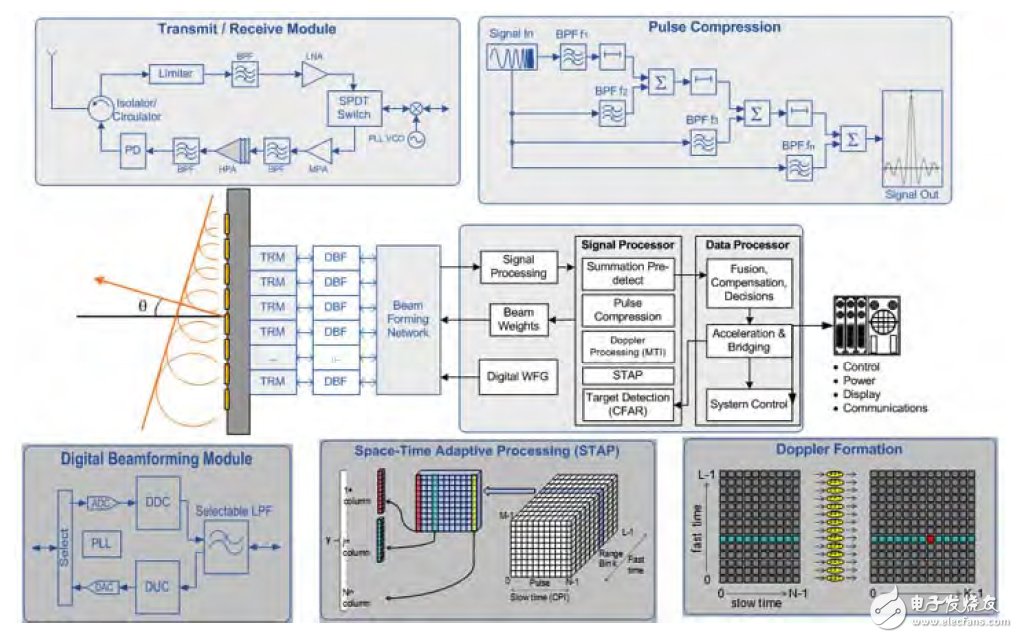
图2.通用雷达信号处理图
即使与I/O瓶颈无关,FPGA的处理延时也要比GPU低很多。众所周知,GPU必须有数千个线程才能高效工作,这是由于存储器读取很长的延时,以及GPU大量的处理内核之间的延时。实际上,GPU必须有很多任务才能使得处理内核不会暂停等待数据,否则会导致任务很长的延时。
而FPGA使用了"粗粒度并行"体系结构。它建立了多个经过优化的并行数据通路,每一通路在每个时钟周期输出一个结果。数据通路的例化数取决于FPGA资源
- GPU性能不够跑VR?这项技术或许能解决难题(03-29)
- VR设计:如何实现GPU和显示器高度集成(05-11)
- 基于CUDA技术的视频显示系统的设计方案(06-08)
- 笔记本电脑中温度传感器的应用(06-14)
- 双GPU设计 打造最简单与最快速的加速方案(05-25)
- Intel第六代处理器 Skylake CPU、GPU、主板完全解析(09-06)