基于DSP的语音识别系统的实现及分析
码器来实现对语音数据的采集。由AIC23采集的数字信号数据通过McBSP1存入SDRAM 中,数据传输方式为EDMA方式下的McBSP数据传输。数据处理模块是系统的核心模块,用TMS320C6713DSP芯片来完成语音识别算法的实现。训练时,DSP完成语音信号MFCC特征参数的提娶SVM 建模并存入Flash中;识别时,DSP读取待识别语音信号数据并将获得的模型参数与训练模型参数进行比较,进而得到识别结果。
2.2.2 基于DSP的语音识别系统的实现及分析
本系统设计主要涉及到语音数据段、执行代码段、载入Flash的程序段和模型参数段等。在编程中主要以C语言编程为主,配合使用汇编语言,使程序运行效率更高。
实验结果及其性能分析:
训练时,系统上电,加入工程项目。图5所示为读取"12345"的语音时部分主程序、对音节切分后数字"1"提取的语音及其第10帧的MFCC参数、mfcc子程序等。
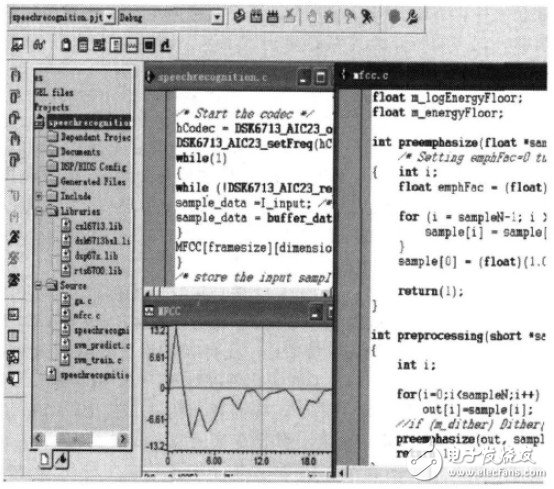
图5 MFCC参数
识别过程中,将存入Flash中的训练模型参数依次读出,与待识别语音信号的MFCC参数比较,最后得到识别结果。
实验中读取20句话,每句话含有6个不同汉语数字的连续语音,通过对其进行测试,得到识别率为76.7%.图6是对音节切分后的数字"2"的识别情况,在STD栏输出了最后识别结果即数字"2"。
3 结论
本文通过在Matlab平台上进行仿真实验选取合适的参数及模型,并将其移植到 TMS320C6713DSK上实现了非特定人小词汇量连续语音识别系统。其中基于TLV320AIC23完成了对语音数据的采集,借助SDRAM 和Flash进行数据存储,并采用短时能量和短时过零率进行语音信号的初步判定,结合起来进行测试,在Windows7操作系统中使用DirectX SDK 9.0b进行视频显示,QR解码程序为自行编制,并与TPS自动测试台集成。连续地采集视频,在计算机显示屏上实时显示影像图的同时进行条码解码定位,结果显示单帧图像的平均解码时间为630ms,使用帧相关算法后,平均解码时间为124ms.
图6为在单码定位时预估未定位条码的结果,q1为已定位码,q2,q3,q4为未定位码,由q1预估q2,q3,q4的结果为图中的加亮框表示,对框区域外扩使其包含完整条码,然后把扩域后的子区域独立出来,作为下一帧条码解码的有效区域以提高图像处理速度。

图5 视频辅助探针定位

图6 单码定位的预估结果
本方法在采用帧相关及位置相关算法后,在普通PC上实现实时视频,并具有如下特点:
a)无需夹具,允许遮挡,允许测试板和探头位置变化;探针和目标点标记同时出现影像图上,直接引导,无需在影像和实板上对照查找,提高探测效率,减小出错机会。
b)QR码定位符含测试板信息,可以在PCB板制作过程中通过丝印到PCB板上,也可以在后期纸制粘贴到PCB板上(但要精确地保证每块板上的QR码位置相同),允许同一板面任意多定位码,以区分不同PCB板及不同板面,用作PCB加电前预检测,可保证加电安全。
- 基于AD73360和TMS320F2812的数据采集系统设计(12-06)
- 基于紫外检测法的智能型特高压验电器系统(03-17)
- 单一DSP控制两套三相逆变器的实现(08-31)
- 基于DSP生成SVPWM在逆变电源中的应用(11-09)
- DSP的大功率开关电源的设计方案(12-01)
- DSP处理器电源方案设计(02-08)