应对下一代移动图形处理的挑战
,所以其中任何一个元件功耗的减少,都可以增加其他元件可以使用的配额,这也是系统功耗配比由用例决定的原因。
现代GPU非常复杂,严重依赖CPU运行驱动程序,以实现基于软件与应用程序进行交互。多亏了Vulkan这样的现代API,驱动程序的开销下降了,但是CPU依然需要运行驱动程序,所以不能完全避免耗电。由于所有元件功耗预算共享,因此在CPU中使用的、用于GPU交互的功耗就是不能应用于GPU本身的功耗。基于上述原因,降低CPU功耗势在必行,不仅是为GPU发展扫清瓶颈,更是要为尽可能的提高GPU可用功耗铺平道路。
与之类似,在运行复杂3D游戏的现代系统中,GPU会消耗大量DRAM带宽。由于要处理大量数据(上述提及的Lofoten每帧处理600,000个三角),消耗带宽责无旁贷,但DRAM的读写本身就是耗电的过程,也需要占用系统的总功耗预算。减少DRAM带宽可以降低其功耗,并用于其他元件。
现代智能手机的设计和日益复杂的用例对GPU提出了前所未有的挑战。下一章,我们将介绍ARM新一代GPU和GPU架构是如何应对这些挑战的。
为下一代设备打造的Mali-G71
Mali-G71是ARM最新推出的高性能GPU,也是首款基于全新Bifrost架构的GPU,性能和效率都获得显著提升。

Mali-G71是迄今为止ARM性能最高的GPU。为满足现代用例所需性能,着色器核心数量从1扩展至32,帮助芯片制造商根据目标市场自主权衡性能和功耗。出于这个原因,我们认为Mali-G71将在各类应用中将大展拳脚。
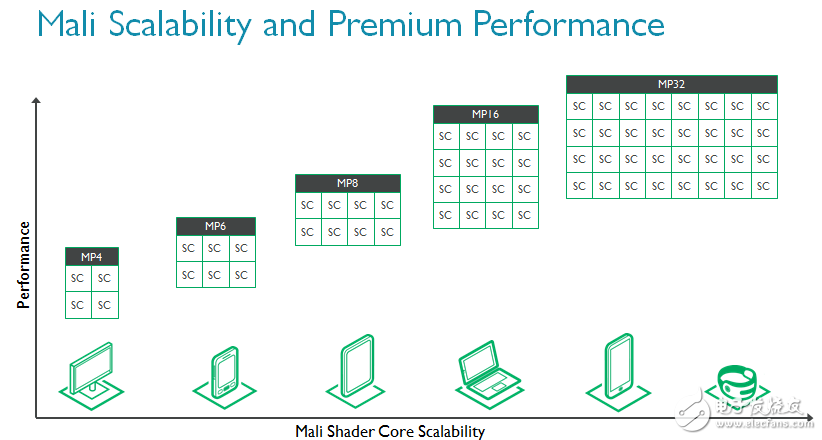
如前文所述,智能手机的很多性能都受到散热的限制,还有一些手机的限制因素则是成本,或者说是芯片尺寸。为了实现更高性,Mali-G71和Bifrost架构同时升级了能源效率(单位瓦特性能)和性能密度(单位芯片面积性能),帮助功耗与散热性能遭遇挑战的芯片制造商实现更高的GPU性能。相似条件下,Mali-G71的能源效率相较Mali-T880最多可提高20%,性能密度最多可提高40%。此外,外部存储消耗的总带宽降低20%,进一步减少整体系统功耗。

Bifrost架构发展
为了进一步说明Mali-G71为何具备远超历代ARM GPU的性能,我们首先来探讨一下GPU架构本身,以及实现这些性能的设计方法。
Bifrost是ARM的第三代可编程的GPU架构,其研发知识与经验传承自Utgard和Midgard GPU架构。
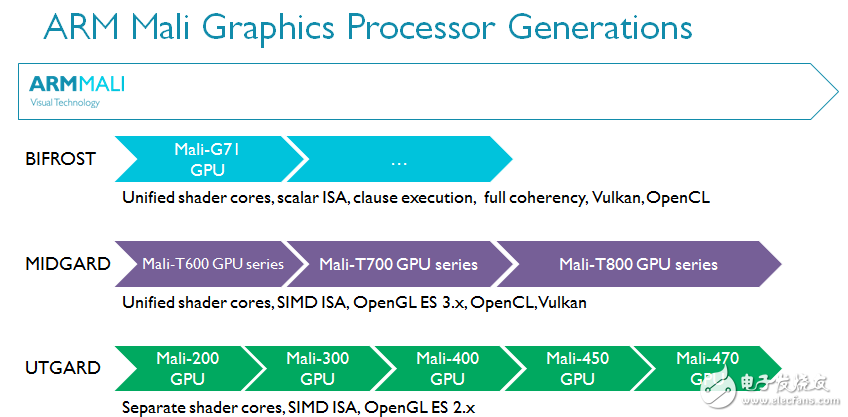
ARM的前两代GPU架构——Utgard和Midgard都取得了巨大成功。它们专为新兴的移动GPU市场打造,无论出货量还是内部科技的运用都可圈可点。Utgard是ARM首款可编程GPU,支持GLES 2.x,片段着色器与顶点着色器相互独立。Midgard则引入了统一着色器,支持GLES 3.x,并可与OpenCL 1.x Full Profile协同实现GPGPU运算。Midgard是一款前瞻性的GPU架构,甚至包括了一些可以支持Vulkan的功能特性。考虑到这是5年前设计的架构,就足以成为了不起的成就。
然而,随着内容和用例的改变,架构本身也必须进行根本性的升级,以适应各类下一代用例。
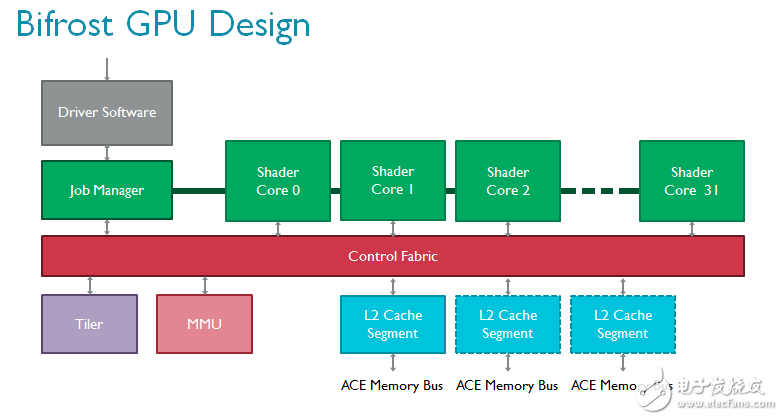
从顶层设计看,与Midgard架构相比,Bifrost的GPU内核没有明显变化。表面上依然包括多个可扩展的着色器核心、一个负责与驱动程序交互的任务管理器、一个负责处理内存页表的MMU以及一个TIler(Bifrost 仍然是一个 TIle based 渲染架构),但全部模块都获得了显著提升。
通过AMBA ACE或AXI-Lite与外界交互的L2子系统为支持AMBA 4 ACE专门设计,帮助Mali-G71彻底实现硬件一致性,并在GPU和CPU等其他单元之间实现了基于硬件的细粒数据透明共享。
我们对TIler做了重新设计,以支持一种全新的渲染流,即索引驱动的位置渲染。该技术的理念是将顶点着色分为两部分以节省带宽,因为无需读写屏幕上看不见的变化参数(varying)1;而且由于无需写回不可见位置,带宽可以得到进一步节省。
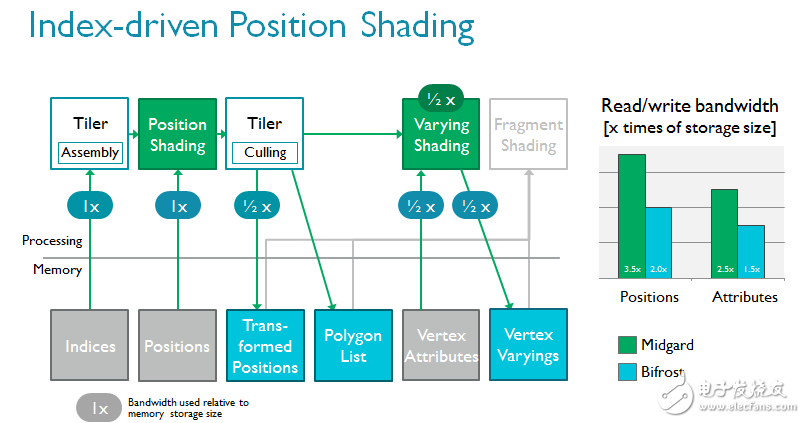
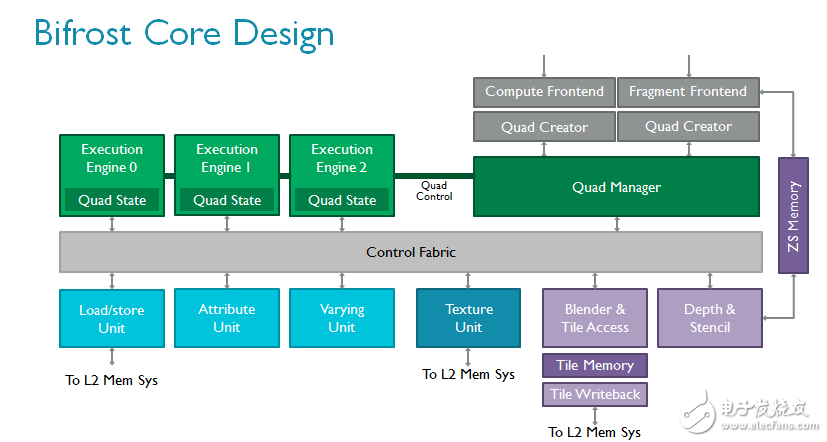
着色器核心本身的变化更为巨大。ARM在Bifrost中引入全新指令集,根据大量的内容和趋势分析以及长年的行业经验开发。现代GPU的总体趋势是执行越来越多的复杂可编程着色器,通常通过算法完成并采用大量标量代码。作为全新引擎的一部分,Bifrost采用全新的算法单元,以极高的效率执行高级着色器核心。它们更容易扩展,如果未来需求有增加,该架构也可以轻松应对。
Bifrost的属性(attribute)单元和变化参数单元相互独立,这些操作在图形处理中极为普遍,使用独立的高度优化硬件模块更为合理。全新的指令集引入高效的四线程组以节省控制逻辑,并通过四线程组管理器将线程组切换至执行引擎。我们还加入了一个控制架构以提高物理利用率。如上文所述,此特性对现代工艺节点非常重要。
Bifr
Bifrost架构 Mali-G71 GPU ARM 相关文章:
- GPU性能不够跑VR?这项技术或许能解决难题(03-29)
- VR设计:如何实现GPU和显示器高度集成(05-11)
- 基于CUDA技术的视频显示系统的设计方案(06-08)
- 笔记本电脑中温度传感器的应用(06-14)
- 双GPU设计 打造最简单与最快速的加速方案(05-25)
- Intel第六代处理器 Skylake CPU、GPU、主板完全解析(09-06)