智能家庭应用之语音识别系统
息判断是否为噪声、干扰或目标语音源训练滤波器。在这种架构中可以使用任何合适的VAD。
系统的核心是不受监视的空间滤波(USF)—基于独立分量分析(ICA)的一种BSS算法。这种ICA算法设法建模目标源和干扰源的混合系统,并允许用线性滤波将它们分开来。在只有两个麦克风的系统中,USF将产生4个信号输出,每个麦克风2个。对每个麦克风来说,一个信号包含目标源和一些残留噪声,另一个信号包含对所有干扰源的估计,其中目标源已经被滤除。
USF做到这一点所需的唯一信息是在知道何时目标语音有效以及何时噪声有效,这个信息来自VAD。然后USF寻找滤波器以完全不受监视的方式对目标源和干扰源进行分拆。USF并不明确地使用源方向,虽然这个信息可以用来改善 VAD决策。另外,麦克风在设备上的位置和麦克风之间的不匹配对算法的影响很小。在ICA系统中,如果存在N个源,那么通常至少需要N个麦克风来恢复原始信号。然而,通过将信号看作是包含1)一个目标语音信号和一个噪声信号,或2)只有一个噪声信号,ICA可以只与两个麦克风和未知数量的噪声源一起使用。
USF 的输出不是在系统输出中直接使用,因为它假设合成信号是由有限数量的空间定位源产生的信号的线性合成。这种一致性假设条件对主要的语音源信号来只是部分成立,但对现实世界噪声来说不是的。因此线性滤波对于现实世界应用来说不是最优的,要求用非线性、随时间变化的统计性后置滤波对信号进行补偿。后置滤波方法通常涉及到对由线性滤波器输出推导出的频谱/临时模板(或增益)进行估计。虽然模板通常能提高噪声抑制能力,但如果没有考虑分拆模型不确定性的话,屏蔽效应可能导致信号的严重劣化。
用于频谱滤波的方法可以基于不受监视的频谱增益分布学习,而这种分布源自USF的输出信号。然后就能产生语音存在/不存在的概率;这些概率用来控制对每个通道的频谱增强。增强技术可以消除有害的干扰,与此同时消除最近的混响分量,即有效地去除混响。
图 6和图7显示了这样一种系统的性能例子。在这个测试中,用户距双麦克风系统3米远。麦克风处的目标语音电平是60dB,麦克风处的干扰语音电平是 50dB。图6中的上面通道显示的是没经任何处理的接收信号。下面通道显示的是经过处理后的输出。图7显示了处理之前和之后的干扰频谱内容。在这种条件下,可以达到大约30dB的干扰信号抑制。当未处理信号通过语音识别引擎发送时,可能达到95%的误字率(WER)。经过处理后的WER可下降到15%。
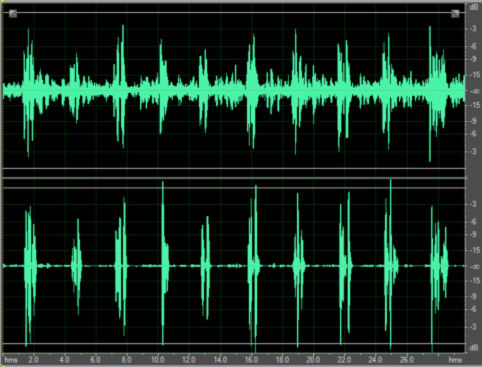
图6:上面通道显示的是未经任何处理的接收信号。下面通道显示的是处理后的输出。
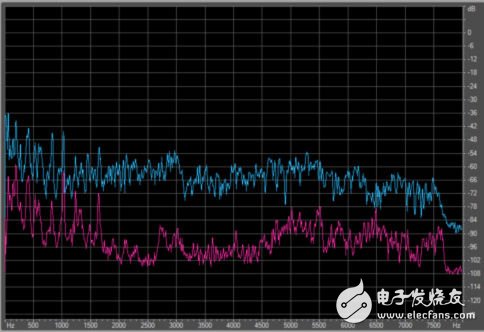
图7:显示的是处理之前和处理之后的干扰频谱内容。
声学回音消除(AEC) 已经存在很多年了,是任何免提通信系统的必要部分。声学回音消除器可以从麦克风记录中消除设备本身正在回放的音频。最简单的AEC是半双工的,也就是说,当远端在讲话时,它会马上关闭近端的麦克风,反之亦然,即当近端讲话时则关闭远端的麦克风。在这些系统中,同一时刻只能有一边讲话。
对于语音控制应用来说,真正的全双工回音消除是系统的一个必要部分,也就是要达到语音控制和回放同时进行的效果。声学回音消除器(AEC)要想正常工作,需要能够访问到信号,也就是设备正在播放的回音参考。AEC随即使用这个回音参考对房间内的声学回音路径进行线性建模。然而在实际系统中,回音路径中通常有相当多的非线性因素,它们会显著降低系统性能—比如当设备正在试图从小的扬声器中产生大的回放音量时。另外一个例子发生在回放信号被发送到AEC作为回音参考之后对这个回放信号进行非线性的后置处理之时。语音控制的机顶盒(STB)就是这种情况,此时AEC在工作,机顶盒中也获得了回音参考,但电视机很可能在播放音频之前在音频上叠加一些未知延时和后处理。在这些条件下使用传统的AEC性能会很低。
这个问题可以这样解决:将AEC连接到前文介绍的噪声抑制技术。只要AEC能够区分远端、近端和双边谈话活动,这个信息就能用作USF的活动检测输入。这种方法在具有非线性及受损回音参考的系统中可以提供真正全双工的AEC性能。
另外,这种新的AEC技术应该包含一个延时估计算法,以便通过对齐回音参考和麦克风信号来解决回音路径中的未知延时,就象在机顶盒案例中那样。
图 8和图9显示了一个机顶盒系统的性能。用户距电视机3米远,麦克风模块位于电视机顶上,并连接到机顶盒。用户给机顶盒发出自然语言命令。在麦克风模块处目标语音的SPL是60dB,来自电视回放内容的回音
- 安森美半导体配合智能电网及智能家庭趋势的工业通信及安全保护方案(02-08)
- 小米智能家庭套装究竟选择了什么ZigBee方案?(02-27)
- 物联网时代下智慧家庭的自动控制方案解析(05-06)
- 深层次探讨楼宇对讲的转型之路(02-16)
- 低成本要求联网照明的复杂性,严格的联网照明到底要如何实现!?(07-29)
- 开发智能家居系统,电源该如何设计?(08-15)