高维图像识别技术让PC也能看懂图片
近年来,计算机图形图像处理技术获得突破性的进展,个人PC中也涌现出越来越多令人惊叹的图形处理软件,凭借着数学界领域的最新研究,个人电脑已经开始学会了"看"图,读懂文字,辨别建筑物。

传统的PC图像识别技术主要基于统计学原理,其主要依靠分析视觉数据的特性,并将这些特性借助统计建模等数学分析方式提取出来,以最终应用到实际的图像处理中。这种图像识别技术仍旧是目前的主流,广泛用于OCR文字识别、人脸识别、图像处理等领域。但是这种传统的数学分析方式存在很多局限,比如对图片的质量要求很高,这一问题直到新的数学模型出现才得以改善。在2010年5月CHIP的"时尚科技"栏目中,我们就曾经向大家介绍过一种PC图像识别技术的新进展。2009年以华裔澳大利亚籍数学家陶哲轩为代表的一些数学家率先发现了在高维空间中一些原先公认很难的(NP-hard)组合问题,可以用一系列高效的凸优化算法来解决。而由此产生的数学模型可以用来解决目前视觉计算所面临的难题,而且最终的计算结果非常理想。
微软亚洲研究院的研究员们当时利用这种数学思想取得了图像识别领域的很大突破,使用这种新的数学模型带口罩或墨镜的人脸甚至都可以被PC读取和识别。最近,微软研究院的研究员们在这一技术领域再次取得了新的进展,他们让PC能够看"懂"建筑物,或者具备"认"字的能力,并纠正扭曲或变形的文字。
读图从看懂结构开始
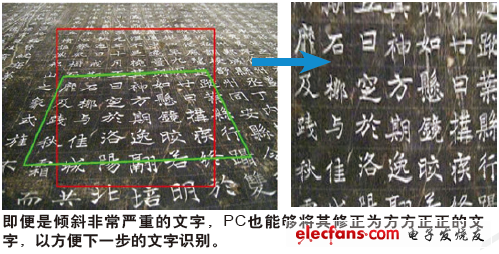
传统的二维图像识别技术更多地依赖图像特征点来工作,它首先通过统计学的方式来获取图像中最有代表性的点,之后在遇到新的图像时会尝试在其中寻找这些特征点,并将寻找到的点与原来统计得来的特征点进行对比。在图片质量比较出色且没有扭曲的情况下这种技术往往能工作得很好。但现实情况是,我们在拍摄图片时,由于光线、所处的位置等诸多原因,最终无法获得合格的图像,这也就大大限制了这种图像识别技术的发展。
微软亚洲研究院的研究员们尝试使用高维的数学模型和优化工具来解决这个问题。简单地理解,高维的数学模型采用矩阵的模式,可以帮助我们以整体的概念来看待图像中的物体,而不像传统技术那样只获取局部特征点,这更像是寻求图像中物体的整体对称性和规则性。例如,通常的楼房窗户都是平直的矩形,桌子总是四四方方拥有4条腿等。借助这些规则,即便图片只能提供有限的信息,PC也能够更容易地识别出图片中的物体。在高维数学模型中,输入每一个点的数据都可以被用来预测某种规则性,因此这种高维的图像识别技术可以利用图片中几乎每个像素点来获取图像中物体的整体规则结构,这意味着往往只需图片的一小部分即可完成图像中物体的矫正和识别。例如,在传统图像识别技术中,100×100的图像区域往往提供不了多少特征点数据,而在高维的图像识别技术中,这意味着将有近10000个像素点都可以用来获取图像的规则结构信息。
从人的角度读图
借助规则性和规律性来识别周围的环境和景物是人类的基本技能,实际上一个人从出生开始就在学习各种各样的规则。比如什么是矩形、什么是圆形,以及桌子一般什么样、房子一般什么样等等。而高维图像识别使得计算机具备了与人类相同的图像识别方式。当我们看到照片中楼房的窗户因为拍摄视角的问题而变得倾斜时,并不会认为窗户就真的是倾斜的,我们甚至知道窗户本来应该是方正的,同时我们还能分辨出挡在窗户前的树杈并不是窗户的一部分。类似地,通过建立高维图像识别的物体规律,微软研究院的研究员们已经能够让PC实现类似的功能,它能够帮助我们把倾斜的楼宇校正,或者擦去楼宇前方的树枝。
由此我们也可以了解这项技术的特长与不足,凡是遵循一定规则的物体或图像,这项技术就能够通过建立规则的方式对其进行识别,凡是规则性不强的物体或图像,这项技术往往就会有较大的局限,例如在一个混乱的花丛中处理某个物体就不是这项技术能够胜任的。通常来说,具备规则性的物体往往是由人所创造,因为从人类最基本的理念上来看,人类相信这个世界是简单的,且具备规整结构的,在人类创造各种物品时都会遵循简单、易用的原则,在这种原则的影响下,没有规则性的事物就会被逐步淘汰。规则并没有我们想象的那么复杂,我们并不需要给世界上的每一种物体都建立一个规则。这里的规则实际上是一种数学结构的分类,很多物体在数学结构角度上看是相同的东西,所以我们只需要建立一些重要的通行规则即可。当然也有一些特殊事物要单独建立规则,例如文字。
文字这种由人类发明的图形组合,在人
- 图像识别技术在银行ATM监控的应用(08-05)
- 借力MEMS传感器,机器人将越来越智能(02-04)
- 基于线性CCD图像识别智能小车的设计与开发(05-11)
- 智能小车图像识别系统电路设计分析(06-08)
- 人工神经网络中语音分析与图像识别的研究(08-27)
- LT3751如何使高压电容器充电变得简单(08-12)