SVM在车牌字符识别中的应用
4 最佳参数模型的选择
本文从某一实际卡口系统采集到的768×576像素的汽车牌照图片进行车牌定位和字符分割后,将分割的每个车牌字符进行二值化操作,字符笔划对应的像素置为l,背景像素置为0,再将每个字符归一化到13x24像素,并根据每个字符在车牌中的位置,编上序号l~7。
本文所选汽车牌照图片共计132张,包括晚上、逆光、字符磨损厉害、牌照倾斜和牌照旁挂其它牌子等情况;有129张图片可以实现车牌正确定位,车牌定位率为97.73%;120张图片可以实现所有字符正确分割,字符分割完全正确率为93.02%。
本文将每个字符作为一个样本,每个样本维数为312(13x24),根据其序号分成4类样本。每类样本分成两部分,60%的样本训练产生模型,另40%用于测试,核函数采用径向基函数K(xi,x)=exp(-||x-xi||2/σ2),分别训练生成4类分类器,从中选择最优参数模型组成4类最佳分类器,用来进行车牌字符的整体识别。
为了求解最佳的分类器参数(C,σ2),本文选择双线性法来求解最佳参数,对每类分类器模型采用以下步骤:
第一步:根据识别正确率确定最佳参数C。首先假设C=10,取σ2=10-1,100,101,102,103,得到最高的识别正确率对应的σ2,然后固定σ2,改变C的值,得到这时最高的识别正确率对应的C值,作为最佳参数C。
4类分类器的最高识别正确率对应的(C,σ2)都为(10,100),确定最佳C=10。
第二步:确定最佳参数(C,σ2)。固定最佳参数C,取σ2=l,10,100,200,300,400,500,600,700,800,900,1000,取最高识别正确率对应的(C,σ2)为分类器模型的最佳参数。
观察发现,4类分类器模型在σ2的值变为100以下时,对应的识别正确率都逐渐减小;σ2的值变为100以上时,对应的识别正确率先增大后减小,出现“峰值”,取“峰值”对应的模型参数为最佳参数。4类最佳分类器如下表1所示。
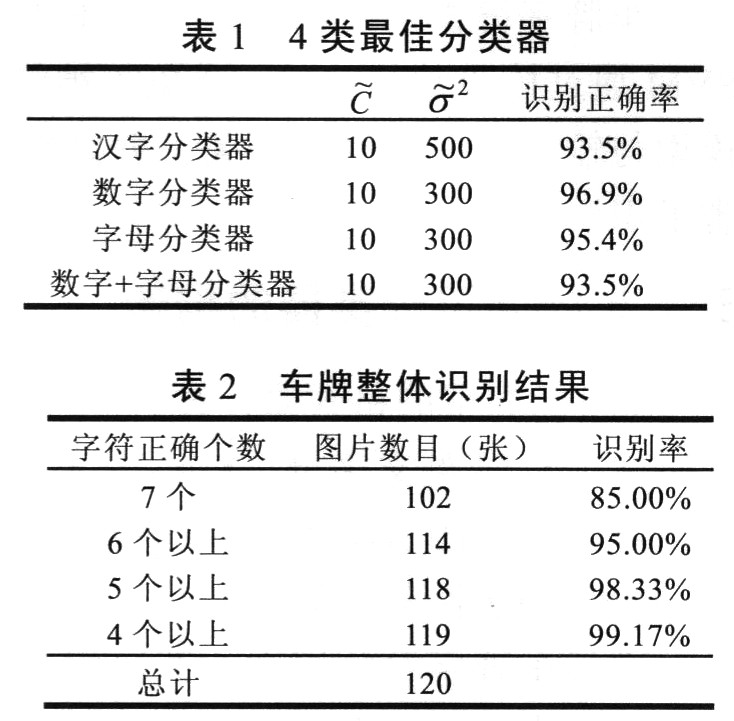
实验观察分析,分类器识别时具有一定的偏向性,即参与训练的某类样本数目多,预测样本识别为该类的概率就大,如训练样本中“浙”字较多,汉字分类器将预测样本识别为“浙”的可能性较大,而实际上预测样本中“浙”字数目较多,这样无形中就提高了识别正确率。
5 实验及结果
本文用以上4类最佳分类器的组合分类器对所有车牌字符进行整体识别,识别结果如表2所示。
在实际运用中,车牌字符正确数目在5个以上就能满足要求,本文与相关文献的车牌字符识别结果如表3所示。
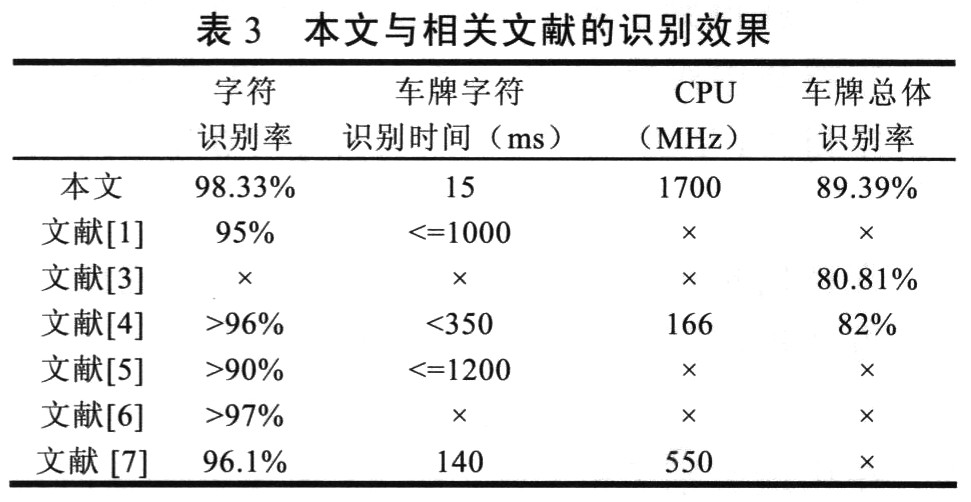
观察分析发现,影响识别效果的主要原因是相似字符的误识,如字符“D”和“0”、“B”和“8”等;还有汉字笔划多,二值化操作易造成笔划模糊,使汉字误识。
6 结论
本文将SVM的方法引入车牌字符识别中,在详细分析了车牌字符的排列特征的基础上,构造了用4个不同类别的SVM字符分类器;根据车牌字符的序号分别对应识别,再将识别结果组合,就得到了整幅车牌的号码。
SVM方法采用核函数解决了高维样本识别问题,不需要进行模型网络结构设计,并且不需进行特征提取,只需要有限的样本参入训练,节省了识别时间,这些都非常符合车牌字符识别的要求。本文采用一一区分法将SVM方法从二类别识别扩展到了多类别识别,并取得了满意的识别效果;但一一区分法需要保证训练样本的充分性,需要所有类别的样本都参加训练。
试验结果表明,本方法有较好的实用性,而进一步减少相似字符和汉字误识是本工作以后努力的方向,其关键是加强图像的预处理,改进字符分割方法和二值化方法,使字符笔划更清楚。
SVM 相关文章:
- 了解基于FastCV视觉库的SVM机器学习算法(02-08)
- LT3751如何使高压电容器充电变得简单(08-12)
- 三路输出LED驱动器可驱动共阳极LED串(08-17)
- 浪涌抑制器IC简化了危险环境中电子设备的本质安全势垒设计(08-19)
- 严酷的汽车环境要求高性能电源转换(08-17)
- 适用于工业能源采集的技术 (08-10)