VEGA/EPYC/ThreadRipper等多点开花,但AMD还远远不是Intel和NVIDIA的对手
那条打不倒的红色巨龙又回来了!AMD从成立至今近50余载,一直在与老冤家Intel斗争,在2006年收购ATi后,AMD又开始了与NVIDIA的漫长斗争,其不得不在CPU和GPU两条线上分别与不同的强敌竞争,并且这无形中拉近了Intel和NVIDIA的关系,AMD却不得不在两条线上疲于奔命。其结果就是对研发资源和市场资源都不占优的AMD来说,CPU在今年之前一败涂地,GPU也是被NVIDIA压着打。
令人欣喜的是,随着AMD现任掌门人Dr. Lisa Su于2015年出任AMD CEO,AMD重构了产品策略,其不再把PC当成唯一的出入,嵌入式、半定制业务成了AMD最成功也是最赚钱的业务,弥补了CPU和GPU业务上的亏损。

2015年9月,AMD新成立的Radeon Technologies Group着手开发更有竞争力的GPU产品,这就是去年大火的Polaris家族GPU,这个能耗比优秀的14nm新产品成功帮助AMD的独显市场份额从20%提至30%,AMD的股价也随之大涨。

转眼到了2017年, AMD终于在上半年放出了筹备多年,采用Zen架构的全新Ryzen系列CPU让AMD重拾业界领导者的风范,在性能不输甚至胜过Intel同级别酷睿的同时,价格低至腰斩,这让Intel彻底乱了阵脚,以至于Intel刚刚发布的八代酷睿处理器全部在价格未大涨的基础上多加两个核,通过"越级"的方式来提升产品竞争力 。
此后,AMD又相继发布了VEGA、EPYC、ThreadRipper等极具竞争力的产品,真可谓是遍地开花。对AMD来说,2017年是一个产品大年,他们想通过发布不同的产品去占领不同价位的终端市场,因为AMD深知,没有时间再拖延了,十年偃旗息鼓只为今天的一步登天,这种志向可以从其CPU产品以龙命名,GPU产品以星系命名看出。

为了让公司的投资者对AMD持续抱有信心,Dr. Lisa Su一改AMD以前的拖延问题,将研发团队整合,按计划接二连三地发布CPU和GPU新品。此外,AMD还发布了覆盖2017到2020的长期产品路线图,以CPU为例,其计划在2017年到2020年间发布三代Zen架构处理器,这就意味着每一代处理器的研发上市周期仅为15个月。
就目前来看, AMD的前景非常可观,但仍有许多人持否定和观望的态度,那么AMD到底能否凭借这些新品重回巅峰?笔者从其GPU产品和市场现状入手,去探讨一下,现在是否是AMD逆袭的最好时机 。
Instinct:全面进军深度学习领域
去年年末,AMD发布了采用VEGA架构的首款GPU,它不是专业卡也不是游戏卡,而是主打深度学习的加速卡,其名为Radeon Instinct MI25,这也是AMD头一次为加速卡单独开辟一个系列。
Radeon Instinct其实准确说来是一个完整的体系,底层基于新的硬件加速卡,结合ROCm开源软件平台(支持x86/ARM/Power平台并可导入CUDA应用),再辅以优化的机器学习和深度学习框架、应用,可广泛服务于云、大规模数据中心、金融服务、能源、自动驾驶等领域。Radeon Instinct系列的诞生表明AMD也要紧跟时代潮流,全面进军机器智能和人工智能的市场。

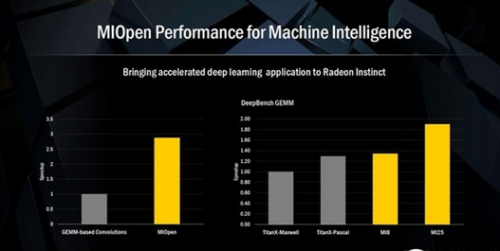
Radeon Instinct MI25作为Instinct家族的最强音,其性能也是对得起头牌之名。 在百度开源深度学习硬件基准DeepBench GEMM对比图上我们可以看到,Radeon Instinct MI25的性能高出NVIDIA TITAN X Pascal约46%,由于当时NVIDIA TITAN Xp还没有发布,根据性能推测,MI25还是要超过后者约10%的。
之所以能有这么大的领先优势,主要原因是AMD的VEGA架构加入了快速堆叠运算(Rapid Packed Math/RPM),其可以在单个FP32 ALU内处理一对FP16浮点操作,如果两个FP16操作彼此兼容的话,就可以打包到一起作为FP32进行处理,由此带动峰值吞吐能力的翻倍。因此我们看到,MI25的FP16高达25 TFLOPS,达到了FP32的两倍。
AMD本以为胜券在握,可没想到NVIDIA在今年5月便放出了更新更快的加速卡--Tesla V100,这款加速卡不仅有着高达15 TFLOPS的史上最高单精度性能,还有着专为深度学习打造的Tensor Core,其可提供120 TFLOPS 的浮点张量运算性能,具体来说,在深度学习的推断方面,相比于Tesla P100上的FP16操作,其可以实现最高6倍速的峰值TFLOPS,这也就是说在深度学习能力上,V100是有着压倒性的优势的。

此外,这两个GPU都支持16GB HBM2,但是V100能够支持900Gbps的存储带宽,这几乎是MI25的484Gbps存储带宽的2倍,更不用说NVLink带来的性能加成了,而MI25同V100相比唯一的优势就剩价格了。综上所述,Instinct的确为AMD开辟了一条顺应时代的新出路,但同深耕AI和深度学习多年的NVIDIA相比,这只能算是起步。
Pro:攀登专业卡的巅峰
Radeon Pro显卡系列的前身是FirePro
- 台积电满脸“苹果光”(05-06)
- 智能手机陷入“千机一面”怪圈(06-08)
- CPU/APU:一场无声的反垄断技术较量(06-21)
- 移动设备纷纷采用多核CPU遭质疑:性能过剩(01-12)
- 系统级芯片SoC真的能取代传统CPU?(04-26)
- 国产CPU:放手一搏正当时(05-11)