一文总结AMD Vega架构变革史,Vega显卡真的能实现计算和游戏的大一统吗?
这也是没办法,主机性能就是这么多)。
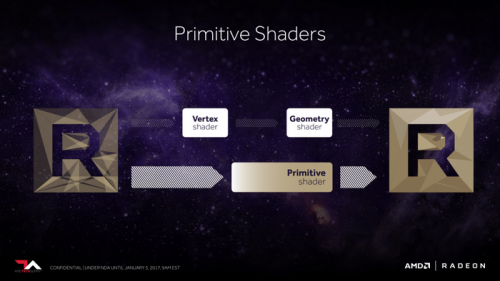
提升几何计算性能的另一个方法就是让GPU可以同时控制更多的着色器引起,因此加入了名位"Intelligent Workgroup Dostributor"(智能工作组分发器)的单元,该分发器可以实现对更多的着色器引擎的控制,并且可以根据负载情况智能地在各引擎之间均衡分配几何计算任务。
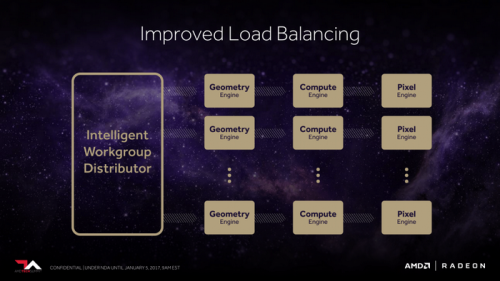

最终AMD在Vega架构显卡上实现了两倍的每时钟周期几何性能提升
新一代像素引擎:
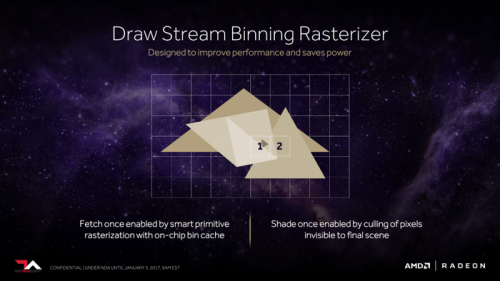
最后一部分的改进就是针对像素着色引擎进行优化,并且将其命名为Draw-streaming binning rasterizer(渲染流分档光栅器),其工作原理和之前的几何渲染引擎很相像,也是通过预先识别出无需出现、不必要的被遮掩像素,直接把这部分像素渲染计算剔除掉,以此达到更加高效的像素渲染性能。也能帮助显卡减少工作量、发热、耗电量,间接地提升了性能以及能耗比。
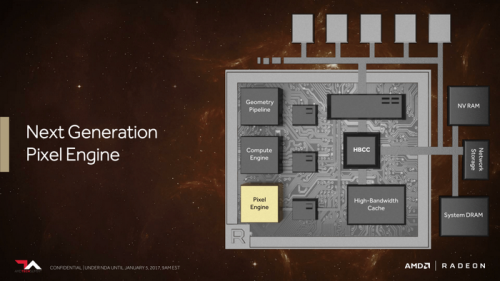
翻看前面的PPT,你会发现像素着色引擎通过L1缓存直接与L2缓存相连,后端渲染单元可以直接访问二级高速缓存,减少了清空缓存后在需要的时候重读显存数据,对于延后式渲染技术的性能有不少提升,特别适用于VR渲染应用。不过由于渲染流分档光栅器不是Vega架构中必须项,游戏开发者可以按照实际情况来觉得是否采用这个技术,换而言之就是,目前目前已有的游戏都适用渲染流分档光栅器,需要游戏开发者针对性优化,才能体现其威力。
目前AMD所透露的Vega信息全都在这里了,可以看得出AMD这次在Vega上并没有打算堆晶体管数目来提高性能,而是另辟蹊径去提高每一个单元的效率,不做无用功。
那么现在我们能看到那几款Vega架构的产品呢?AMD Vega架构显卡产品线:
Radeon Instinct MI25:
Radeon Instinct MI25属于高性能计算卡,拥有64组NCU单元,换算过来就是4096个SP流处理器,配合16GB的HBM2显存,显存带宽高达484GB/s,目前推测其基础频率约为1500MHz。半精度浮点性能有了很大进步,达到了24.6TFLOP,而单精度也有12.3TFLOPS,双精度性能为768GFLOPS,在半精度、单精度性能上都完美超越了Tesla P100-16,不过却比不上NVIDIA新发布的Tesla V100,后者的半精度性能已经飙升至30TFLOPS水平。
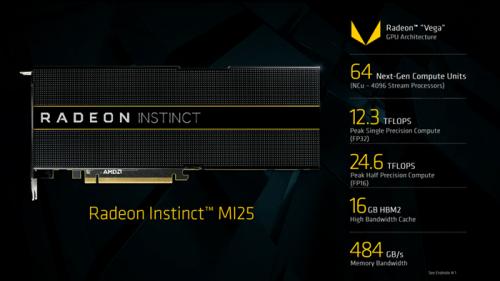
适合密集型计算、高性能深度计算上
AMD Radeon Vega Frontier:
Radeon Vega Frontier Edition属于专业绘图卡,通用有64组NCU单元,16GB HBM2显存,显存带宽480GB/s,单精度与双精度性能均好于Radeon Instinct MI25计算卡,FP32单精度浮点性能12.5TFLOPS,FP16半精度浮点性能25TFLOPS。


RX Vega:
RX Vega就是我们零售市场上的游戏卡,AMD对于Vega游戏卡信息守口如瓶,目前尚未知道有多少款Vega游戏卡产品。不过可以确定的是,最高阶RX Vega同样会有64组NCU单元,即4096个流处理器,HBM 2显存减配至8GB(应该是单颗粒8GB),因此显存位宽同样为2048Bit,至于显存带宽483GB/s。

距离RX Vega发布也只剩下三天时间了,这一次小超哥微信9501417也将会亲赴美国洛杉矶参加AMD Radeon Vega&Ryzen Threadripper Tech Day,第一时间为大家来详细消息。
总结:
Vega架构上的变革无疑是为使用多年的GCN架构注入了新的血液,AMD也因此有资本与NVIDIA在高端显卡上一较高下,就目前泄露出来的跑分成绩来看,RX Vega至少有GTX 1080的水平,如果价格合适,并且能大量投放到市场中,相信AMD也能重回荣光,努力向锐龙处理器学习吧,大家都等着Vega显卡呢。
此外,从Vega中的HBCC、加入FP16半精度单元,我们都看到AMD想在Vega上实现游戏与计算的大一统,技术既能用于游戏处理上,也能成为专业卡、计算卡,挖掘其深度计算能力。
其实我们很欣慰看到这种创新推进力,毕竟有创新才有进步,有进步竞争对手才有压力,市场才有有充分的竞争力,最终收益的还是我们这些玩家。
- 中国正探寻如何快速进驻HPC芯片领域(03-23)
- 一季度AMD全球处理器市场份额遭英特尔蚕食(07-01)
- 显卡市场份额之争 AMD逐渐让位NVIDIA(08-04)
- AMD 2016-2017 x86处理器路线图曝光(05-08)
- AMD结合显示与传统芯片力拚数据中心市场(05-18)
- 通过创新架构和电源技术提升处理器能效(08-05)