ARM Cortex-A55: 从端到云实现高效能

高级特性和更高的性能可满足基础设施市场的需求
行业领先的效率让 Cortex-A55 在基础设施市场卓尔不群。以太网供电 (PoE) 无线接入点以及安装在后视镜上的发热受限的汽车解决方案等应用均可利用热效率极高的 Cortex-A55 在特定的发热范围内提供最高性能。在 5G 远程无线电头端 (RRH),Cortex-A55 CPU 还能够在特定功率范围内最大限度增加网络吞吐量。
从端扩展至云

合适的尺寸和计算性能可满足各类需求
除了性能与效率以外,Cortex-A55 的物理芯片尺寸以及计算性能也具有极高的扩展性。为此,它包含了多个 RTL 配置选项,从而使可配置容量达到了 Cortex-A53 的十倍。事实上,它拥有 3,000 多种独特的配置,因而成为了史上最具扩展性的 Cortex-A CPU。
Cortex-A55 延续了 Cortex-A53 的灵活性,具备 NEON、Crypto 以及 ECC (纠错码) 等选项,但是也采用了新的实用配置选项。例如,专用二级高速缓存的可配置容量从 64KB 到 256KB 不等,可带来 10% 的性能提升。专用二级高速缓存能够很好地提升性能,而且它无疑会成为诸多市场的默认之选,它还被设计成了可选项,以便在物联网等对尺寸敏感的市场上进一步减小芯片尺寸。
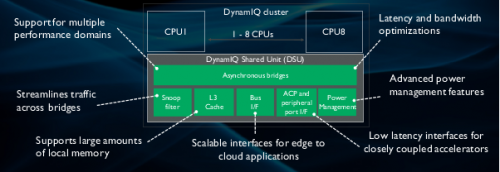
DynamIQ 共享单元 (DSU) 中新特性详解
DSU 无论在 Cortex-A55 还是在 Cortex-A75 上都很常见。它包含更多的配置选项,可根据用户自身的应用情况进行定制。例如 CPU 之间共享的三级高速缓存可从 0KB 扩展至最大 4MB。它还通过 AMBA 5 ACE 或 CHI 支持多用途接口选项,从而可用于更广泛的系统。加速器相干性端口 (ACP) 和低延迟外围端口 (PP) 也被集成到 DSU 当中,这让紧密耦合的加速器能够连接至 Cortex-A55 以便处理通用计算。这些特性加上 Cortex-A55 的机器学习功能,让更多的计算能够在更靠近物联网网关应用"端"的地方执行。
囊括诸多先进特性,可用于各类新兴应用

加速各个领域中的人工智能应用
人工智能会越来越普及,这已不是什么新鲜事。引申开来,我们的设备运行机器学习任务也会变得十分普遍。有多种方法可以在芯片上实现机器学习的处理,然而 CPU 在这方面拥有独特的优势。CPU 可进行通用计算,因此它可以运行到人工智能应用的芯片当中。目前机器学习和人工智能持续换代,固定功能的硬件不但价格昂贵,而且对机器学习而言容易过时。
对 Cortex-A55 NEON 流水线的改进和新增的机器学习指令意味着 Cortex-A55 在矩阵乘法运算方面的机器学习性能比Cortex A53要高出很多。最近发布的 ARM 计算库(ARM Compute Libraries)是专为 ARM Cortex-A NEON 和 Mali GPU IP 而优化的入门级软件函数集,它也可以应用于 Cortex-A55 NEON 并进一步提升其机器学习性能!

Cortex-A55 可打造更安全的自主系统
Cortex-A55的可靠性、可用性和可服务性 (RAS) 特性也很高,这些特性使其能够服务于基础设施以及汽车等各个领域。对汽车市场而言,Cortex-A55 的安全性现已得到提升。它在每一级高速缓存上均提供可选的 ECC 和奇偶校验特性,而且还支持"data poisoning",这种方法可推迟已检测到的、不可纠正的错误,适用于更有弹性的系统。它还是首款在避免系统故障方面采用全新设计流程的 Cortex-A 系列 CPU,因而在搭配 Cortex-R52 的情况下十分适合 ASIL D 应用。
深度嵌入高级电源管理特性
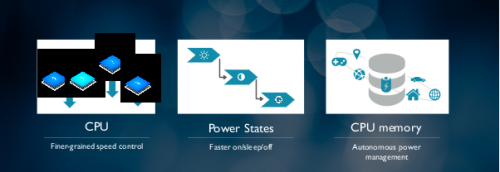
高级电源管理特性可提升节能性
Cortex-A55 具备诸多全新的电源特性,例如硬件控制状态转换能够更快地从 ON 转换至 OFF。Cortex-A55 还能够根据当前运行的应用程序自主地关闭三级高速缓存。对于 VR 等需要更多内存的重载型应用程序,三级高速缓存会完全打开。然而对于音乐播放等完全驻留在一级和二级高速缓存中的轻载型应用程序而言,三级高速缓存会被关闭。额外还有两种功率模式用于重载和轻载之间的应用情形。
现在还可以创建单颗 CPU 或 CPU 群组,其中每一颗 CPU 都处于集群内各自独立的电压域中,因此能够更精细地动态提升电压和频率。这有两大好处:首先,它让设计师能够进一步调节系统,从而实现最佳的性能和节能性。其次,这还意味着 DynamIQ 系统能够更轻松地紧密匹配设备多变的发热限制,因此可以最大限度发挥性能。
big.LITTLE处理的新时代
big.LITTLE 技术自 2011 年问世以来一直是异构处理的代名词。因此当今市面上每三台安卓 ARMv8 设备中就有两台依赖 big.LITTLE 技术来实现功率和性能优化。DynamIQ big.LITTLE 是 DynamIQ 系统的新一代异构计算技术。
它让设计师能够利用 Cortex-A75 "大" CPU 和 Cortex-A55 "小" CPU 打造出充分集成的解决方案,大小 CPU 在物理上位于单一 CPU 集群中。所有的软件线程迁移和由此造成的大小 CPU 之间的高速缓存窥探(cache snoop)现在均发生在该集群内。与 Cortex-A73 相比,Cortex-A75 CPU 可以用于频率更高的使用场合,同时利用Cortex-A55 依旧保持持续的 DVFS 曲线。这是 big.LITTLE 系统的一项重要设计要求。这些特性合在一起,与上一代 big.LITTLE 技术相比,可大幅提升峰值性能、持续性能以及智能功能。
- 今年IT市场规模预计将扩大4.8%(03-05)
- 中星微邓中翰两会议案:继续推进自主创新法(03-11)
- CMET2011:云计算与医疗电子技术推进低成本健康工程(04-28)
- 云计算推动服务器处理器热销(04-29)
- 全球消费电子将迎来第三次变革浪潮(07-05)
- 赛迪顾问:未来三年IT服务市场年增长率超20%(09-05)