都是瞄准人工智能市场,谷歌TPU与GPU、FPGA到底有啥不同?
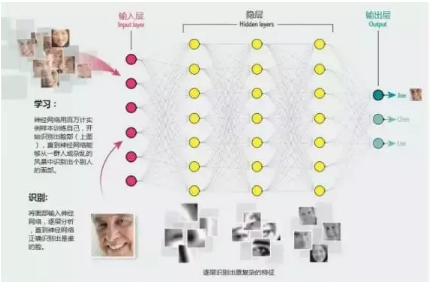
不难想象,由于每一层分析的时候都要对极大量的数据进行运算,因此对处理器的计算性能要求极高。这时CPU的短板就明显的体现出来了,在多年的演化中,CPU依据其定位需要不断强化了进行逻辑运算(If else之类)的能力。相对的却没有提高多少纯粹的计算能力。因此CPU在面对如此大量的计算的时候难免会感到吃力。很自然的,人们就想到用GPU和FPGA去计算了。
目前的深度学习硬件设备还有哪些?与传统CPU有何差异?
一.FPGA
FPGA最初是从专用集成电路发展起来的半定制化的可编程电路,它无法像CPU一样灵活处理没有被编程过的指令,但是可以根据一个固定的模式来处理输入的数据然后输出,也就是说不同的编程数据在同一片FPGA可以产生不同的电路功能,灵活性及适应性很强,因此它可以作为一种用以实现特殊任务的可再编程芯片应用与机器学习中。
譬如百度的机器学习硬件系统就是用FPGA打造了AI专有芯片,制成了AI专有芯片版百度大脑--FPGA版百度大脑,而后逐步应用在百度产品的大规模部署中,包括语音识别、广告点击率预估模型等。在百度的深度学习应用中,FPGA相比相同性能水平的硬件系统消耗能率更低,将其安装在刀片式服务器上,可以完全由主板上的PCI Express总线供电,并且使用FPGA可以将一个计算得到的结果直接反馈到下一个,不需要临时保存在主存储器,所以存储带宽要求也在相应降低。
二.GPU
英伟达(NVIDIA)制造的图形处理器 (GPU)专门用于在个人电脑、工作站、游戏机和一些移动设备上进行图像运算工作,是显示卡的"心脏"。
1.GPU与CPU的区别
本身架构方式和运算目的的不同,导致英特尔制造的CPU 和 GPU之间有所区别。
GPU之所以能够迅速发展,主要原因是GPU针对密集的、高并行的计算,这正是图像渲染所需要的,因此 GPU 设计了更多的晶体管专用于数据处理,而非数据高速缓存和流控制。
与CPU相比,GPU拥有更多的处理单元。GPU和CPU 上大部分面积都被缓存所占据有所不同,诸如GTX 200 GPU之类的核心内很大一部分面积都作为计算之用。如果用具体数据表示,大约估计在 CPU 上有 20%的晶体管是用作运算之用的,而(GTX 200)GPU 上有 80%的晶体管用作运算:
GPU 的处理核心 SP 基于传统的处理器核心设计,能够进行整数,浮点计算,逻辑运算等操作,从硬体设计上看就是一种完全为多线程设计的处理核心,拥有复数的管线平台设计,完全胜任每线程处理单指令的工作。
GPU 处理的首要目标是运算以及数据吞吐量,而 CPU 内部晶体管的首要目的是降低处理的延时以及保持管线繁忙,这也决定了 GPU 在密集型计算方面比起 CPU 来更有优势。
2.GPU+CPU异构运算
就目前来看,GPU不是完全代替CPU,而是两者分工合作。
在 GPU 计算中 CPU 和 GPU 之间是相连的,而且是一个异构的计算环境。这就意味着应用程序当中,顺序执行这一部分的代码是在 CPU 里面进行执行的,而并行的也就是计算密集这一部分是在 GPU 里面进行。
异构运算(heterogeneous computing)是通过使用计算机上的主要处理器,如CPU 以及 GPU 来让程序得到更高的运算性能。一般来说,CPU 由于在分支处理以及随机内存读取方面有优势,在处理串联工作方面较强。在另一方面,GPU 由于其特殊的核心设计,在处理大量有浮点运算的并行运算时候有着天然的优势。完全使用计算机性能实际上就是使用 CPU 来做串联工作,而 GPU 负责并行运算,异构运算就是"使用合适的工具做合适的事情"。
只有很少的程序使用纯粹的串联或者并行的,大部分程序同时需要两种运算形式。编译器、文字处理软件、浏览器、e-mail 客户端等都是典型的串联运算形式的程序。而视频播放,视频压制,图片处理,科学运算,物理模拟以及 3D 图形处理(Ray tracing 及光栅化)这类型的应用就是典型的并行处理程序。
三.FPGA和GPU
实际的计算能力除了和硬件的计算速度有关,也同硬件能支持的指令有关。我们知道将某些较高阶的运算分解成低阶运算时会导致计算的效率下降。但如果硬件本身就支持这种高阶运算,就无需再将其分解了。可以节省很多时间和资源。
FPGA和GPU内都有大量的计算单元,因此它们的计算能力都很强。在进行神经网络运算的时候速度会比CPU快很多,但两者之间仍存在一些差别。GPU出厂后由于架构固定硬件原生支持的指令其实就固定了。如果神经网络运算中有GPU不支持的指令,比如,如果一个GPU只支持加减乘除,而我们的算法需要其进行矩阵向量乘法或者卷积这样的运算,GPU就无法直接实现,就只能通过软件模拟的方法如用加法和乘法运算的循环来实现,速度会比编程后的FPGA慢一些。而对于一块FPGA来说,如果FPGA没有标准的"卷积"指令,开发者可以在FPGA的硬件电路里"现场编程"出来。相当于通过改变FPGA的硬件结构让FPGA可以原生支持卷积运算,因此效率会比GPU更高。
其实讲到这里,我们已经比较接近谷歌开发TPU的原因了。TPU是一种ASIC,这是一种与FPGA类似,但不存在可定制性的专用芯片,如同谷歌描述的一样,是专为它的深度学习语言Tensor Flow开发的一种芯片。因为是专为Tensor Flow所准备,因此谷歌也不需要它拥有任何可定制性了,只要能完美支持Tensor Flow需要的所有指令即可。而同时,TPU运行Tensor Flow的效率无疑会是所有设备中最高的。这就是谷歌开发TPU的最显而易见的目的:追求极致的效率。
一场人工智能芯片之争在谷歌发布这款专用机机器学习算法的专用芯片-TPU之后正式拉开序幕。谁能走在人工智能的前面,谁能主导未来人工智能发展趋势,掌握核心技术,谁就能赢得这场战争的胜利吧!
- 大尺寸面板价格不涨反跌 市场供需失衡难落幕(07-29)
- Fairchild推出全新品牌,标志着公司的重大转型(03-19)
- 飞兆半导体附属公司崇贸科技荣获发明创作奖(05-14)
- Fairchild通过收购Xsens将战略步伐跨入 快速增长的3D运动追踪市场(05-15)
- Fairchild宣布2014年度北美洲和亚洲功率技术研讨会时间表(04-15)
- Fairchild与Xsens的结合水到渠成(06-09)