谷歌的TPU芯片效能到底能不能超越CPU与GPU,我们看图说话
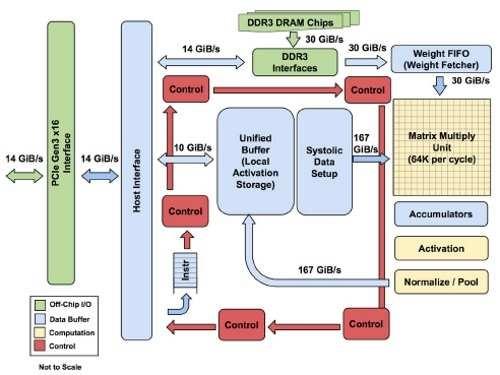
图3:ASIC芯片支援PCIe Gen 3 x16汇流排,并搭载DDR3存储器
开发人员掌握多元化讯息
该报告中提到,研究人员受到热门的ImageNet比赛吸引,已经变得过于投入卷积神经网路(CNN)。现实世界的应用采用更广泛的神经网路类型,报告并强调,多层感知(MLP)占Google AI开发工作的61%。"虽然大部份的架构师一直在加速CNN设计,但这部份只占5%的工作负载。"
"虽然CNN可能很常见于边缘装置,但卷积模型的数量还赶不上纳米中心的多层感知(MLP)和长短期存储器(LSTM)。我们希望架构师尽可能地加速MLP和LSTM设计,这种情况类似于当许多架构师专注于浮点运算效能时,大部份的主流工作负载仍由整数运算主导。"
Jouppi说:"我们已经开始与一些大学合作,扩大提供免费模式。"但他并未透露内容细节。
这篇报告回顾了二十多年来神经网路的相关纳米,包括其竞争对手--微软(Microsoft)基于FPGA的Catapult计划,加速了网路作业。最初的25W Catapult在200MHz时脉上运作3,926个18位元MAC,并且以200MHz 时脉速度执行5MB存储器。Google表示,以Verilog语言设计的韧体比起使用TensorFlow软体来说效率更低。

图4:TPU卡可插入服务器的SATA插槽上
TPU计划于2013年开始,当时并以FPGA进行了试验。该报告中提到:"我们舍弃FPGA,因为我们当时发现它和GPU相比,在效能上不具竞争力,而TPU比起GPU在相同速度或甚至更快的速度下,可以达到更低的功耗。"
尽管二十多年来,神经网路终于在最近从商用市场起飞了。
Jouppi说:"我们所有人都被这蓬勃发展的景象吓到了,当初并未预期到会有如此大的影响力。一直到五、六年以前,我都还一直抱持怀疑态度…而今订单开始逐月增加中。"
相较于传统途径,深度神经网路(DNN)已经让语音辨识的错误率降低了30%,这是二十年来最大的进步。这让ImageNet影像辨识竞赛中的错误率从2011年的26%降至3.5%。
该报告结论还提到,"神经网路加速器存在的理由在于效能,而在其演进过程中,如何达到良好的直觉判断,目前还为时过早。"
- 台积电满脸“苹果光”(05-06)
- 智能手机陷入“千机一面”怪圈(06-08)
- CPU/APU:一场无声的反垄断技术较量(06-21)
- 移动设备纷纷采用多核CPU遭质疑:性能过剩(01-12)
- 系统级芯片SoC真的能取代传统CPU?(04-26)
- 国产CPU:放手一搏正当时(05-11)