探究人工智能,谷歌/IBM/微软/英特尔都有啥宝贝?
现在科技领域最火的是什么?人工智能、机器学习、深度神经网络显然是热点中的热点。太多我们认识中的不可能,被强大的机器学习、人工智能给颠覆了。比如去年Deepmind的AlphaGo就在围棋领域战胜了世界冠军李世石,让人感觉不可思议,在AlphaGo之前的软件,连业余六段左右的高手都赢不了,更遑论顶级职业选手!如果你是程序高手,有想法,是不是可以自己在家也能玩机器学习呢?稍微研究的深入一点,发现完全不是这么回事儿。
源起于DIY的欲望
笔者有朋友的孩子想在围棋上有所建树。他发现,下围棋的课外辅导班要花钱,找人指导下棋也要花钱,并且随着孩子棋力水涨船高,是以几何级数的价格增加的。他又听说人工智能的围棋已经很厉害了,能不能干脆一次性投资,弄个下围棋很厉害的软件与配置,这样就相当于一直与一个高手下对手棋,对棋力增长是有好处的。
日本的天顶围棋(Zen)6软件已经有了很强的棋力

前几天DeepZen Go挑战赵治勋九段以失败告终

4路Titan X,2路至强E5已经很强……
我一想,这逻辑也说得通,AlphaGo不也赢了人类高手并且人类在学AlphaGo下棋吗?于是找了找,目前使用6700K处理器的计算机跑日本围棋软件Zen,可以有业余五六段的棋力,但这显然不是他想要的。前几天与赵治勋对弈的deepzen,配置要高很多,核心是2个至强E5 V4与4个Titan X做GPU计算,虽然不敌赵治勋,但毕竟显示出来了可观的棋力。

想拜AlphaGo为师?起码目前还不可能做到
前几天Deepmind团队又放出了消息,棋力大涨,明年初开始重新下棋。我突发奇想,反正这老哥也不差钱,如果谷歌团队公开了软件,会不会可以自己弄个单机版的AlphaGo?天天和比李世石更厉害的AI下围棋肯定涨棋力更快啊。但是仔细一研究,不是这么回事儿,AlphaGo用的处理器,买!不!到!
谷歌人工智能的处理器TPU
这个表是谷歌发表《自然》杂志论文的时候给出的配置与棋力预估。当时只是说要多少CPU与GPU以及对应的棋力。如果说一个CPU对应一个核心,现在的至强E5V4,已经有22核心的产品了,而如果是对应一个CPU,那么48个CPU可能就要很贵的刀片服务才行了,当然了有万能的淘宝,二手机架式的刀片服务器也贵不到哪儿去。
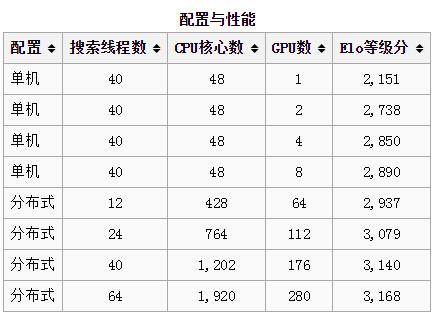
Deepmind团队公布的当时的配置,似乎让人觉得单机版的AlphaGo并非遥不可及,且棋力足够

在围棋上战胜人类的AlphaGo就运行在这个系统上
在今年5月,谷歌又公布了其自己定制的处理器的细节。谷歌用的并非Intel或是AMD的处理器,而是自己针对机器学习优化过的处理器,并命名为"张量处理单元(tensorflow process unit,TPU)。而AlphaGo就是构建在TPU上的。

TPU在规格上并不大,但没有更多细节
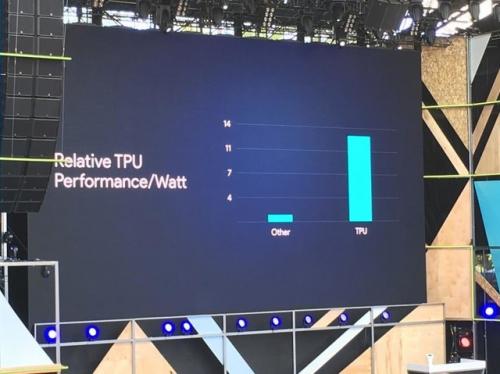
运行神经网络,TPU的每瓦性能更高
TPU的作用就是给机器学习的神经网络加速。谷歌对TPU具体怎么工作、有哪些指令都语焉不详,作为局外人能获得的信息有限,甚至连哪个半导体工厂代工的都没人知道。谷歌说TPU是一种辅助运算工具,还是要有CPU和GPU的。核心在于TPU是8位的,而我们的处理器是64位,因此在神经网络计算上,TPU的单位功耗贡献的计算能力上,要比传统的CPU有很大的优势,更适合大面积的分布式的计算。
IBM的TrueNorth
IBM对于计算机模拟神经的计算启动,可能要比其它的企业更早。而研究的起源,也不能说全自主的,而是有外界的因素,那就是DARPA(国防部高级计划研究局)。

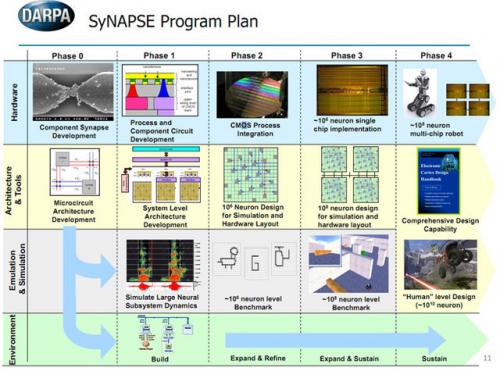
DARPA的SyNapse项目
IBM研究模仿大脑的神经计算,也来自于DARPA。自从2008年以来,DARPA给了IBM5300万美元用来研究SyNapse(Systems of Neuromorphic Adaptive Plastic Scalable Electronics,自适应可伸缩神经系统,缩写的SyNapse单词正好是触突,神经的构成部分),而TrueNorth只是这个项目的一部分成果而已。
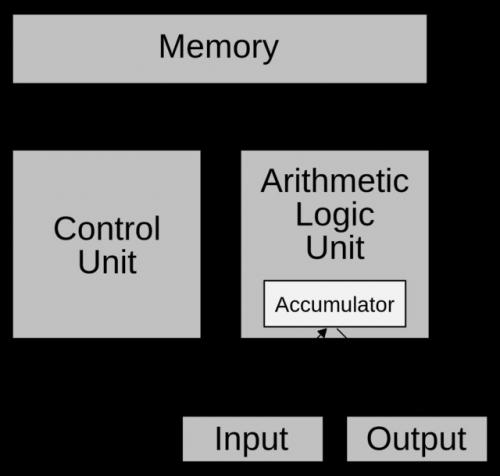
我们今天计算机的冯·诺依曼架构

IBM的TrueNorth芯片
这项研究的意义是,我们今天的计算机,处理和存储是分离的,高度依赖总线进行数据传输交换,即所谓冯·诺依曼体系。我们大脑的处理方式则不同,要知道神经的传输速度并不快,但是大脑的优势是脑细胞多,靠的是大量分布式的处理,现有的模仿大脑的办法,还是依赖处理器的数量堆积,所以能效比不高,而IBM的TrueNorth则是要打破这个屏障,在芯片上就完成对神经元的模拟。2011年的原型就有256个神经元的原型。
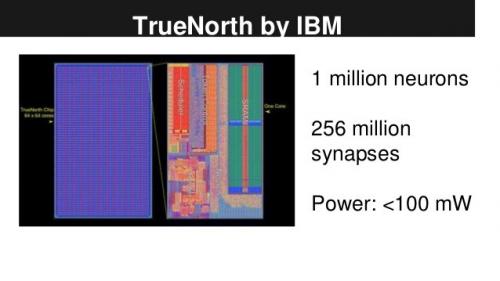
TrueNorth的架构,左边是256个核,右边是每个核的结构,用来模拟人的大脑

计算机识别动态视频中的每个车、每个人,以前只在电影和美
- 美博客称谷歌摩托移动交易可能成为一场灾难(08-16)
- 谷歌再加码投资可再生能源(10-10)
- 谷歌苹果在美手机市场排前两位(12-31)
- 谷歌收购摩托罗拉 国产手机厂商将继续受益(05-23)
- 未来Android平台可能走向半封闭(05-26)
- 苹果VS谷歌,谁是最后的赢家?(06-26)