英伟达在人工智能领域的好日子结束了?英特尔Xeon Phi处理器正迎面狙击
近期,英特尔公司数据中心事业部的主管Diane Bryant在于台北举行的Computex电脑展上表示,在运行ML(机器学习)或者DL(深度学习)工作任务上,英特尔公司的Knights Landing("KNL")处理器完美契合了AI(人工智能)的需要。KNL代表了英特尔的第二代(x200)Xeon Phi产品系列。

根据Bryant的说法,由于英特尔最新的Xeon Phi协处理器拥有多达72个内核,而且每个内核有两个用于提供更好的单核浮点运算性能的英特尔AVX-512 SIMD处理单元,所以这些处理器非常适合运行机器学习/深度学习工作任务。但是,这些处理器能否在最终表现上超过英伟达最新的Tesla GPU P100加速器还有待观察,据业内人士看法,Tesla GPU P100加速器是目前最适合处理机器学习/深度学习工作任务的计算单元。
英伟达需要保持其竞争优势
通过性能强大的图形处理器以及精心设计的算法,英伟达公司几年前就加入了机器学习/深度学习的潮流中。尽管目前尚无法断定英特尔最新的Xeon Phi协处理器是否能够取代英伟达公司在基于最新的帕斯卡Pascal架构打造的GP100 GPU的基础上设计的Tesla GPU P100加速器,但是毫无疑问的是,和以前相比,英特尔已经取得了巨大的进步。
帕斯卡是英伟达公司推出的第五代CUDA架构。该公司花了三年时间,斥巨资30亿美金打造了这款Tesla P100,目前已经进入量产阶段。IBM、Cray公司、惠普企业公司以及私人持有的戴尔都已经开始在他们即将推向市场的HPC(高性能计算)服务和超级计算机上使用P100。
为高性能计算和超级计算机提供所需的计算能力并不是什么新鲜事儿。英伟达公司针对其早先版本的Tesla K80 GPU加速器和英特尔的Xeon Phi进行了对比,表示,在不改写CPU代码的情况下简单地在Xeon Phi上重新编译并运行应用,通常并不能起到加速作用,反而会减速。此外,对GPU进行编程和对Xeon Phi进行编程需要花费的功夫差不多,但是GPU能够提供更佳的性能,英伟达曾经表示:
"一旦您看清了这些事实,便能更好地理解加速计算应用为什么在不断涌现。今天,在开发工作强度基本相同的条件下,GPU能够实现双倍的性能。对并行代码的加速而言,GPU是最合理的选择。在某种程度上,这也是为什么科研人员今年以来发表的关于GPU的文章数能达到关于英特尔的Xeon Phi文章数的10倍的原因,也能说明为什么在高性能计算系统中,GPU的受欢迎程度能达到Xeon Phi的20倍之多。"
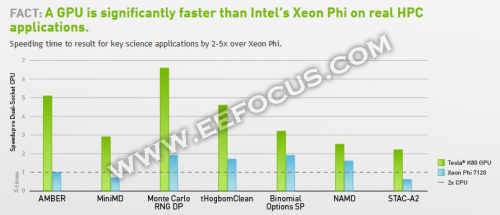
不过,这已经是三年之前的旧事了。现在,由于英特尔大幅度改进了其最新版Xeon Phi协处理器和支持工具,今天的场景已经发生了彻底的变化。在下面的章节中,我将试图评估一下在这次回合的较量中,英特尔的Xeon Phi能否在运行机器学习/深度学习工作任务中替代英伟达的GPU。
这一次,英特尔的准备更加充分
英特尔的KNL x200 Xeon Phi能够提供每秒3万亿次64位双精度浮点运算(FP64)的计算能力,尽管消费者级别的GPU不支持双精度运算,但是英伟达的Tesla P100依然凭借每秒5.3万亿次FP64运算的计算能力击败了KNL Xeon Phi。
但是,虽然英伟达的Tesla P100在FP64运算能力这个单一指标上更胜一筹,但是如果从性价比的角度来衡量的话,从系统级别来看,这种性能差距其实是微不足道的。英伟达要在运行机器学习/深度学习工作任务上击败英特尔,是一件相当困难的事情,原因有三,分述如下:
英特尔的AVX-512(高级矢量扩展512)SIMD处理单元能够支持如浮点乘法和混合乘加等机器学习/深度学习算法。 英特尔在其最新的Xeon Phi上添加了自引导功能,所以通过一个可自启动的处理器插槽便可以启动OS。 最后,凭借英特尔独有的支持Xeon Phi的全路径架构(OPA)制造技术,这颗处理器将成为超级计算的猛兽。在第二代Xeon Phi和Tesla P100的编程工作强度相当的情况下,英伟达的Tesla P100可能无法再像三年前那样在性能上大幅度领先Xeon Phi。事实上,英特尔提供了MKL(数学核心函数库),使得并行化机器学习/深度学习的代码变得比之前容易多了。比如,英特尔最新版本的MKL-MKL 2017公测版,包含了一系列优化机器学习/深度学习神经网络的新工具。
机器学习/深度学习工作任务的更佳选择
从原始计算能力指标上来比较,英伟达的Tesla P100显然更胜一筹。但是,运行机器学习/深度学习工作任务时,原始计算能力并不总是优先级最高的指标。随着云计算对机器学习/深度学习研究的影响日益加深,一个具备巨大的存储能力的全方位高性能计算平台才是研究人员真正所需要的,此外,更好的优化工具也是必须的。
英特尔 英伟达 人工智能 Xeon Phi P100 相关文章:
- 英特尔总裁唱衰晶圆代工业(02-23)
- ARM手机芯片市场份额已超90% 英特尔倍感压力(03-17)
- 中国正探寻如何快速进驻HPC芯片领域(03-23)
- 业界不惧英特尔3D晶体管来势汹涌(05-09)
- 第一季度全球20大芯片厂商排行榜出炉 (05-20)
- Q1全球20大芯片厂商排行榜出炉 英特尔夺回优势(05-20)