CPU/GPU有场大戏要开演,英特尔/IBM/AMD/NVIDIA谁更有帝王相?
3、PCI-E 4.0姗姗来迟,厂商自研新总线
伴随着CPU、GPU计算性能的飞速增长,PCI-E总线也要有相应的准备,不过最新一代PCI-E 4.0总线技术已经推迟了,原定于2015年上半年发布最终规范,但现在来看PCI-E 4.0总线可能要拖到2016年甚至2017年了。
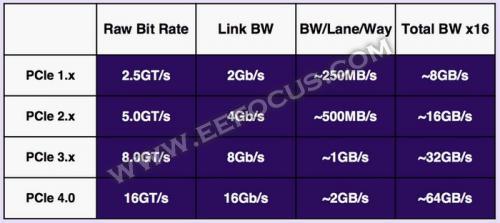
新一代总线具备更高的性能,具体来说, 目前在用的PCI-E 3.0总线速率是8GT/s,Link带宽8Tb/s,每一通道带宽约为1GB/s,x16通道双向带宽32GB/s,而PCI-E 4.0在PCI-E 3.0基础上保持架构不变,速率翻倍到16GT/s,通道带宽提升到2GB/s,x16双向带宽高达64GB/s。
不过PCI-E 4.0面临的问题也不少,除了铜介质速率继续提升的技术难题之外,PCI-E 4.0最大的尴尬之处在于--桌面显卡用不到这么高的带宽,高性能计算领域PCI-E 4.0带宽又不给力。前者很好说,因为从PCI-E 2.0到PCI-E 3.0时代,显卡性能也没有因此受益,PCI-E 3.0 x16带宽已经达到了32GB/s,目前的高端显卡并不需要这么高的带宽,而升级到PCI-E 4.0,64GB/s的带宽对桌面显卡来说也是浪费。

NVIDIA联合IBM开发了NVLink总线技术
如果用到HPC领域,PCI-E 4.0带宽的64GB/s又有点捉襟见肘了,等不及的厂商早已经在暗地里开发新的总线技术,其中NVIDIA跟IBM联合开发了NVLink总线,号称带宽是PCI-E总线的5-12倍,AMD也在开发自家的架构互联技术,带宽超过100GB/s。
无论AMD还是NVIDIA,他们开发的新总线技术带宽可以轻松超过100GB/s,这对服务器产品很有用,但对桌面市场有什么意义呢?值得发烧友关注的就是多卡互联技术,目前AMD、NVIDIA最多能做到的也就是4卡SLI/CF交火,有了NVLink这样的技术,8卡SLI或者CF都是有可能的。
4、GPU架构、工艺升级:不仅拼性能,效能更重要
说完了CPU处理器,我们也不能忽视GPU处理器。作为当前PC中功耗最高的一部分,显卡对游戏性能影响至关重要,但在性能越高=功耗越高这条路上,显卡也面临一个选择--NVIDIA的Maxwell架构证明了显卡性能增长的同时,能耗也可以很低。2016年的GPU不仅要性能,更重要的是效能,我们要看到还是每瓦性能比。
在Maxwell架构之后,NVIDIA将推出新一代的Pascal架构。根据官方在GTC 2015年大会上公布的资料,Pascal显卡将支持3D Memory显存,容量、带宽可达普通显存的2-4倍,而显卡只有标准PCI-E显卡的1/3大小。

Pascal显卡会在2016年问世
至于AMD,由于目前的R200、R300系列显卡大都还在使用GCN架构改款,制程工艺还是28nm工艺,能效方面已经落后NVIDIA的Maxwell架构了,所以2016年AMD也会在GPU领域有大动作--推出了GCN 4.0架构Polaris,制程工艺升级到14/16nm FinFET,同时会搭配HBM 2显存,号称每瓦性能比提升一倍。

2016年AMD的GCN 4.0架构会大幅提升每瓦性能比
AMD还实际演示了Polaris显卡的能效优势,之前使用用Polaris架构的一款中端显卡跟NVIDIA的GTX 950做了对比,同样是在1920x1080 60fps的性能上,Polaris显卡的整机功耗是86W,而GTX 950整机功耗是140W,可见功耗优势非常非常大。
5、新一代高带宽内存:HBM向左,HMC向右
2016年GPU要想提高性能、降低功耗,除了架构改进之外,新一代内存技术也功不可没,其中AMD在去年的Fury显卡上首次使用的HBM内存就是代表,NVIDIA所说的3D显存其实也是HBM技术,不过是HBM 2代技术。与HBM竞争的则是美光主导的HMC内存技术。
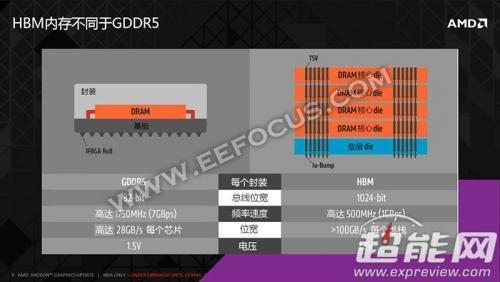
HBM技术带宽更高,功耗更低
对于HBM技术,我们之前做过详细介绍:AMD详解HBM显存:性能远超GDDR5,功耗降50%,面积小94%。简单来说,HBM就是在GDDR5显存无法继续大幅提升频率的情况下换了一种思路,通过提高总线位宽来提高带宽,第一代HBM显存的频率只有500MHz,等效1GHz,远低于目前的GDDR5显存,但带宽高达128GB/s,4颗芯片总计可以带来512GB/s的带宽,远高于主流GDDR5显存。
2016年HBM 2代也来了,JEDEC已经正式批准了HBM 2显存规范,相比第一代HBM,HBM 2可堆栈的层数更多,单颗容量最高可达8GB,频率也翻倍到2Gbps,带宽从128GB/s提高到256GB/s,这样一来布置4组HBM 2显存就可以实现32GB容量、1TB/s的带宽了,次之也有16GB容量,1TB/s带宽,这正好与NVIDIA之前宣称的数据相符。

HMC内存技术
HBM内存技术已经得到了SK Hynix、三星等厂商的支持,另一个内存技术大腕美光的选择不同--显存市场他们继续推改良版的GDDR5X,3D堆栈内存上则选择了HMC(Hybrid Memory Cube),它跟HBM一样都需要使用TSV工艺连接多层DRAM芯片。
性能方面,HMC闪存相比DDR内存依然有足够多的优势,普通DDR3-1600内存双通道带宽不过12.8GB/s,美光之前宣称HMC的性能是DDR3内存的20倍,单通道带宽就有128GB/s(跟HBM 1代相同),同时功耗比DDR3减少70%,占用面积比DDR3减少95%。
HMC阵营实际上也有Intel、三星等其他公司参与,但目前力推HMC的基本上只有美光公司,他们现在推出了2/4GB容量的HMC内存,有两种封装,896-Ball BGA封装的带宽为160GB/s,666-Ball BGA封装的带宽是120GB/s。
- 中国正探寻如何快速进驻HPC芯片领域(03-23)
- 一季度AMD全球处理器市场份额遭英特尔蚕食(07-01)
- 显卡市场份额之争 AMD逐渐让位NVIDIA(08-04)
- AMD 2016-2017 x86处理器路线图曝光(05-08)
- AMD结合显示与传统芯片力拚数据中心市场(05-18)
- 通过创新架构和电源技术提升处理器能效(08-05)