几张图看懂龙芯、飞腾和英特尔芯片的差距
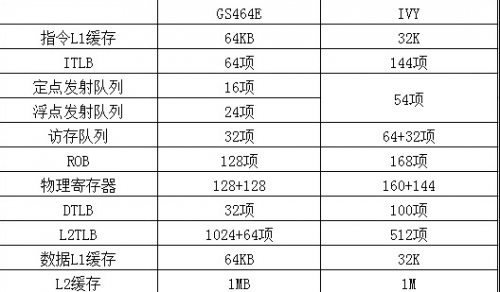
飞腾最新的两款产品和Intel做比较。以GS464E和IVY的差距而言,通过对比下表参数,就能发现原因。
(数据网络收集,仅供娱乐)
如果将GS464E和IVY做对比就能发现,制约GS464E性能的最大的短板在定点发射队列和浮点发射队列上,相对于IVY的54项定点和浮点发射队列,GS464E只有16项定点发射队列,24项浮点发射队列。
龙芯对此也是心知肚明,将正在流片的3A3000,针对GS464E的瓶颈做了改进,将定点发射队列从16项提升到32项,将浮点发射队列从24项提升到32项,并提升了缓存和主频。很显然,虽然龙芯宣称TICK-TOCK,但3A3000相对于3A2000并非单纯的提升主频,定点发射队列和浮点发射队列的提升必然带来IPC的提升。
根据飞腾公布的Spec 2006的模拟器测试,整数为9.6/G。
9.6/G到底是什么水平呢?笔者以Intel作参照,关auto parallel的情况下,haswell 使用GCC5.1 的SPEC 2006的成绩为32分(@3.2G主频)。也就是说,"小米"能接近haswell?
这实在是太"惊悚"了,如果真能做到,就是科技大跃进了。那SPEC2006整数9.6/G的原因何在?根源在于开/关auto parallel。
开auto parallel会导致SEPC2006整数分数增益,因为其将原本单线程执行的程序并行化给多个处理器执行,增益效果取决于编译器、CPU的核心数量等因素。而相当部分常用的代码并不支持auto parallel。因此,目前auto parallel对SPEC跑分更有意义。而"小米"SPEC2006整数高达9.6/G,很有可能就是因为在测试中开auto parallel的结果,那么证据呢?
(数据网络收集,仅供娱乐)
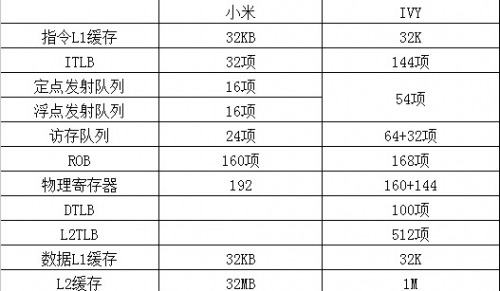
从上表中"小米"和IVY的对比中看,"小米"和IVY还是有不小的差距的,并且和GS464E一样存在定点发射队列和浮点发射队列相对IVY偏少的现状,因此在资源有限的情况下,做出达到haswell水平的概率非常小。
对比"小米"和GS464E,假定两者流水线效率相当的情况下,笔者认为"小米"可能是和GS464E一个等级的微结构,并强于ARM Cortex A57。当然,如果流水线效率不佳,"小米"也可能会逊色于GS464E。而"小米"32M的L2缓存,很有可能是因为针对服务器,甚至高性能计算的产物。
目前,飞腾的"地球"和龙芯3A3000正在流片,期待"地球"和3A3000流片归来后的表现。
- 中国将用龙芯代替美制x86芯片(03-01)
- 国产CPU之乱战 自主化之路去向何方?(05-18)
- 龙芯有了全新架构 中国芯看齐英特尔?(06-05)
- 龙梦称获意法半导体万颗免费CPU 用于新品研发(11-29)
- 龙芯负责人否认“权利金”消息 合作仍待公布(11-29)
- 龙芯电脑用户测试:和X86没区别 没发现故障(01-08)