别小看了手势识别,它就要带来这些改变
二维手势识别
二维手势识别,比起二维手型识别来说稍难一些,但仍然基本不含深度信息,停留在二维的层面上。这种技术不仅可以识别手型,还可以识别一些简单的二维手势动作,比如对着摄像头挥挥手。其代表公司是来自以色列的PointGrab,EyeSight和ExtremeReality。
二维手势识别拥有了动态的特征,可以追踪手势的运动,进而识别将手势和手部运动结合在一起的复杂动作。这样一来,我们就把手势识别的范围真正拓展到二维平面了。我们不仅可以通过手势来控制计算机播放/暂停,我们还可以实现前进/后退/向上翻页/向下滚动这些需求二维坐标变更信息的复杂操作了。
这种技术虽然在硬件要求上和二维手型识别并无区别,但是得益于更加先进的计算机视觉算法,可以获得更加丰富的人机交互内容。在使用体验上也提高了一个档次,从纯粹的状态控制,变成了比较丰富的平面控制。这种技术已经被集成到了电视里,但是目前还是以噱头为主,还不能成为电视的主要常用控制方式。
三维手势识别
接下来我们要谈的就是当今手势识别领域的重头戏--三维手势识别。三维手势识别需要的输入是包含有深度的信息,可以识别各种手型、手势和动作。相比于前两种二维手势识别技术,三维手势识别不能再只使用单个普通摄像头,因为单个普通摄像头无法提供深度信息。要得到深度信息需要特别的硬件,目前世界上主要有3种硬件实现方式。加上新的先进的计算机视觉软件算法就可以实现三维手势识别了。下面就让小编为大家一一道来三维手势识别的三维成像硬件原理。
1、结构光(Structure Light)
结构光的代表应用产品就是PrimeSense公司为大名鼎鼎的微软家XBOX 360所做的Kinect一代了。
这种技术的基本原理是,加载一个激光投射器,在激光投射器外面放一个刻有特定图样的光栅,激光通过光栅进行投射成像时会发生折射,从而使得激光最终在物体表面上的落点产生位移。当物体距离激光投射器比较近的时候,折射而产生的位移就较小;当物体距离较远时,折射而产生的位移也就会相应的变大。这时使用一个摄像头来检测采集投射到物体表面上的图样,通过图样的位移变化,就能用算法计算出物体的位置和深度信息,进而复原整个三维空间。
以Kinect一代的结构光技术来说,因为依赖于激光折射后产生的落点位移,所以在太近的距离上,折射导致的位移尚不明显,使用该技术就不能太精确的计算出深度信息,所以1米到4米是其最佳应用范围。
2、光飞时间(Time of Flight)
光飞时间是SoftKinetic公司所采用的技术,该公司为业界巨鳄Intel提供带手势识别功能的三维摄像头。同时,这一硬件技术也是微软新一代Kinect所使用的。
这种技术的基本原理是加载一个发光元件,发光元件发出的光子在碰到物体表面后会反射回来。使用一个特别的CMOS传感器来捕捉这些由发光元件发出、又从物体表面反射回来的光子,就能得到光子的飞行时间。根据光子飞行时间进而可以推算出光子飞行的距离,也就得到了物体的深度信息。
就计算上而言,光飞时间是三维手势识别中最简单的,不需要任何计算机视觉方面的计算。
3、多角成像(Multi-camera)
多角成像这一技术的代表产品是Leap Motion公司的同名产品和Usens公司的Fingo。
这种技术的基本原理是使用两个或者两个以上的摄像头同时摄取图像,就好像是人类用双眼、昆虫用多目复眼来观察世界,通过比对这些不同摄像头在同一时刻获得的图像的差别,使用算法来计算深度信息,从而多角三维成像。
在这里我们以两个摄像头成像来简单解释一下:
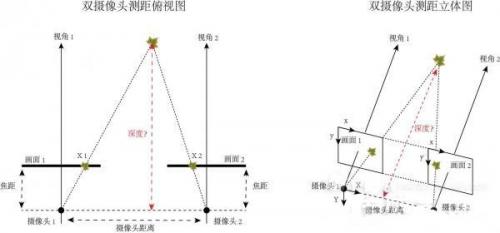
双摄像头测距是根据几何原理来计算深度信息的。使用两台摄像机对当前环境进行拍摄,得到两幅针对同一环境的不同视角照片,实际上就是模拟了人眼工作的原理。因为两台摄像机的各项参数以及它们之间相对位置的关系是已知的,只要找出相同物体(枫叶)在不同画面中的位置,我们就能通过算法计算出这个物体(枫叶)距离摄像头的深度了。
多角成像是三维手势识别技术中硬件要求最低,但同时是最难实现的。多角成像不需要任何额外的特殊设备,完全依赖于计算机视觉算法来匹配两张图片里的相同目标。相比于结构光或者光飞时间这两种技术成本高、功耗大的缺点,多角成像能提供"价廉物美"的三维手势识别效果。
- 安森美完成收购赛普拉斯CMOS图像传感器业务部(03-03)
- 国产IC低价格高利润的秘密(04-01)
- 爱特梅尔推出高精度数字温度传感器系列(04-06)
- 汽车信息娱乐产业受日地震影响一览 (04-06)
- 传感器正向高端发展(04-13)
- 格科CEO:国产IC低价格高利润的秘密(04-08)