求generate clock 带count 的资料
与这个FF1想对应的还有一些count reg (pre_clk1_count_reg_0_ ,pre_clk1_count_reg_1_..... )
根据ICC , 应该给 这个pre_clk1_reg 和 pre_clk1_count_reg_*_ 设成一个skew group 在CTS阶段
但是我不仅发现了 从count_reg_*_/CK 到 pre_clk1_reg/D的timing path
同时也发现了从pre_clk1_reg/CK 到 pre_clk1_reg/D 的timing path
这个skew 就很难满足。
求问各位大神有没有类似generate clock 的资料可以学习?
不是很理解这些count 和 这个FF1 之间的关系
CTS 应该怎么去平衡
多谢多谢啊
小编你好。
你的描述的应该是一个分周回路,并且这个count和pre的latency应该是不用平衡的。
判断并没有什么硬的根据, 只是从你的描述来分析的。FF1是一个2分周,随后的count*是4,8,...,分周回路。
这样的情况下,虽然FF1和count的是同一个clock source,但是FF1的D pin ⇒ Count的Q pin这样的path是不存在的。
看一下电路的schamatic可能就会清楚了。
非常感谢您的回复,我再去study一下
我用report_timing 来报了一下这样的path
report_timing -from u_power_pso/u_cpu_subsystem/u_clkrst/u_clk_div/v_ckd1_clk_pre_reg/CK -to u_power_pso/u_cpu_subsystem/u_clkrst/u_clk_div/count_ckd1_vclk_reg_0_/D
Information: Some cells in the scenario are using inferred operating conditions.
* Some/all delay information is back-annotated.
# A fanout number of 1000 was used for high fanout net computations.
Scenario: POST_CTS_SCENARIO
Parasitic source: LPE
Parasitic mode: RealRC
Extraction mode: MIN_MAX
Extraction derating : 125/125
Information: Percent of Arnoldi-based delays =3.65% on scenario POST_CTS_SCENARIO
Startpoint: u_power_pso/u_cpu_subsystem/u_clkrst/u_clk_div/v_ckd1_clk_pre_reg
(rising edge-triggered flip-flop clocked by p1clk)
Endpoint: u_power_pso/u_cpu_subsystem/u_clkrst/u_clk_div/count_ckd1_vclk_reg_0_
(rising edge-triggered flip-flop clocked by p1clk)
Scenario: POST_CTS_SCENARIO
Path Group: p1clk
Path Type: max
PointIncrPathVoltage
------------------------------------------------------------------------------------
clock p1clk (rise edge)0.00.0
clock network delay (propagated)0.60.6
u_power_pso/u_cpu_subsystem/u_clkrst/u_clk_div/v_ckd1_clk_pre_reg/CK (DFFSX4M)
0.00.6 r1.08
u_power_pso/u_cpu_subsystem/u_clkrst/u_clk_div/v_ckd1_clk_pre_reg/Q (DFFSX4M)
0.91.5 r1.08
u_power_pso/u_cpu_subsystem/u_clkrst/u_clk_div/icc_clock308/Y (CLKBUFX1M)
0.3 &1.9 r1.08
u_power_pso/u_cpu_subsystem/u_clkrst/u_clk_div/icc_route_opt84/Y (CLKBUFX1M)
0.5 &2.3 r1.08
u_power_pso/u_cpu_subsystem/u_clkrst/u_clk_div/icc_route_opt83/Y (CLKBUFX1M)
0.4 &2.7 r1.08
u_power_pso/u_cpu_subsystem/u_clkrst/u_clk_div/icc_route_opt15/Y (CLKBUFX2M)
0.7 &3.4 r1.08
u_power_pso/u_cpu_subsystem/u_clkrst/u_clk_div/U221/Y (NAND2X2M)
0.4 &3.8 f1.08
u_power_pso/u_cpu_subsystem/u_clkrst/u_clk_div/U222/Y (OR2X2M)
0.3 &4.1 f1.08
u_power_pso/u_cpu_subsystem/u_clkrst/u_clk_div/U20/Y (NAND2X6M)
0.1 &4.1 r1.08
u_power_pso/u_cpu_subsystem/u_clkrst/u_clk_div/U258/Y (NOR2X2M)
0.1 &4.2 f1.08
u_power_pso/u_cpu_subsystem/u_clkrst/u_clk_div/count_ckd1_vclk_reg_0_/D (DFFRHQX4M)
0.0 &4.2 f1.08
data arrival time4.2
clock p1clk (rise edge)1.51.5
clock network delay (propagated)3.85.3
clock uncertainty-0.35.0
u_power_pso/u_cpu_subsystem/u_clkrst/u_clk_div/count_ckd1_vclk_reg_0_/CK (DFFRHQX4M)
0.05.0 r
library setup time-0.14.9
data required time4.9
------------------------------------------------------------------------------------
data required time4.9
data arrival time-4.2
------------------------------------------------------------------------------------
slack (MET)0.7
report_timing -fromu_power_pso/u_cpu_subsystem/u_clkrst/u_clk_div/count_ckd1_vclk_reg_0_/CK -to u_power_pso/u_cpu_subsystem/u_clkrst/u_clk_div/v_ckd1_clk_pre_reg/D
Information: Some cells in the scenario are using inferred operating conditions.
* Some/all delay information is back-annotated.
# A fanout number of 1000 was used for high fanout net computations.
Scenario: POST_CTS_SCENARIO
Parasitic source: LPE
Parasitic mode: RealRC
Extraction mode: MIN_MAX
Extraction derating : 125/125
Information: Percent of Arnoldi-based delays =3.65% on scenario POST_CTS_SCENARIO
Startpoint: u_power_pso/u_cpu_subsystem/u_clkrst/u_clk_div/count_ckd1_vclk_reg_0_
(rising edge-triggered flip-flop clocked by p1clk)
Endpoint: u_power_pso/u_cpu_subsystem/u_clkrst/u_clk_div/v_ckd1_clk_pre_reg
(rising edge-triggered flip-flop clocked by p1clk)
Scenario: POST_CTS_SCENARIO
Path Group: p1clk
Path Type: max
PointIncrPathVoltage
------------------------------------------------------------------------------------
clock p1clk (rise edge)0.00.0
clock network delay (propagated)4.34.3
u_power_pso/u_cpu_subsystem/u_clkrst/u_clk_div/count_ckd1_vclk_reg_0_/CK (DFFRHQX4M)
0.04.3 r1.08
u_power_pso/u_cpu_subsystem/u_clkrst/u_clk_div/count_ckd1_vclk_reg_0_/Q (DFFRHQX4M)
0.44.7 r1.08
u_power_pso/u_cpu_subsystem/u_clkrst/u_clk_div/U292/Y (XNOR2X1M)
0.2 &4.8 r1.08
u_power_pso/u_cpu_subsystem/u_clkrst/u_clk_div/U291/Y (NAND2X3M)
0.1 &4.9 f1.08
u_power_pso/u_cpu_subsystem/u_clkrst/u_clk_div/U281/Y (NOR2X4M)
0.2 &5.1 r1.08
u_power_pso/u_cpu_subsystem/u_clkrst/u_clk_div/icc_clock264/Y (OAI2BB2X8M)
0.1 &5.2 f1.08
u_power_pso/u_cpu_subsystem/u_clkrst/u_clk_div/icc_clock246/Y (INVX16M)
0.1 &5.3 r1.08
u_power_pso/u_cpu_subsystem/u_clkrst/u_clk_div/icc_clock134/Y (CLKINVX40M)
0.1 @5.4 f1.08
u_power_pso/u_cpu_subsystem/u_clkrst/u_clk_div/v_ckd1_clk_pre_reg/D (DFFSX4M)
0.0 @5.4 f1.08
data arrival time5.4
clock p1clk (rise edge)1.51.5
clock network delay (propagated)0.62.1
clock uncertainty-0.31.8
u_power_pso/u_cpu_subsystem/u_clkrst/u_clk_div/v_ckd1_clk_pre_reg/CK (DFFSX4M)
0.01.8 r
library setup time-0.11.7
data required time1.7
------------------------------------------------------------------------------------
data required time1.7
data arrival time-5.4
------------------------------------------------------------------------------------
slack (VIOLATED)-3.8
感觉是如我所描述的吗?
帮忙分析一下
■ 不好意思回复晚了,不知道是不是已经弄懂了呢?
・ 根据这个timng report,回路大概是下面图的样子。(图太小的话放大一点吧。不怎么发图,排版估计有点难看)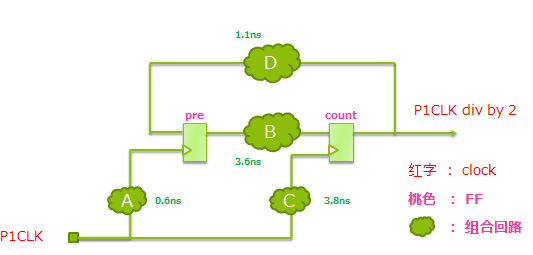
□ 这应该是个2分周的回路,信号在在组合回路B处翻转。
□ 其次,我之前的判断是错误的。pre/Q ⇒ count/D 以及count/Q⇒ pre/D 都存在,并且是ture path。
■ 有下面几个点比较在意
- 根据timing report, 周期为1.5ns算是高速了,可是组合回路B处有3.6ns的迟延,是否妥当?
· 建议将整个分周的module建一个bounds固定,不要离得太远。
· report1 和 report 2的cell delay差别很大
- report1中的1倍的BUF有高达0.7ns迟延,而report2中的16倍INV只有0.1ns
- 建议report时列出transition time ,capacitance ,crosstalk , derate值供参考,有违反先修正。
· 当前的skew值有3.2ns, 在count/D⇒ pre/Q的path上是无法MET的
- 建议CTS时做平衡。 useful skew慎用。
□ 结论的话,
- 虽然周期为1.5ns, 只要clock做平衡,latency做短(做不短也要保证common path较长), 应该是能MET的
看到如此周到的回复,感激涕零 我先分享一下我的想法,我第一不会尝试将这些count reg 设成一个skew group。
如若不行 , 将这些count的reg 设成ignore pin 然后让它去修DRC violation插buffer 。
目的一样就是为了做尽量短的latency。
再次感谢 。赞
回复的真是贴心啊