基于多核处理器设计网络接口卡
应用案例
1.ARP(地址解析协议)处理加速
以太网中的数据帧从一个主机到达网内的另一台主机不是根据32位的IP地址而是根据48位的以太网地址即硬件地址来确定接口。内核如驱动必须知道目的端的硬件地址才能发送数据。由RFC826我们知道,ARP地址解析协议就用于将计算机的网络地址即IP地址转化为物理地址即MAC地址。由于传统的物理网络接入的是物理服务器,并且整个网络只能为一个用户使用,普通CPU就可以处理报文的ARP请求,但随着服务器的虚拟化,以及云计算多租户的出现,网络对ARP处理的性能需求也大幅提升。采用纯CPU方案不仅大量耗费CPU资源,而且无法提供可确定的性能,无法防范可能的网络攻击。采用ACP3423的网络接口卡方案就可以很好的解决这个问题。
ACP3423处理ARP报文主要用到图1中的网络输入输出EIOA模块和流分类MPP模块,无需内部PowerPC核的参与,也就是说ARP流程完全卸载到快速通路来处理。EIOA模块主要用来从网络收发报文并执行以太CRC校验;MPP模块主要用来根据以太网类型字段过滤ARP报文,ARP报文操作验证诸如请求或者回复,MAC_DA flooding校验,对给定AR_IP寻找对应AC_MAC,生成ARP响应报文等。ARP处理流程图如图4所示。
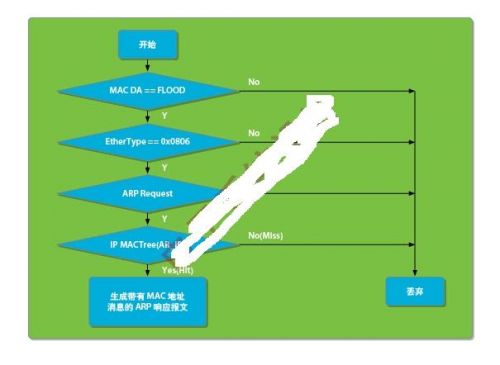
图4:ARP地址解析协议处理流程图。
以具有100K条目的ARP表项为例,Axxia可以处理超过1250万ARP报文/秒,即使在过载状态,Axxia也可以保证确定性的性能,有效防范各种攻击。
2. DPI(深度报文检测)
在多租户应用环境中,不同等级客户会有不同的服务等级,此时传统的五元组检查无法提供精细的控制,这就需要有DPI技术来对报文进行深入到7层的检测。通过Axxia的流分类引擎MPP,深度报文检测DPI引擎以及内置的多核芯片,网络接口卡可探测识别的应用种类超过5500种。
处理流程既可以通过Axxia的MPP引擎检测固定特性应用,也可以利用DPI引擎和CPU核对报文进行深度排查。基于固定特性表的应用识别主要通过目的端口号和协议来识别应用,MPP引擎具有表查找功能;基于特征的应用识别通过DPI引擎来检查特征时,在需要CPU干预或做后处理时,Axxia可以将报文送至内部CPU核做进一步判别处理,也可以送至任意外部主处理器做进一步操作。
本文小结
在数据中心的网络产品应用中,既要保证交换速度足够快,满足某些金融用户做高频交易服务的需求,另一方面要把容量做得更大,更具扩展性,满足像谷歌、Facebook这样的互联网用户的服务。LSI公司的异构多核通信处理器Axxia通过灵活的架构将硬件加速引擎与CPU相结合,很好解决了通用多核CPU处理效率与核数目增长非线性的关系。Axxia完全卸载业务到快速通路的业务流程保证了系统具有确定性的性能,同时可减低系统的成本和功耗。基于Axxia处理器的网络接口卡很好的满足了虚拟化环境下对网络设备提出的新需求。
- R4网络接口和电路域容灾技术(01-05)
- 一种面向云架构的高性能网络接口实现技术(02-02)
- 吐血推荐,动态可重配置片上网络平台的系统实现,设计大赛获奖作品(08-07)
- 意法半导体之宽带多媒体解决方案(01-12)
- 蓝牙技术硬件实现模式分析(01-11)
- 关于计算机接口(04-16)