基于CC—NUMA的多处理器系统研究
时间:04-09
来源:21IC
点击:

考虑到以上两种架构所用的处理器具有特殊性,都有独有的处理器间互联总线,不能推广到大部分处理器。而Origin2000的架构过于复杂,也就失去了其普遍性。故在此,基于前几种架构,提出一种更加简单、通用的CC-NUMA框架,如图7所示为一个四处理器的系统原理图。
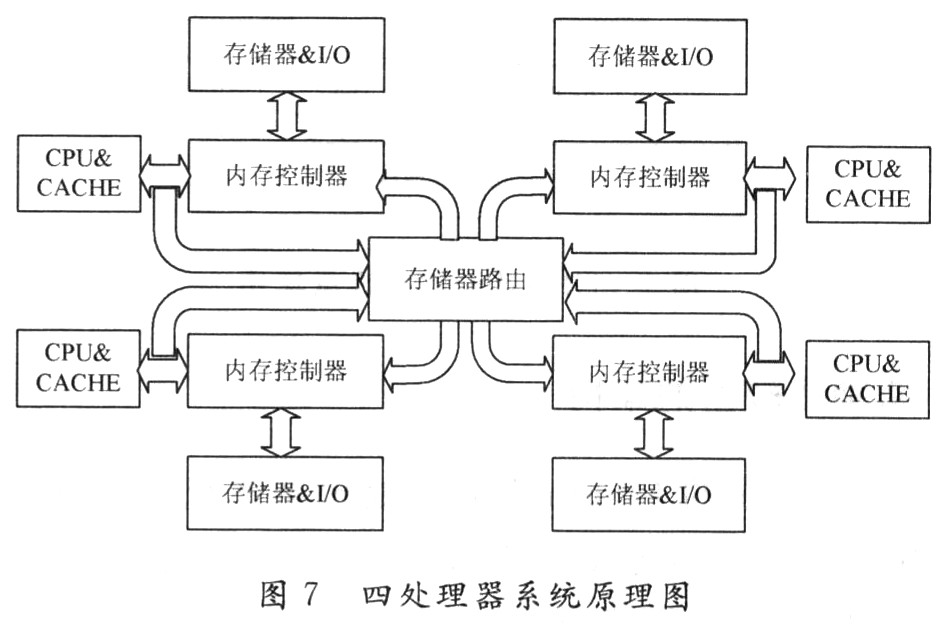
存储器路由的选择可以由高速FPGA实现,不同的FPGA可以扩展到不同数量、类型的处理器,所以整个系统的扩展性大大提高。
系统带宽取决于内存控制器带宽,其平均的访问路程为1.5 hops,明显低于前面几种架构的延迟。在总体性能上主要取决于FPGA路由器的性能。当前的高速FPGA在频率吞吐量上可以达到500 MHz以上的速度,在单引脚上可以达到6.5 Gb/s的传输,完全可以满足存储器路由的带宽要求,并且其高频率也可以有效控制整个系统的访存延迟。
整个系统可以快速地配置起来,并且可以扩展。所用的处理器可以是X86架构的处理器、PowerPc、MIPS处理器等,甚至一些嵌入式处理器也可以使用,真正达到了通用性。
4 结 语
多处理器系统的建构是一个很复杂的工程,要想充分发挥硬件架构的性能优势还需要操作系统及应用程序的配合,不同的操作系统及应用程序运行在同样的处理构架上其性能表现也会大相径庭。
多处理器系统 对称多处理 NUMA MPP SMP 相关文章:
- 大数据时代,这十五大关键技术你竟不知道?(01-17)
- “三刀”斩断安全隐患--锐捷校园网方案(04-28)
- SMP服务器用多处理器应用和组建(10-19)