继曙光4000A成功"服役"之后,新一代机型曙光5000A再次落户上海超算中心。这一代HPC相比前代机型的性能提高了一个数量级,其系统峰值运算速度达到230TFLOPS,是目前国内速度最快的商用高性能计算机系统。它的技术创新如何体现,曙光又如何看待未来HPC的技术发展,日前,曙光副总裁聂华与记者交流了曙光5000A背后的故事。
曙光怎样设计5000A
曙光5000A的技术参数已在发布时曝光,可具体技术细节却鲜有透露。聂华介绍说,曙光5000A的结构非常简练,高性能计算机是用互联网络将很多计算单元耦合在一起的,为了增加耦合效率,设计厂商曾构建了管理网络、存储网络、以太网络等各种网络。这一次,曙光5000A极大简化了整体网络结构,实现了多网合一。其体系结构也不同于传统集群或架构巨量平行处理架构(MPP),曙光提出超并行体系处理架构(HPP),除结合集群结构易扩展、易编程的优势外,还在高密度、高性能和耦合方面有了突出进展。
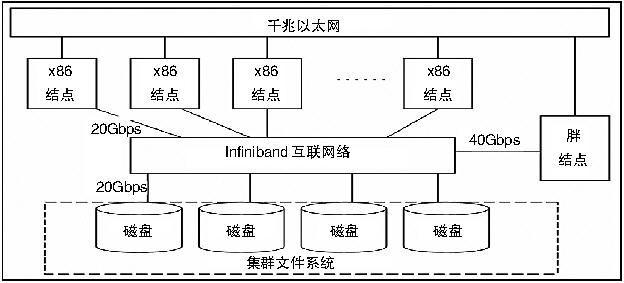 曙光5000A多网合一体系结构图
硬件架构之上是软件结构,软件才是用户运用高性能计算机的窗口。从基础部件层、系统软件层等底层开始,曙光5000A搭建了一个9层的软件架构,从域服务、资源调度、安全等层次进行有机组合。在应用层,曙光5000A拥有丰富的科学计算、商业计算以及信息化应用软件,为用户提供了实用基础。
除了架构创新之外,曙光5000A的另一项引人关注的技术创新是高密度刀片服务器,这是曙光5000A最核心的计算单元。该刀片总体架构为7U架构,里面有10片计算刀片。值得强调的是,每片刀片集成了4路SMP的4核处理器,这就构成了7U空间共计160核的超高密度设计,为常见1U服务器密度2.86倍。在刀片当中,它还整合了网络模块、管理模块、IOE扩展模块和冗余电源模块,尤其是内置DDR Infiniband HCA和交换模块,这是曙光创新的设计。这样,相邻结点MPI延迟为1.6us左右,而普通DDR交换机为3us以上,这一延迟直接影响着提升并行效率。同时,在内置之后,系统减少了50%的高速IB线缆的数量,大量IB连线对现阶段构建大规模集成网构成了威胁,铜缆容易形成不稳定连接。因此,尽可能减少高速IB连线的数量,对于提高IB稳定性来说意义很大。进一步设想,整个系统还提供10个PCI-E 8X IO扩展插槽,虽然这些插槽目前处于闲置状态,但如果都插上加速卡,就可以针对特别应用构建专用系统,这将带来广阔的应用扩展空间。
胖节点则为计算子系统解决更具挑战性的问题提供了保障。曙光配置了大约1/10规模的胖节点,与4路SMP结构运算节点配合。在4路计算刀片中,每个核可以进行64GB直接内存寻址,这意味着具有挑战性的一些工程计算程序可以更好地运行,胖节点则使每个核访问128GB内存成为可能。胖节点采用了改进的8路SMP处理结构,8个处理器之间实现交叉互联,实现了每个刀片32个核的SMP扩展。曙光不只实现了设计峰值的高性能,也非常注重这款机型的高可用性。"针对集群系统曾流行一个观点,当发展到1万个处理器核心时,系统的不可靠程度将增加,但曙光可以负责任地讲,曙光5000A可以稳定工作。"聂华说。
曙光为何钟情AMD
在今年公布的HPC TOP500榜单当中,基于英特尔处理器的系统占了绝大部分的市场份额。为什么在英特尔有着明显优势的市场,曙光在开发新机型时却选择了联手AMD?尽管曙光5000A采用的是AMD的巴塞罗那4核处理器,但聂华毫不否认,英特尔的处理器非常出色。"英特尔4核处理器的主频就要比巴塞罗那表现得要好,这在TOP500的峰值测试中是非常占有优势的。"聂华说,"但最终让曙光决定采用巴塞罗那的原因是由产品本身的设计决定的。"
聂华说,曙光5000A当时的定位就是高效能计算机,而并非单纯的高性能计算机。尽管当前的2路计算刀片已经非常成熟,但曙光还是决定研发高密度的4路计算刀片,这在保证提高生产力的同时,也能降低了系统规模,提高系统稳定性。对于这项设计来说,曙光认为AMD提供的巴塞罗那架构是理想选择。集成内存控制器的"直连架构"为目前AMD所独有,处理器直接访问内存能够降低延迟,而且能扩大内存带宽。在高性能计算领域,从CPU核心到内存之间的数据交换往往受制于带宽限制,这一现象导致的"内存墙"限制了系统整体性能的提升。"当然也有市场因素。但技术层面原因是最关键的。"聂华说,"英特尔的下一代架构也将采用直连技术,到那时就没有任何差别了,这也是未来趋势。"
曙光如何看混合架构
在IBM突破千万亿次计算的"走鹃"发布后,混合架构成为业界争论的焦点。究竟哪些系统适合采用混合架构,它与软件调优哪个才是HPC的发展趋势?聂华表示,混合架构与软件调优是相互关联,但又完全不同的两个方向,硬件加速针对特别应用,软件调优则使用相应工具,整体可以获得更好的并行性能,它们都可能为系统性能带来几倍甚至几十倍的提升。
从曙光5000A本身的情况来看,系统中完全预留了协处理器的插槽位置,完全可以使用龙芯、FPGA甚至商用化硬件作为加速器。但这次曙光5000A并没有采用加速器,这是与其用户的应用环境密切相关的。上海超算中心的特点是超大规模的通用计算平台,面向的用户众多,只要是高性能计算的,都可以在这个平台上进行。而国外的高性能计算机则多是单个用户专注于某项特定应用,如IBM的"走鹃"就是为美国洛斯阿拉莫斯国家实验室特别定制的。在这种情况下,对于上海超算中心来说,根本不能全部插上加速卡,只能面向部分特定用户构建少量加速结点。聂华表示,正因为上海超算中心是通用计算平台,所以曙光5000A要选用通用CPU和通用架构,这样对用户来说才实现了价值最大化。
如果某个用户对计算能力的要求足够高,或者可以面向具有同样特定应用的一类用户群提供服务,专用的加速器技术也将会在曙光5000A或后续机型上推广应用。
|