四核架构提升网格节点并行性实例分析
四核架构提升网格节点并行性实例分析
随着多核X86处理器性能持续提升,价格不断下降,使得以往只能做"定性"分析的许多领域和学科,现在都能够以集群方式构建高性能计算平台,对许多复杂的问
题做精确的"定量"分析,大幅提升研究的效率。这也是为什么国内外许多学术机构、企业争相建立自己的网格、集群,掀起了一股集群热。正在筹建的南京大学高性能计算中心专家小组成员周会群教授认为,在理论科学与实验科学之外,计算科学已经成为科研领域里的第三大支柱,起着理论研究的辅助工具和实验研究的导航设备的作用。
南京大学作为我国的重点综合性大学,许多领域的科研水平都居国内前列。数学、物理、天文、化学、计算机、生物及地质等学科都是国家一级重点学科,也是高性能计算的重点应用领域。目前,南京大学的专家小组正以建设计算能力名列国内高校前茅的高性能计算中心为目标,进行选型、测试等工作。筹建中的南京大学高性能计算中心将由一台具有256核的共享内存并行计算机,以及不小于400个计算节点的集群组成。每个节点具有2路或4路的四核处理器。建成之后,该中心将主要用于物理学、化学与工程、生命科学与生物技术、天文学、大气科学、地球科学与工程、材料科学与工程等领域的研究。
选型测试,四核皓龙并行效率出色
在选型测试中,专家们对基于不同架构的四核x86服务器做了测试,总的印象是目前主流的四核处理器各有其优点,对于缓存访问密集型应用程序来说,基于AMD四核皓龙处理器的服务器并行效率比较出色。单台计算服务器的并行效率是提升集群整体性能的关键因素之一。这也验证了国外的高性能计算中心建设中,较多应用AMD皓龙处理器的情况。最具代表性的高性能计算项目是,美国德克萨斯高级计算中心(TACC)超级计算机项目,采用了1.6万片AMD四核皓龙处理器,最终将实现每秒计算500万亿次计算能力的超级计算机,甚至超过了著名的IBM蓝色基因/L超级计算机。
所谓并行效率,概括来说就是多核处理器的各个核之间,或者多路处理器的CPU之间的相互协作的能力。这种协作的能力往往决定了集群节点的整体性能。而并行效率高,则是AMD多核处理器先进架构所决定的。在并行效率高的背后,是AMD的真多核架构与超传输总线。
直连架构是领先的根源
从速龙64和皓龙开始,AMD摒弃了x86架构一贯追求更高主频的做法,而借鉴了RISC处理器的CMP设计思路,将对更高带宽的支持引入到x86架构中。通过独创的直连架构和超传输总线技术,将CPU直接连接到内存、I/O,同时消除了传统的前端总线瓶颈,降低内存访问的延迟。正由于架构创新上的前瞻性,AMD在做单核的时候就考虑到了未来多核发展趋势,因而在从单核到多核的过渡中比竞争对手显得更自然顺畅。这也是AMD始终强调自己的多核是"真多核"的根源。
在推出双核皓龙处理器之后,实现四核最简单的办法就是做加法:2+2,将两个双核处理器拼装到一个封装上就可以直接实现四核处理器,在这种实现方法中两个双核处理器几乎是独立运行,甚少均衡负载的,在系统请求送达的时候CPU只需要简单的安排向左走还是向右走即可。但显然,这样的四核架构并不能令四个核心达到最高运行效率和负载均衡,最终表现在整体性能上就是在多路多核的环境中并行性不佳。因此,在AMD四核皓龙处理器中,仍然采用CMP(单芯片多核心处理器)设计思路,不用2+2拼装而是采用单一硅片上集成四个独立核心:每个核心具备自己单独的64KB的一级数据缓存、64KB的一级指令缓存,512KB的二级缓存,然后四个核心共享2MB(或者更大)的三级缓存。这样每个处理器核心都能够充分发挥自己的效能,使CPU整体性能达到最高。而使用两个双核拼装的方式,每个双核都要受到另一个的牵制,不能够充分发挥作用。
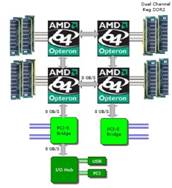
从AMD四核皓龙处理器的结构图(上图)中可以看出,每个CPU都拥有自己独立的内存通道及对外通道,相互之间也能够灵活通信,实现出色的并行性。AMD的每个处理器有自己独立的一、二级缓存及共享的三级缓存,无需通过前端总线,避免了瓶颈。
超传输总线高速互连
超传输总线,也是AMD应用于速龙64及皓龙处理器中的互连技术,是实现AMD四核皓龙处理器良好并行性的另一重要基石。它是摒弃了传统的前端总线之后的新一代互连技术。传统的处理器与内存交换数据,是处理器-北桥-内存这样的交换形式,而这种形式的弊端在于交换数据的延迟比较大,而AMD超传输技术正是解决这一问题的,即将原本集成在北桥里的内存控制器集成到CPU内部,这样内存与处理器之间交换数据的延迟大大缩短。超传输总线是一种可变速率的串行接口,而传统的方式则是使皓龙处理器具备每秒3.2 GB的带宽,而且因为支持双向同时传输,所以相当于每个超传输接口的总带宽为每秒6.4 GB。串行接口的带宽在设计时就具备一定的弹性。随着更多核心的加入,皓龙处理器可以增加超传输总线数量,另一方面超传输总线的频率也可以不断提升,保证有足够的带宽可用。CPU的核心越多,系统中CPU越多路,超传输总线就能够提供越大带宽,实现提高服务器运算性能,超传输总线的效果也就越明显。通过HT总线进行数据传输,性能的提升大幅超过仅仅只是靠系统总线作为数据传输数据交换。在即将推出的代号为"上海"的45纳米4核皓龙处理器上,超传输总线将从1.0版本跨越式升级到3.0版本,时钟将从1000MHz提升到2.6MHz,超传输的带宽也从8GB/秒跃进到16GB/秒,为CPU之间数据交换提供了通畅的渠道。
- AMD巴塞罗那:真四核处理器改变游戏规则 (08-20)
- 四核Spider平台:从芯片优化到平台优化(11-04)
- 泰安发布支持四路四核AMD服务器平台及准系统(05-11)
- Intel推至强7300 四核之争愈演愈烈(08-07)
- 浪潮与Intel全球同步发布四核服务器(08-07)
- 四核安腾Tukwila即将问世 英特尔透露处理器构造(02-11)