TLM驱动式新方案探讨
需要事务处理器将TLM IP块连接到RTL IP块上的总线或接口。基于TLM的方法学必须考虑,这些事务处理器该怎样工作,以获得混合TLM/RTL验证的最大收益。有些事务处理器可通过购买取得,而有些则是专有的,由项目团队创建,并作为验证库组件进行管理。
很多项目实现TLM仅仅是为了新IP,从而逐渐建立起一个TLM IP库,许多团队针对新的IP采用了TLM的方法学,并且逐渐丰富TLM IP库,而有些团队在事关成败的关键项目中采用了TLM方法学,用于所有重要的IP模块。最终,SoC的所有IP黄金源码都来自于TLM级。在这些情况下,品质、效率及容易调试的优点将比TLM/RTL混合项目中更加明显。SoC TLM功能验证,包括SoC级架构分析和优化,将可能实现。
从TLM到RTL验证进行VIP复用
VIP复用现已成为主流,因为创建高质量验证环境的时间经常超过创建设计IP本身的时间。标准协议的广泛使用推动了商业VIP市场的快速发展。当前,大部分VIP是寄存器传输级的。由TLM得到的VIP也将有一定需求,但必须可复用于TLM/RTL混合功能验证。
在RTL功能验证中,使用约束随机激励生成的先进testbench占据了主导地位。由TLM得到的VIP在用于TLM、TLM/RTL混合及RTL功能验证的testbench中应该都是可操作的。这样的VIP需允许指标驱动式验证的应用,因为客户会在验证抽象的所有级别上使用覆盖指标。最后,对于和架构及软件工程团队工作密切相关的验证团队,辅助的嵌入式软件和定向测试也是必需的。
从算法到微架构的渐进式设计改进
TLM IP设计和验证流程有若干独特的步骤:算法验证、架构验证、微架构验证(见图3)。第一步(算法验证)可能涉及C++或Matlab或Simulink这样的产品。用户可为关键算法特性制定一个vPlan,验证I/O的功能,并为关键实例应用激励序列。
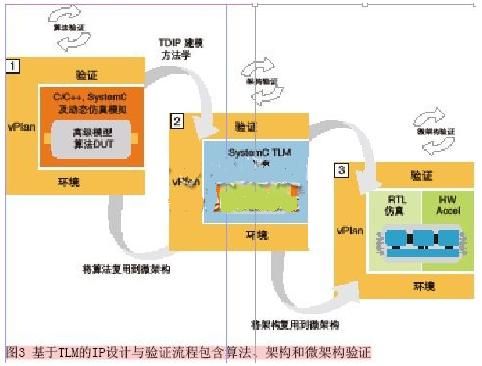
第二步(架构验证),设计师使用TLM驱动式IP建模(TDIP)方法学来定义架构和接口协议。他们复用算法vPlan,并应用额外的激励、检查、断言与覆盖,还为关键架构和接口协议特性制定vPlan。在第三步(微架构验证),设计师通过C-to-Silicon Compiler进行综合,复用算法和架构vPlan,然后推广至激励、检查、断言与覆盖中的微架构详情。
Cadence TLM产品
Cadence TLM驱动式IP设计与验证解决方案包含方法学指南、C-to-Silicon Compiler、Cadence Incisive功能验证平台以及TLM驱动式IP设计与验证服务。
统一的TLM驱动式IP设计、验证、复用方法学及编码指南
Cadence将为TLM驱动式IP设计与验证提供方法学指南,帮助设计团队在最短时间内以最高效率启动和完成他们初始的TLM项目,并避免采用新方法学的常见错误。从TLM IP设计编码风格、建模指南及综合子集开始,用户能够创建TLM IP,其架构利用了高层次综合所提供的能力。在整个TLM驱动的IP方法学中都考虑了对设计和验证IP的复用。
C-to-Silicon Compiler利用TLM黄金源码创建高质量的RTL
C-to-Silicon Compiler是一个高层次综合产品,它采用TLM SystemC IP描述和约束,并创建可用于标准RTL实现流程的RTL。为确保结果的质量,它利用Cadence Incisive RTL Compiler技术来创建逻辑,并提取该逻辑的时序与功耗信息来决定最终RTL的架构详情。
C-to-Silicon Compiler GUI显示了原始SystemC和根据它生成的RTL代码行之间的对应关系。这种独特的对照功能鼓励系统设计师和RTL设计师之间的沟通,并有助于保持SystemC TLM作为黄金源码。它还将调试提升到更高的抽象水平,并使设计师可以评估SystemC源码的变化对RTL产生的影响。
C-to-Silicon Compiler提供了增量综合能力,可大幅简化工程更改(ECO)过程并尽可能减少对RTL代码的更改。其他大多数HLS工具都要求对整个算法进行重新综合,意味着源代码中的微小变化也会导致完全不同的RTL。在这些情形下,必须重做逻辑综合和RTL验证。因而很难将SystemC代码保持为黄金源码。相比之下,C-to-Silicon Compiler仅对算法的改变部分生成RTL代码,而不修改设计的其他部分。
C-to-Silicon Compiler能通过应用新约束,生成新RTL,将TLM设计IP转移到新的微架构目标。通过指定不同时序、面积和功耗约束或不同微架构指导如流水线级数,就能生成新的RTL。这样,设计团队就能重复利用IP,且人力投入更少,RTL质量更高,时间更少。通过尝试不同微架构,设计师还可运行假设实验。
最后,C-to-Silicon Compiler能自动生成周期准确的SystemC快速硬件模型(Fast Hardware Models, FHM),能以非定时TLM模型的80%~90%的速度执行。这些SystemC模型允许早期快速验证和软硬件协同开发
- TLM驱动式的新方案探讨(11-10)