基于ADSP-2106X SHARC DSPs软件仿真器的实现
本文介绍一种ADSP-2106x DSPs (数字信号处理器, Digital Signal Processors)的软件仿真器(ADSPSim)。在此仿真器构架过程中,面向对象仿真技术的使用大大改善了软件的模块化、可重用性和灵活性,更加体现了软件仿真器在实现软硬件协同设计开发和早期测试过程中的优势。
1 引言
DSPs(数字信号处理器)在航空航天工程等领域已得到广泛应用,为实现早期测试,仿真器的使用提供了建立嵌入式系统软硬件协同测试环境的可能。仿真器可分为软件仿真器(Simulator)和硬件仿真器 (Emulator)两类,而软件仿真器比较硬件仿真器有着不可替代的优势:
(1) 开发人员能在获得实际硬件原型前,能快速评价目标机软、硬件特性,实现硬件和软件并行设计开发,并缩短嵌入式软件的开发周期,尽早发现软件中的缺陷,降低开发成本;
(2) 软件仿真器具有高度的灵活性,可独立对CPU进行深入分析,或可用于对整个系统进行建模。还可轻松地进行重新配置,可与各种存储器或外设相集成。这样就可以对整个嵌入式系统的正确性进行验证。
(3) 由于软件仿真器能够反复地运行相同的仿真过程,便于在对软件进行调试、测试过程中,控制与分析应用程序运行及仿真环境的状态,并可以采集到大量的调试数据。
软件仿真器一般都是在ISA(指令集体系结构)级对系统进行仿真的,本文也不例外,也就是所说的指令集仿真器。
指令集仿真器的实现方法有两大类:一类是解释型指令集仿真器,将应用程序装载入仿真的存储器中,在运行时模拟"取指(fetch)-译码(decode)-执行(execute)"的流水对每条目标指令进行解释,将结果存入仿真的寄存器或存储器中。另一类是编译型指令集仿真器,又可细分为基于静态编译与基于动态编译两类,其原理是将目标机的指令直接翻译为能实现相应功能的宿主机上的指令/指令块,翻译在编译时实现为基于静态编译的指令仿真器,在装载时才实现为基于动态编译的指令仿真器。解释型指令集仿真器仿真速度比较慢,但由于是对指令的逐条解释,可以提供对执行应用程序的很方便的控制;而编译指令集仿真器虽然有较高的仿真速度,但由于对源程序进行了反编译后又进行了优化,已经丢失了原来的用户程序与高级语言的对应关系。解释型指令集仿真器提供了调试运行仿真器的可能,更利于嵌入式软件测试,因此本文中的指令集仿真器的实现采用此类方式。
随着面向对象技术的成熟,仿真软件已经朝着可互操作性、可重用性、面向对象的趋势发展,面向对象仿真( Object-Oriented Simulation )已成为当前仿真研究领域最为活跃的研究方向之一。本文中的软件仿真器ADSPSim在构架上也采用了面向对象的仿真技术。
2 ADSP-2106x SHARC DSPs简介
ADSP-2106x是AD公司的第二代32位浮点数字信号处理器,AD称之为SHARC(Super Harvard Architecture Computer,超级哈佛结构体系结构计算机)。目前包括四种产品:ADSP-21060、ADSP-21061、ADSP-21062、ADSP-21065L。
2.1 ADSP-2106x体系结构概述
和冯诺伊曼结构不同,哈佛结构使用分离的数据和程序空间及分类的访问总线。而改进的超级哈佛结构的超级之处在于允许在程序存储器(PM)中同时存放数据和指令(可灵活配置)。再辅以独立划分的片内总线(分别用于PM和DM, 数据存储器)和指令高速缓存,很好地解决了在执行双数据存取的指令时,当需要从PM中读写数据而产生的使用PM数据总线的冲突。当第一次发生使用PM数据总线的冲突时,处理器会将指令存放在高速缓存中,当再次使用该指令时,处理器就可以一次性完成从高速缓存中取指令,从DM和PM同时取数据的并行操作。ADSP-2106x的详细体系结构如图1所示。
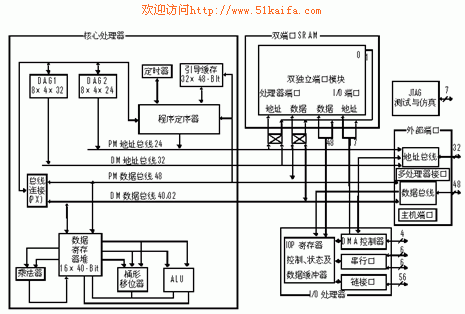
图1 ADSP-2106x 组成框图
2.2 ADSP-2106x指令系统概述
ADSP-2106x指令系统具有RISC(精简指令系统)指令长度一致、单周期执行时间、易于并行和流水线处理的特点,可以分为四大类:计算并存取指令,程序流控制指令,立即数寻址存取指令,及其它指令。又可按照操作码细分为24小类。值得指出的是,其中大多数指令包含指定计算操作的域。ADSP-2106x指令固定长度为48位,若包含计算操作域,则低0~22位固定为计算操作指令。详细指令集见附录A&B。
正是由于计算指令与存取或跳转指令可以合并在一条指令中译码执行,ADSP-2106x拥有一个高性能的计算内核,它可以在每个指令周期内完成三个计算,包括一次加法、一次减法、一次乘法,以及寄存器到存储器的存/取操作,或是程序流的改变操作。因此在60 MHz 的时钟速率下可以得到180 MFLOPS(每秒兆浮点操作次数)的性能。
3 软件仿真器ADSPSi
DSPs SHARC 软件仿真器 ADSP-2106X 相关文章:
- 基于DSP并使用SPWM控制技术的变频器实现方案(12-21)
- 中国仪控产业蕴含巨大商机,ADI DSP助跑本土军团(05-25)
- SHARC引领第四代通用DSP高端应用潮流(09-27)
- SHARC处理器满足一高二低的浮点设计需求(04-16)
- SHARC DSP与SJA1000的CAN总线接口设计(03-14)
- 基于DSP与SJA1000的CAN总线系统设计方案(07-15)