在ADSP-BF561上实现与优化的H.264
目前,音视频技术日新月异,其中,视频实时编码传输极具代表性。在视频压缩算法领域,新一代视频压缩标准H.264以其优异的压缩性能和图像质量使视频实时编码传输技术的实现成为可能。但该标准的计算复杂度高,用一般的图像处理芯片难以达到实时编解码的要求,它需要快速、稳定的处理器作为硬件平台。ADSP-BF561是ADI公司推出的高性能多媒体处理器。其主要特点是具有两个ADSP-BF533处理器核心(以下简称核心A和核心B),最高时钟频率达到600MHz,其内部采用哈佛总线结构,存储模型层次化。其典型应用模式是A核运行嵌入式操作系统,B核运行多媒体处理算法,如H.264。本文提出了一套采用ADSP-BF561芯片实现H.264视频压缩算法的设计方案,结合该DSP平台对算法进行了针对性的优化,充分发挥了ADSP-BF561强大的处理能力。
1 算法介绍
1.1 H.264编码模型框架
H.264以其高压缩比、高图像质量和良好的网络亲和性广受业界欢迎。在同等质量条件下,H.264的数据压缩比比MPEG-2高2~3倍,比MPEG-4高1.5~2倍。其需要的带宽只有MPEG-4的50%, MPEG-2的12.5%。
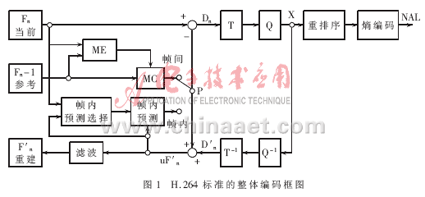
H.264标准采用分层体系结构,系统分为:视频编码层VCL(Video CodingLayer),负责高效的数字视频压缩;网络抽象层NAL(Network AbstractionLayer),负责对数据进行打包和传送。H.264编码图像通常分为三种类型:I帧、P帧、B帧。I帧为帧内编码帧,其编码不依赖于已编码的图像数据。P帧为前向预测帧,B帧为双向预测帧,编码时都需要根据参考帧进行运动估计。同时,H.264在提高图像传输容错性方面做了大量工作,重新定义了适于图像的结构划分。在编码时,图像帧各部分被划分到多个Slice结构中,每个Slice都可以被独立编码,不受其他部分影响。Slice由图像最基本的结构--宏块组成,每个宏块包含一个16×16的亮度块和两个8×8的色度块。H.264标准的整体编码框图如图1所示。编码过程中,原始数据进入编码器后,当采用帧内编码时,首先选择相应的帧内预测模式进行帧内预测,随后对实际值和预测值之间的差值进行变换、量化和嫡编码,同时编码后的码流经过反量化和反变换之后重构预测残差图像,再与预测值相加得出重构帧,得出的结果经过去块滤波器平滑后送入帧存储器。采用帧间编码时,输入的图像块首先在参考帧中进行运动估计,得到运动矢量。运动估计后的残差图像经整数变换、量化和嫡编码后与运动矢量一起送入信道传输。同时另一路码流以相同的方式重构后,经去块滤波后送入帧存储器作为下一帧编码的参考图像。
1.2 H.264关键技术
1.2.1 帧内预测
H.264引入了帧内预测以提高压缩效率。帧内预测编码就是利用周围邻近的像素值来预测当前的像素值,然后对预测误差进行编码。这种预测是基于块的。对于亮度分量,块的大小可以在16×16和4×4之间选择,16×16有4种预测模式,4×4有9种预测模式;对于色度分量,预测是对整个8×8块进行的,有4种预测模式。
1.2.2 帧间预测
帧间预测时所用块的大小可变。假设基于块的运动模型,其块内的所有像素都做了相同的平移,在运动比较剧烈或者运动物体的边缘外,这一假设会与实际出入较大,从而导致较大的预测误差,这时减小块的大小可以使假设在小块中依然成立。另外小块所造成的块效应相对也小,因此,小块可以提高预测的效果。H.264一共采用了7种方式对一个宏块进行分割,每种方式下块的大小和形状都不相同,编码器可以根据图像的内容选择最好的预测模式。与仅使用16x16块进行预测相比,使用不同大小和形状的块可以使码率节约15%以上。
同时,帧内预测采用了更精细的预测精度,H.264中亮度分量的运动矢量使用1/4像素精度。色度分量的运动矢量使用1/8像素精度。
1.2.3 多帧参考
H.264支持多帧参考预测,最多可以有5个在当前帧之前的解码帧作为参考帧产生对当前帧的预测,提高H.264解码器的错误恢复能力。
1.2.4 整数变换
H.264对残差图像的4×4整数变换技术,采用定点运算来代替以往DCT变换中的浮点运算。以降低编码时间,同时也更适合硬件平台的移植。
1.2.5 熵编码
H.264支持两种熵编码方法,即CAVLC(基于上下文的自适应可变长编码)和CABAC(基于上下文的自适应算术编码)。其中CAVLC的抗差错能力比较高,但编码效率比CABAC低;而CABAC的编码效率强,但需要的计算量和存储容量更大。
1.2.6 去方块滤波
去方块滤波的作用是消除经反量化和反变换后重建图像中由于预测误差产生的块效应,从而改善图像的主观质量和预测误差。经过滤波后的图像将根据需要放在缓存中用于帧间预测,而不是仅仅用来改善主观质量,因此该滤波器位于解码环中。对于帧内预测,使用的是未经过滤波的重建图像。
2 算法实现
2.1 平台选择
2.1.1 ADSP-BF561芯片介绍
ADSP-BF561是Blackfin系列中的一款高性能定点DSP视频处理芯片。其主频最高可达750MHz,内核包含2个16位乘法器MAC、2个40位累加器ALU、4个8位视频ALU,以及1个40位移位器。该芯片中的两套数据地址产生器(DAG)可为同时从存储器存取双操作数提供地址,每秒可处理1 200兆次乘加运算。芯片带有专用的视频信号处理指令以及100KB的片内L1存储器(16KB的指令Cache,16 KB的指令SRAM,64 KB的数据Cache/SRAM,4 KB的临时数据SRAM)、128KB的片内L2存储器SRAM,同时具有动态电源管理功能。此外,Blackfin处理器还包括丰富的外设接口,包括EBIU接口(4个128 MBSDRAM接口,4个1MB异步存储器接口)、3个定时/计数器、1个UART、1个SPI接口、2个同步串行接口和1路并行外设接口(支持ITU-656数据格式)等。Blackfin处理器在结构上充分体现了对媒体应用(特别是视频应用)算法的支持。
2.1.2 ADSP-561 EZkite
ADSP-BF561视频编码器平台采用ADI公司的ADSP-BF561 EZ-kitLite评估板。此评估板包括1块ADSP-BF561处理器、32 MB SDRAM和4 MBFlash,板中的AD-V1836音频编解码器可外接4输入/6输出音频接口;而ADV7183视频解码器和ADV7171视频编码器则可外接3输入/3输出视频接口。此外,该评估板还包括1个UART接口、1个USB调试接口和1个JTAG调试接口。摄像头输入的模拟视频信号经视频芯片ADV7183A转化为数字信号,此信号从ADSP-BF561的PPI1(并行外部接口)进入ADSP-BF561芯片进行压缩,压缩后的码流则经ADV7179转换后从ADSP-BF561的PPI2口输出。此系统可通过Flash加载程序,并支持串口及网络传输。编码过程中的原始图像、参考帧等数据可存储在SDRAM中。
2.2 算法选取与优化方案
2.2.1 算法选取
H.264实现的源代码不止一种,其中最常见的有JM、X264和T264。对比这三种实现源代码,X264比T264具有更高的效率。而且相比广泛采用的JM编码模型,X264在兼顾编码质量的同时大幅度地提升了编码速度,所以选取X264作为算法原型。
2.2.2 优化方案
该优化方案从三个层次对算法进行优化:算法层次、代码层次、平台层次。下面介绍具体优化方法。
2.2.2.1 编码器具体参数的选择
该编码器使用main档次,I、B、P帧量化值分别为26、31、29,流控参数选为CBR。IDR帧间隔设为50,B帧间隔为2帧。这样的选择是为了在速度和运算量上取折中。选用B帧并将其量化值加大,可比baseline档次、IPPP结构提高约10%的压缩率。而B帧的计算量,因其不用做参考帧,故无需进行去块滤波和插值计算,在31的qp下,很多块会被判做skip模式编码,因而多数时B帧总运算量候反而较P帧低。
2.2.2.2 算法层次的优化
算法层次的优化主要是指在参数选定的情况下,对部分算法所作的替换或优化。和参数的选择一样,算法层次优化也主要受优化策略的指导。如运动匹配准则是选用SSD、SAD或SATD。如果只看中准确程度,则选择SSD最佳;如果只看中运行速度,则选择SAD最佳;如果要兼顾二者,则选用SATD是比较好的一个方案。在进行算法优化时还应该注意一个问题,即要考虑实际运行平台的支持情况。如在追求速度的策略下,匹配准则选用SAD,如果只计算一半的点则会大大降低运算速度。但是如果考虑ADSP-BF561汇编指令的设计情况,就会发现这样做反而会增加指令数,会使速度更低。算法层次优化包括如下几个部分:
(1)除法求余。改进策略是浮点型算法尽量改为整型,64位尽量改为32位,32位尽量改为16位。而对于某些计算比较多的,则改为查表计算。在ADSP-BF561平台上,一次32位整形除法需耗时300个CYCLE,而查表仅需几个CYCLE,这样的改进能显著提高速度。
(2)饱和函数。在视频的计算中,几乎每次像素的计算都会调用饱和函数,X264代码的实现中已将这部分代码改为查表函数,在其他的编解码器实现中也有将这部分改为一个判断和几个逻辑运算的形式。对大部分DSP平台,采用判断跳转会打断流水线,即使平台有比较好的跳转预测功能,打断流水仍然会造成stall。所以查表方法是一种高效方法。而在ADSP-BF561汇编指令中,可以通过设置指令后缀或使用某些特殊指令来进行饱和工作。甚至不用查表,在不同的场合使用不同的饱和算法能大大提高代码的执行效率。
(3)MC部分函数。实测中发现MC部分函数运行效率不如ffmpeg解码器中MC部分效率高,所以将这部分代码用ffmpeg中的相应部分替换。此外qpel16_hv函数中计算有冗余,减少这些冗余能提高代码运行效率。
(4)算法替代和改进。帧间预测的改进:关于算法的改进主要集中在对me(motionestimation)的改进上,流程如图2所示。costmin1=min(cost16,cost8,cost16×8,cost8×16),costmin2=min(costmin1,costsub),依次在16×16、8×8、16×8和8×16大小宏块的整像素位置做预测,再做次像素估计和帧内预测,选用匹配准则函数(采用sad作为匹配准则函数)取得最小值的模式进行编码。每计算一种模式,都将sad值与一个经验阀值做比较。当sad值小于这个阀值时,立即结束运动估计,从而减少运算量。
- Linux嵌入式系统开发平台选型探讨(11-09)
- 基于Winodws CE的嵌入式网络监控系统的设计与实现(03-05)
- 嵌入式系统实时性的问题(06-21)
- 嵌入式实时系统中的优先级反转问题(06-10)
- 嵌入式Linux系统中MMC卡驱动管理技术研究(06-10)
- FPGA的DSP性能揭秘(06-16)