软件化和网络化的基于Linux的雷达终端系统
现有的雷达终端系统采用了大量的高速专用芯片实现。而芯片的更新换代很快,许多芯片已面临淘汰,即使还没有完全消失,价格也已经很昂贵,给系统的维护和升级换代带来极大不便。随着计算机、软件和网络技术的不断发展,使得新一代的雷达终端系统的软件化和网络化实现成为可能。本文基于此技术背景展开研究,并给出系统的具体实现。
1 整体实现方案
1.1 基于Linux操作系统
传统的雷达显示系统是基于Windows的。但是Windows面临许多问题,譬如封闭源码、易被病毒和黑客入侵等。而Linux是免费的、开源的、网络化的操作系统。其内核是独立和高度可配置的。Linux的网络功能和安全性要优于Windows。所以基于Linux的系统方案是比较合适的。
1.2 系统实现方案
系统由预处理机、主显机和网显机组成,如图1所示。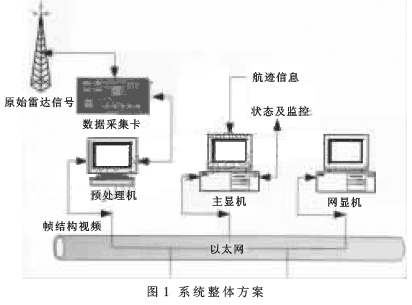
预处理机的主要功能是:雷达视频的采集、压缩和传输,接收二次信息和操控信息并存储所有信息。主显机功能:压缩视频的接收、解压、显示,接收二次信息并显示,人机操控操作,将二次信息和操控信息发送到网络上。网显机类似于主显机,但没有操控功能。为简单起见,本文不讨论网显机的实现。
2 预处理机系统的实现
预处理机完成数据的采集、压缩和传输,下面针对这三个方面进行介绍。
2.1 基于PCI总线的雷达视频采集卡
这是系统中惟一的硬件实现部分,也是必不可少的,它将采集的数据传给计算机。这部分的具体实现可参考文献[1]。
2.2 小波压缩技术
当雷达采样率很高时,网络传输前不进行压缩处理,带宽是不够的。
基于帧的压缩技术,不适合对雷达视频具有实时要求的场合,因为会引入一个固定延时。而一维小波压缩可以做到高效压缩和实时要求的折衷。
小波压缩的思想是将一维数字序列分为粗糙尺度和细节两部分,各占一半存储空间,这个过程可以一直递归下去;因为回波信号比较平滑,细节部分主要是噪声,所以只保留粗糙尺度部分,如图2所示。
不同尺度系数的分解与合成如图3所示。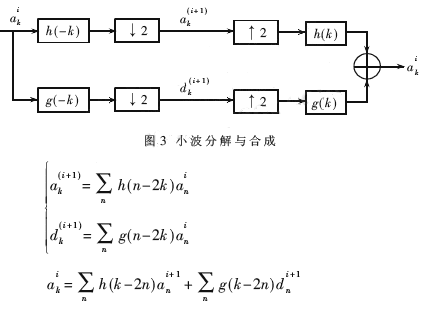
其中h(k)、g(k)是一组由两尺度方程推导出的共轭镜像滤波器。aki是第i层的(粗)尺度系数。第i层按递归分解成i+1层的更大尺度部分ak(i+1)和细节部分dk(i+1)。
分解过程相当于输入序列和滤波器卷积后,进行亚采样,只保留偶数点;合成过程相当于先对序列进行插值(添加0)后,再与滤波器卷积、相加。
图4是一个用db1小波递归3次压缩一段雷达回波的例子,压缩接近原来的1/8。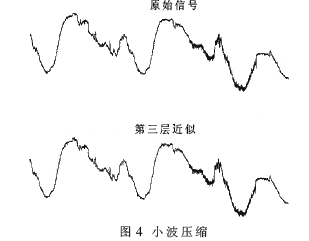
系统中采用 (9,7)双正交小波快速提升算法,根据实际需要进行1~4层尺度分解。小波压缩实现细节可参考文献[2]。
2.3 网络传输
常用的网络协议是UDP和TCP。UDP是面向无连接的协议;TCP是面向有连接的协议。另外,TCP协议在接收方还要进行包的次序调整,因为不同的包可能按不同的路由到达。然而,可靠是要付出代价的,TCP占用CPU资源要比UDP高,网络利用率也不如UDP。如果网络状况良好,需要持续进行大批量的数据传输,可以考虑UDP。一般情况下,通讯方式都是点对点的,也就是所谓的单播方式。采用这种方式,多个客户机必须与同一个服务器分别建立连接,这导致了网络负载成倍增加。
在特殊情形下可以使用广播方式。其目前只被UDP协议支持。广播的实现非常容易,只需要将目的IP地址设置为该段子网的地址即可。这种一对多的方式会影响不需要接收的主机,子网上所有未参加广播接收的主机也必须完成对数据报的协议处理,直至UDP层才将它丢弃,甚至还会引起广播风暴。
单播和广播是两种极端。多播提供了一种折衷的方案。多播数据报仅由对该数据报感兴趣的主机接收(该主机加入多播组),不会影响子网上其它主机。目前UDP提供对多播的支持。
系统中,一次视频采用多播方式;主显示机与预处理机之间的操控命令连接通道由于需要可靠的连接且通信量相对较少,所以采用了面向连接的TCP协议。
3 主显机系统的实现
主显机主要由各种显示模块和网络模块组成。显示模块包括PPI和AR模块。其中以PPI显示技术最为复杂,显示模块和网络模块如何整合是系统效率高低的关键。
3.1雷达视频PPI显示
3.1.1坐标变换和死地址
显示过程中一个很重要的步骤是进行坐标的转换。数据采集卡得到的雷达视频数据以距离方位为坐标,但通用显卡的内存则以行列为坐标,故极坐标要转化为x-y直角坐标,极坐标与自然直角坐标转换为: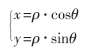
如果实时计算,目前的计算机硬件条件无法达到实时要求。可事先计算好,转换时采用查表法,以空间换取时间。转化表可以只计算第一象限,其它象限根据方位码对称性确定。
所谓死地址,是指PPI显示中远离显示中心的地方会有部分区域始终访问不到,从而产生类似于衍射花纹的现象。半径愈大时,这种花纹愈明显。如图5所示。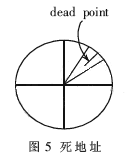
需要把这些不能被访问到的点"补"上。将原有的一些有重复(即多个(ρ-θ)点映射到同一个(x-y)坐标)的点分开,以最近为原则将其中的重复点强行改为"死地址"点。例如,极坐标下的两个点M1(ρ1,θ1)和M2(ρ2,θ2),转换为直角坐标后对应的点都是M3(x1,y1),而点M4(x2,y2)是"死地址"且M3和M4相隔很近,这时强行规定M1=>M3而M2=>M4。
系统中,不偏心时,扫描半径是512像素,一周4096根扫描线。实践证明可以将所有的死地址与相邻的方位距离码关联起来,消除花纹图案。可以想象:扫描半径越大,远离圆心的死区面积越大,其附近通常找不到能够利用的重复点,必须改进方案。
考虑最极端的情形,偏心在圆周上,此时最大扫描半径为1024。将半径1024的圆分为半径512的同心圆和剩下的外圆环。内部的小圆可以用前面的方案。512~1023部分将方位分辨率提高一倍,即一周8192根,再进行补点。具体算法如下:
(1) 得到外圆环的所有x-y坐标点的集合。
(2) 将外圆环内所有的ρ-θ点按转换公式四舍五入到最近的x-y坐标点。有些x-y会关联多个ρ-θ点,有些则没有ρ-θ点与之关联。
(3) 遍历那些没有ρ-θ关联的x-y。对于每个这样的x-y点,查找以自己为中心、边长为4的正方形内所有的x-y点,如果发现某一个x-y点关联ρ-θ多于一个,就将其中的一个ρ-θ给这个没有ρ-θ关联的x-y。同时,给出ρ-θ的x-y点,在其ρ-θ关联链表中去掉给出的ρ-θ。
(4) 按ρ从512~1023、θ从0~8191的顺序将对应的x-y写入磁盘文件中。
编程计算结果表明这种算法可以很快地补全所有死地址。
相应地,原来的坐标转换表应该由补过死地址的两张表(一张是半径512以内,另一张是512~1023)代替。
3.1.2 余晖模拟
传统雷达系统中利用长余辉管作为PPI显示器。其优点是:目标亮度强、衰减慢;噪声在显示器上亮度弱、衰减快。这使目标很突出。如果是运动目标,会产生拖尾效应,使运动目标更形象、更容易被发现。使用普通显示器,必须提供一种软件实现机制模拟余辉。一种方法是:对PPI扫描区域的点进行循环伪随机访问,读出后进行衰减再写入。其原理是:按伪随机序列进行遍历的点可以近似认为是分布均匀的,而当前扫描区域只是占整个PPI区域的极少部分,所以落入当前扫描区域的伪随机序列的点数也很少,而远离当前区域的随机序列的点数很多,所以平稳后能产生离当前扫描线越远越暗的余晖效果。
对于半径512像素点的PPI扫描区域,其外切矩形为1024×1024。用20bit的伪随机序列的前10bit对应矩形区域的X坐标点,后10bit对应Y坐标点,再去掉圆外面、矩形以内的像素。PPI每扫描一根半径线,就循环读出一段随机点,衰减后再写入。每次衰减的点数和幅度可根据需要设置。X和Y坐标的随机表可以事先生成好,以数据文件的形式存储在硬盘中,程序初始化时一次读入。
3.1.3 二次信息的分层显示
广义的二次信息包括航迹、状态监控等所有非一次视频的信息。在软件方案中,采用了Overlay功能实现。目前通用显卡都支持此功能。
Overlay如同显示器前一块透明的切片,如图6所示。当需要显示Overlay时,可同时看到Overlay部分和Primary Surface没有被Overlay遮挡的地方。当不需要显示Overlay时,移除Overlay,原来的Primary Surface内容不变,也就是说Primary Surface与Overlay的内容物理上是分开的。而是否显示Overlay,由Primary Surface上像素的颜色来决定。当Primary Surface上某些区域的像素设为一种特殊的颜色时,这些区域显示的就是Overlay上的内容。这种起过滤作用的颜色称为Color Key。这种显示机制完全由显卡的CPU完成,所以当使用Overlay功能时,程序不会有明显的性能损失。不同的显卡,Color Key可能不一样。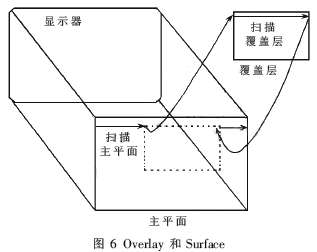
Overlay有多种模式,最常用的是YV12_OVERLAY,Y:U:V=4:2:2。本系统采用了这种模式。
YUV Overlay的一个特点是:适当地固定U、V,可以近似地固定颜色种类,改变Y就相当于改变亮度。测试还表明,在Overlay上显示视频比在Primary Surface上显示要少占用CPU资源。相比Primary Surface 上的RGB显示方式,这些特性很适合于PPI显示一次视频。
一次和二次分层显示的实现方法是:首先将Primary Surface上位于PPI扫描区域内的所有像素都填上特殊的Color Key,这样保证在与Primary Surface关联的Overlay上的一次视频可见;需要显示二次信息的地方用不同于Color Key的其它颜色填在Primary Surface层上;当不需要显示二次信息时,只需在Primary Surface上将原来的二次信息用Color Key颜色再写一遍即可。
3.2 网络化的显示应用程序框架结构
由于接收网络组播的视频帧包是一种阻塞操作,而GUI程序的主线程不能有阻塞操作,所以网络接收部分应该放在子线程或子进程中。
系统首先选择了子线程方式,试验表明在这种方式下显示部分不均匀。这是因为CPU调度的对象是进程,进程内的线程同时竞争CPU分给该进程的时间片,于是就会出现在某段时间内主线程一直占用CPU,另一段时间网络部分的子线程占用CPU。网络接收虽然不会丢包,但是接收速度的不均匀引起了显示的不均匀。系统又试验了子进程方式,发现显示效果有所改观,但是改进不大。
设想一下,如果有两个CPU,并行运行父进程和子进程,那么整体运行效率就会有很大程度的提高。因为,CPU几乎不需要在不同的进程之间反复切换了。
系统中选用具有超线程功能的Intel Pentium 4处理器,如果操作系统能够支持SMP(Symmetric Multiple Processing),那么一个CPU相当于两个CPU,两个进程就可以并行处理。实际上,Linux2.4版本的内核就支持SMP了。系统选择的内核版本是2.6.8,手工编译内核,选用SMP功能。用新的内核运行同样的程序,显示很平滑,最快显示速度达到一圈2s以内,性能得到了明显提高。Linux内核的灵活定制特性在系统中起关键作用。
图7是主显机上网络化显示程序的框架。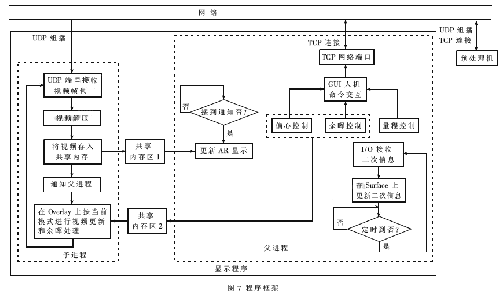
兼顾平等,父子进程尽量平均分担负载。Linux有许多实现进程间通信的机制:管道、消息队列、共享内存等。系统中选择共享内存方式,因为这是进程间通信最快捷的方式。框架中,二次信息通过I/O口进入主显机,由于其数据率比较低,所以系统采用定时的方法进行访问更新。
本文论证了基于Linux的软件化、网络化雷达终端系统的实现可行性,并提出了一套切实可行的实现方案,对方案中的关键技术做了必要的阐述。这套方案的推广对目前国内雷达终端系统具有革命性的意义。
- REDIce-Linux--灵活的实时Linux内核(11-12)
- linux文件系统基础(02-09)
- Linux标准趋向统一(11-12)
- linux基础技术(02-09)
- LINUX的目录树(02-09)
- 在Windows下启动Linux(02-09)