参数化可配置IP核浮点运算器的设计与实现
参数化可配置技术是指在集成开发环境下,利用设计中的可配置资源,根据需求重新配置一个运算系统,以实现兼顾高性能硬件设计和可配置特征的系统,即成为参数化可配置运算系统。参数化可配置系统的原理是:通过对参数可配置元件的利用,将硬件系统由专门的电路设计转变成为功能模块的组装,因此具有灵活、高效、低耗、易于开发与升级等特性。
在混沌电路、信号及图像处理中有大量的浮点数加、减、乘、除操作,浮点数本身的复杂性决定其需要专用的硬件来实现[1]。传统硬件电路的实现依靠手工搭建,过程复杂,存在电路参数分布性大、元器件老化、易受温度影响及通用性差等问题,尤其是对网格状多涡卷混沌吸引子的电路设计和调试需要花费更多时间。此外,要求电路设计者要有较高的技巧和经验[2]。基于IP核模块的设计方法是采用IP核模块而不是采用基本逻辑或电路单元作为基础单元,是以功能组装代替功能设计,用户只需通过设置参数即可方便地按需要定制自己的宏功能模块。使用户可以将精力集中于系统顶层及关键功能模块的设计上,致力于提高产品整体性能和个性化特性,加快了芯片设计速度,提高了芯片设计能力。
此外,IP核通常要经过严格的测试和优化,并且已经封装完毕,利用IP核进行电路设计可以在FPGA等可编程逻辑器件中达到最优的性能和最低的逻辑资源使用率,以保证电路的性能和质量。基于参数可配置IP核的浮点运算器的设计可大大提高混沌电路及其他电路设计者的电路设计能力,有力推动了混沌电路在相关领域的应用。
1 参数化IP核
IP核的本质特征之一是可重用性,在不同的应用场合对IP核功能、性能、面积及功耗等要求也不同,这就要求IP核具有较好的可伸缩性和灵活性。为了使IP核在使用中具有更好的灵活性和可配置性,IP核应该被设置为参数化可配置的。根据参数配置时机的不同,参数化IP核的配置参数可分为静态参数和动态参数[3]。
(1)静态参数:静态参数是指在系统运行前,一次性将参数化IP核的参数配置为系统所需的某个或数个功能,这些配置好的功能,在系统运行期间不会改变,直到系统完成任务后,参数化IP核才配置成为其他功能去完成其他任务。也就是说,当硬件要重新配置参数时,系统必须先停止运行,待参数配置完成后系统才能继续运行。
(2)动态参数:动态参数是在系统运行过程中,可随时重新配置参数化IP核的功能,参数配置与系统运行是同时的。因此,在设计IP核的动态参数时,必须先把参数配置所需的电路模块包含在其中,并将可配置的参数保存在寄存器中,这样在系统运行时才能随时配置参数调用所需的功能。图1为动态参数的控制结构。
(3)动态参数与静态参数的比较:动态参数的使用大大提升了IP核的运行灵活性,但其缺点也很明显。因为动态参数属于“运行时配置”的参数。采用动态参数设计的IP核,在设计时已经将所有的功能模块包含在电路中,通过参数寄存器来实时选择IP核的功能,因此,电路设计功能越多、参数越复杂,其芯片面积的占用和功耗也越大。而静态参数属于“编译时配置”的参数[4],它在流片之前就已经将IP核的参数确定好,因而在实现过程中不会产生冗余电路,减小了设计成本。
2 参数化浮点运算器IP核设计
在参数化浮点运算器IP核的设计中,由于浮点减法器与浮点除法器都可通过参数化浮点加法器和参数化浮点乘法器实现,故本设计只重点探讨参数化浮点加法器和参数化乘法器的优化算法和设计技术。
2.1参数化浮点加法器设计
浮点加/减法在浮点运算中占有很大的比例,在浮点加法器的设计中,尾数的计算是影响浮点运算性能的关键,而其中进位运算对尾数计算速度影响最大。因此,围绕如何提高浮点运算器的进位产生速度,科研人员在传统串行的行波进位加法器的基础上,提出了一些并行快速产生进位的方法,如:超前进位加法器CLA(Carry Look-ahead Adder)、条件进位选择CCS(Conditional Carry-Selection)加法器等。本文采用的是对超前进位加法器改进后的、适用于参数化浮点运算器设计的分块超前进位加法器BCLA(Block Carry Look-ahead Adder)。
2.1.1 分块超前进位加法器算法
图2是一个 4 bit超前进位加法器模块,通过将数个CLA分成相同大小分组级联,组间采用行波进位的方式连接,以加强加法器件的模块性。
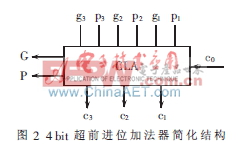

依据式(1),组间产生和传递的进位,可以采用相类似的方式产生,通过增加一个组间CLA以组合方式设计成为分块超前进位加法器组合电路。图3为采用BCLA以及CLA组合设计的16 bit加法器逻辑图。对于n位操作数的加法,可将其分为n/4个分组,每4 bit一个CLA的模块完成一次超前进位运算需要2ΔG的时间(假设每个门电路延迟为ΔG)。其中需要1ΔG的时间产生Pi和Gi,2ΔG的时间来产生本位输出,因此,整个电路的总运算时间为:
- 基于FPGA的DSP设计方法(08-26)
- 电力电子装置控制系统的DSP设计方案(04-08)
- 基于DSP Builder的VGA接口设计(04-10)
- 基于DSP和USB的高速数据采集与处理系统设计(05-01)
- 数字信号处理(DSP)应用系统中的低功耗设计(05-02)
- 基于DSP的嵌入式显微图像处理系统的设计(06-28)