TI 全新TMS320C66x 定点与浮点DSP内核成功挑战速度极限
德州仪器 (TI) 全新 TMS320C66x 数字信号处理器 (DSP) 内核不仅为屡获殊荣的 C64x+™ 指令集架构 (ISA) 带来了显著的性能提升,同时还在同一处理内核中高度集成了针对浮点运算的支持。浮点处理技术首次能够用于传统上仅能满足定点处理运行速度要求的处理器中。该 C66x DSP 的 ISA 同时支持单精度和双精度浮点操作,并全面兼容 IEEE 754 标准。这一完美组合造就了无与伦比的DSP,能够在完全无损定点或浮点功能的情况下将浮点优势引入高速嵌入式架构中。与其它很多可提供浮点协作单元的嵌入式处理器不同,TI 最新 C66x DSP 内核直接将浮点指令集嵌入到C64x 定点指令集中。在C66x CPU上,用户可以选择逐条执行浮点、定点指令,因为在 C66x 中浮点与定点运算能力已经被完全集成在一起。正是由于这样,到底使用定点 DSP 还是浮点 DSP 已不再是设计上的挑战,因为 C66x DSP 做到了双全其美。
在同一 DSP 内核中集成定点与浮点功能将使嵌入式系统算法的开发与部署方式发生根本性变革。这听起来似乎有点夸大其辞,不过事实的确如此。在定点数字系统中实施算法所付51系列串口通讯例程出的艰辛是不可估量的。但充分满足对速度的需求又使这一工作势在必行,因为到目前为止市面上还没有任何可供使用的快速浮点DSP。我们能够轻松、便捷地将采用 Matlab 等浮点运算工具开发的算法移植到 DSP 中,而无需费力转换为定点方式处理。借助 TI 新型 C66x DSP 的浮点计算能力,大多数转换工作已显得没有任何必要。
对二进制数字表示的回顾
包含 TI DSP 等在内的所有数字处理器均采用带比特串(0 和 1 组成)的二进制形式表示数字。数字表示精度取决于所使用的比特位数和表示格式两个方面。
定点系统使用比特表示一个固定取值范围,这些值既可以是整数,也可以是具有固定数量的整数及小数位的数字。动态取值范围因而显得十分有限,而且超出设定范围的值必须达到端点。
定点处理器通常采用每秒乘法计算次数表示其 16 位运算性能。为了充分利用处理器的处理能力(例如,为获得其宣称的全部性能),为这些处理器开发的算法不得不在一系列预先确定范围的数字上进行操作。在定点实施过程中无法高效执行难以预知范围或变化幅度大的数据集。
浮点表示通过采用科学计数法来提供更广的动态范围,从而可使用尾数(或叫有效数字)及指数进行表示。C66x 内核可对 32 个比特位表示的数值实施单精度浮点运算,其采用的表示形式如下:(−1)5 × M × 2(N−127),其中 S 表示符号位,M 表示尾数或有效数字位,而 N 则表示指数。S 只有一个比特位,N 有 8 个比特位,而 M 以 23 个比特位表示。 这样,数字表示范围为 2−127 − 2128,并具有 24 比特精度的有效位。相比而言,16 比特位的定点算法仅能表示 216 个数值(从 0 到 65535),故其内在数字表示的可变范围要小很多。所以当数据集或工作在该数据集上的算法不可预知、动态变化幅度很大的情况下,浮点数字表示法更受青睐。另外很重要的一点是,有效数字始终以‘1’作为第一个数字,因此其数值始终保持 24 位精度。
TI 如何创造性地在同一内核中同时集成浮点与定点技术最新 C66x DSP 内核 —— 图 1 显示的 C64x+ DSP 是 TI 最新 C66x DSP 的前代产品。该内核由两个对称的部分 (A B) 组成,每部分具有四个功能单元。一个 .M 单元包含 4 个 16 位乘法器。
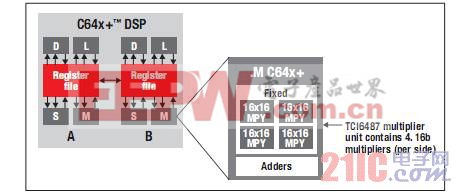
图 1 - TI C64x+ DSP
图 2 所示的 TI 最新 C66x 内核具有同 C64x+ 内核相同的基本 A B 结构。请注意,.M 单元的 16 位乘法器已增至每个功能单元 16 个,从而实现内核原始计算能力提升 4 倍。C66x DSP 实现的突破性创新使得由 4 个乘法器组成的各群集可协同工作以实施单精度浮点乘法运算。
图 2 - TI 最新 C66x DSP 内核
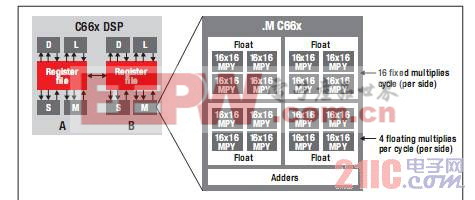
C66x DSP 内核可同时运行多达八项浮点乘法运算,加之高达 1.25 GHz 的时钟频率,使其当之无愧地成为市场上性能最高的浮点 DSP。将多个 C66x DSP 内核进行完美整合,即可创建出具有出众性能的多内核片上系统 (SoC) 设备。
浮点技术的成本为使定点与浮点组件都能同时实现最佳性能,TI 专为该款最新的 C66x 内核开发了全新的浮点与定点指令,所有这些都对实现高效率的无线信号处理至关重要。由于采用浮点符号会带来额外的计算复杂度,从而导致了定点与浮点处理器“分庭抗礼”的局面。在定点运算情况下,加法、乘法等基本操作简单易行,但在浮点运算情况下,这些基本操作需要做更多工作量。比如两个浮点数相乘的情形:
成功 挑战 速度 极限 内核 DSP 全新 TMS320C66x 定点 相关文章:
- 将FATFS移植STM32RBT6遇到的挂载不成功和返回值问题(2)(11-27)
- FTAFS移植f_mount 挂载成功f_open失败问题(1)(11-27)
- 将FATFS移植STM32RBT6遇到的挂载不成功和返回值问题(11-27)
- 成功移植NET-SNMP到ARM平台(11-11)
- cramfs根文件系统的移植成功(fs2410下亲测)(11-11)
- STC单片机下载不成功的原因分析(09-14)