Navigator Runtime 最大限度提高多内核效率
ntime 的完美结合是一款功能强大的独特解决方案。
Navigator Runtime 的主要功能是将工作任务分配给多个内核。先将工作任务放入待执行的虚拟队列,然后由嵌入在多内核导航器硬件中的 uRISC 内核执行中央调度。调度器根据优先级、原子性以及本地性选择工作任务,然后分配给软件分配器。软件分配器是驻留在每一个内核中的 Navigator Runtime 的必备部件。分配器随即将每项工作任务发送至处理元件执行,处理元件可能是内核、AccelerationPac 或 I/O 端点中的线程。
充分发挥多内核导航器的作用,工作任务制定者及使用者的抽象可由 Navigator Runtime 完成。将嵌入式 uRISC 内核用于集中调度工作(无需消耗主 DSP 或 ARM? 内核的 MIPS),可实现低开销、低时延以及每个内核 25 万个任务的高吞吐量,实现无与伦比的并行编程性能。
图 3 主要展示 Navigator Runtime 概念及其与多内核导航器的互动。
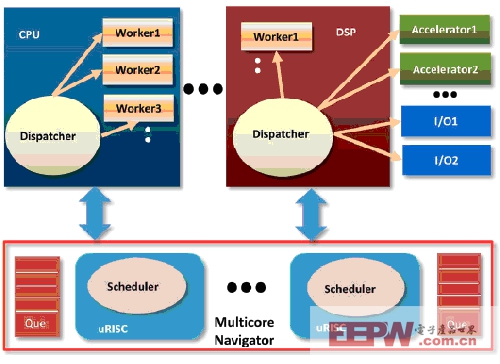
图 3:Navigator Runtime 与多内核导航器的互动
多内核性能可使用加速性进行测量,加速性的定义是用单内核串行执行时间除以多内核执行时间。在理想条件下,8 内核系统的加速性等于 8。但在实际中,由于多内核总线判优、存储器访问时延、高速缓存一致性管理、同步以及 IPC 等多内核开销的影响,典型加速性与理想条件相距甚远。Navigator Runtime 消耗的开销极少,以尽量接近理想加速性,实现多内核性能的最大化。
以 LTE 上行链路物理层处理为例,串行代码可细分为 1,024 个工作任务用于实现天线数据处理、通道估算以及均衡等。平均每个工作任务有 4K 输入数据及 2K 输出数据驻留在共享存储器中。Navigator Runtime 将用于调度这些工作任务并分配给 8 个不同的内核,故加速性的计算如下:
8 内核加速性 = 采用本地 L2 存储器中的数据单内核串行执行代码的时间 ÷ 采用共享 DDR3 存储器中的数据 8 内核并行执行的时间
在并行 8 内核执行示例中,在处理前可分配多个导航器数据包 DMA 通道将 DDR3 中的数据预加载到本地 L2 存储器中,并在处理后将数据从 L2 返回至 DDR3,就像为降低存储器访问时延的 CPU 高速缓存运行一样。结果所测得的 KeyStone 器件的加速性为:在 3.2 万个周期的工作任务中,从 8 内核 KeyStone 器件中测得的基准数据可实现 7.8 的加速性,而在 1.6 万个周期的工作任务中,其则可实现 7.7 的加速性,非常接近理想的 8 加速性。与 KeyStone I 相比,KeyStone II 中的导航器已得到了明显的改进:4倍uRISC 引擎数量可实现更多的调度资源,而数据包 DMA 通道、硬件队列以及描述符数量翻番,则可提高执行吞吐量。
图 4 为 KeyStone Navigator Runtime 在各种工作任务量情况下,2 至 8 内核的实际加速性与理想加速性的比较。
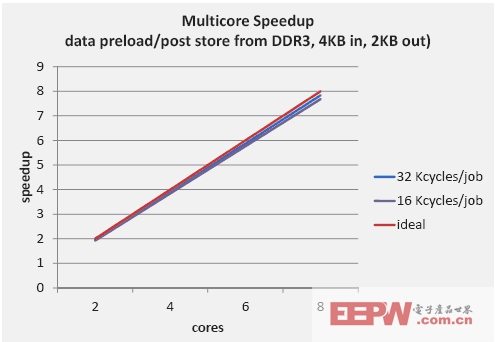
图 4:采用 Navigator Runtime 实现的多内核加速性
此外,TI KeyStone II 架构还可为所有异构内核提供 6MB 的片上共享存储器(MSMC 存储器)容量。MSMC 的存储器访问性能非常接近 L2 存储器访问性能。当数据存储在 MSMC 中时,无需使用导航器预加载和后存储数据,便可实现与上面情况类似的加速性。与其它可选解决方案相比,大型片上共享存储器可利用低系统时延为多内核性能带来独特的优势。
Navigator Runtime 不但可支持各种系统应用,而且还能够与 OpenMp 等高级多内核编程范式集成。
OpenMP 是一款支持多平台共享存储器多处理编程的应用编程接口 (API),由编辑器指令、运行时库程序以及环境变量构成。在 OpenMP 中,用户可使用语言指令(例如编译器指令)来识别其软件中的并行性,也可使用工具帮助识别。使用兼容 OpenMP 的编译器可读取编译指令,其可将编译指令所注释的串行代码转换成并行代码,并在 OpenMP 运行时中插入调用。对在特定器件上运行的应用而言,多内核编程方法的运行时时延及开销性能将会限制可实现的并行性。更低的时延与开销可在应用中实现并行化创造更好的条件,进而实现更高的多内核效率。
开始已经为共享存储器架构指定了 OpenMP。我们现在讨论分布式存储器及异构处理器架构支持。TI Navigator Runtime 可用作 OpenMP 的运行时系统。多内核同步与 IPC 可使用导航器中的数据包 DMA 引擎有效处理。前面的基准显示,将 Navigator Runtime 用作 OpenMP 运行时不但可显著降低编译器指令的构建开销,而且还可显著提升多内核系统内的并行性,让编程人员专注于识别并行任务。调度及负载均衡由 Navigator Runtime 自动管理,不但可简化编程,而且还可最大限度地提高多内核效率。
下页图 5 显示的是使用 Navigator Runtime 与 Open
NavigatorRuntime 多内核效率 KeyStoneAMP 相关文章:
- Windows CE 进程、线程和内存管理(11-09)
- RedHatLinux新手入门教程(5)(11-12)
- uClinux介绍(11-09)
- openwebmailV1.60安装教学(11-12)
- Linux嵌入式系统开发平台选型探讨(11-09)
- Windows CE 进程、线程和内存管理(二)(11-09)