透过Linux内核看无锁编程
[lid];
if(out==NULL){
rcu_read_unlock();
returnNULL;
}
……
returnout;
}
staticintgrow_ary(structipc_ids*ids,intnewsize)
{
structipc_id_ary*new;
structipc_id_ary*old;
……
new=ipc_rcu_alloc(sizeof(structkern_ipc_perm*)*newsize+
sizeof(structipc_id_ary));
if(new==NULL)
returnsize;
new->size=newsize;
memcpy(new->p,ids->entries->p,sizeof(structkern_ipc_perm*)*size
+sizeof(structipc_id_ary));
for(i=size;inew->p[i]=NULL;
}
old=ids->entries;
/*
*Usercu_assign_pointer()tomakesurethememcpyedcontents
*ofthenewarrayarevisiblebeforethenewarraybecomesvisible。
*/
rcu_assign_pointer(ids->entries,new);
ipc_rcu_putref(old);
returnnewsize;
}
纵观整个流程,写者除内核屏障外,几乎没有一把锁。当写者需要更新数据结构时,首先复制该数据结构,申请new内存,然后对副本进行修改,调用memcpy将原数组的内容拷贝到new中,同时对扩大的那部分赋新值,修改完毕后,写者调用rcu_assign_pointer修改相关数据结构的指针,使之指向被修改后的新副本,整个写操作一气呵成,其中修改指针值的操作属于原子操作。在数据结构被写者修改后,需要调用内存屏障smp_wmb,让其他CPU知晓已更新的指针值,否则会导致SMP环境下的bug。当所有潜在的读者都执行完成后,调用call_rcu释放旧副本。同Spinlock一样,RCU同步技术主要适用于SMP环境。
环形缓冲区是生产者和消费者模型中常用的数据结构。生产者将数据放入数组的尾端,而消费者从数组的另一端移走数据,当达到数组的尾部时,生产者绕回到数组的头部。
如果只有一个生产者和一个消费者,那么就可以做到免锁访问环形缓冲区(RingBuffer)。写入索引只允许生产者访问并修改,只要写入者在更新索引之前将新的值保存到缓冲区中,则读者将始终看到一致的数据结构。同理,读取索引也只允许消费者访问并修改。
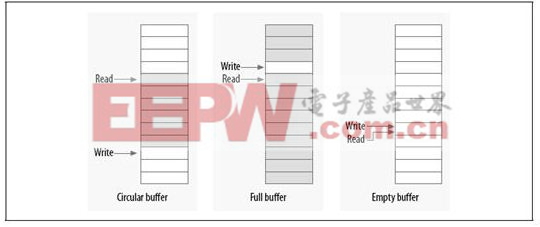
图2。环形缓冲区实现原理图
如图所示,当读者和写者指针相等时,表明缓冲区是空的,而只要写入指针在读取指针后面时,表明缓冲区已满。
清单9。2。6。10环形缓冲区实现代码
/*
*__kfifo_put-putssomedataintotheFIFO,nolockingversion
*Notethatwithonlyoneconcurrentreaderandoneconcurrent
*writer,youdon'tneedextralockingtousethesefunctions。
*/
unsignedint__kfifo_put(structkfifo*fifo,
unsignedchar*buffer,unsignedintlen)
{
unsignedintl;
len=min(len,fifo->size-fifo->in+fifo->out);
/*firstputthedatastartingfromfifo->intobufferend*/
l=min(len,fifo->size-(fifo->in(fifo->size-1)));
memcpy(fifo->buffer+(fifo->in(fifo->size-1)),buffer,l);
/*thenputtherest(ifany)atthebeginningofthebuffer*/
memcpy(fifo->buffer,buffer+l,len-l);
fifo->in+=len;
returnlen;
}
/*
*__kfifo_get-getssomedatafromtheFIFO,nolockingversion
*Notethatwithonlyoneconcurrentreaderandoneconcurrent
*writer,youdon'tneedextralockingtousethesefunctions。
*/
unsignedint__kfifo_get(structkfifo*fifo,
unsignedchar*buffer,unsignedintlen)
{
unsignedintl;
len=min(len,fifo->in-fifo->out);
/*firstgetthedatafromfifo->outuntiltheendofthebuffer*/
l=min(len,fifo->size-(fifo->out(fifo->size-1)));
memcpy(buffer,fifo->buffer+(fifo->out(fifo->size-1)),l);
/*thengettherest(ifany)fromthebeginningofthebuffer*/
memcpy(buffer+l,fifo->buffer,len-l);
fifo->out+=len;
returnlen;
}
以上代码摘自2。6。10内核,通过代码的注释(斜体部分)可以看出,当只有一个消费者和一个生产者时,可以不用添加任何额外的锁,就能达到对共享数据的访问。
总结
通过对比2。4和2。6内核代码,不得不佩服内核开发者的智慧,为了提高内核性能,一直不断的进行各种优化,并将业界最新的lock-free理念运用到内核中。
在实际开发过程中,进行无锁设计时,首先进行场景分析,因为每种无锁方案都有特定的应用场景,接着根据场景分析进行数据结构的初步设计,然后根据先前的分析结果进行并发模型建模,最后在调整数据结构的设计,以便达到最优。
- Reed Solomon编解码器的可编程逻辑实现(06-21)
- 基于TMS320C62X DSP的混合编程研究(07-12)
- 基于JTAG的DSP外部FLASH在线编程与引导技术(01-22)
- 基于嵌入式系统的手机编程开发平台(07-30)
- DSP编程的几个关键问题(10-01)
- 基于VxWorks的MB系列智能可编程控制器设计(01-16)