片上多核处理器共享资源分配与调度策略研究综述(三)
接上文
片上多核处理器共享资源分配与调度策略研究综述(二)
3 联合调度
前面两章分别对于共享缓存和DRAM 提出了相应的调度算法,但这只是系统中众多共享资源里最为重要的两种。实际上在多线程环境下,线程还会对于其他包括系列总线和I/O 设备等共享资源进行争夺,线程间互相干扰,对系统性能造成影响。
一方面,针对不同的共享资源独立提出的调度算法间从效果上可能互相矛盾。例如,同一个线程在共享缓存和主存处分别表现出的访存行为特征未必一致,再根据各自的调度策略,分别设定的优先级可能相反,使得调度失效。另一方面,从不同层面提出的调度策略之间也可能存在矛盾。例如,底层硬件层面的调度对线程的优化可能使得操作系统层面对于线程优先级的设定反转。因此,从全局出发,综合考虑所有共享资源,进行联合调度是极有研究价值的。
Ebrahimi 等在文献中为了解决线程的公平性问题,提出一个可以协调所有共享存储资源的机制称为公平性资源节源( fairness via sourcethrottling,FST),从而避免了需要为系统中每个共享存储资源提出单独的公平性机制。该机制使用前面在STFM中提到的线程减速比Mi=Tshd_i/Tsolo_i信息 , 用一组失效状态信息寄存器(miss statusholding/informatiON registers,MSHRs)记录各线程发向共享存储系统的请求,请求得到服务后相应寄存器清空,当没有可用的MSHRs 时,则禁止该线程向共享存储系统发送请求。系统的不公平性通过下式衡量:
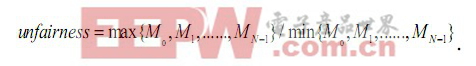
当unfairness 超过某个设定阈值时,表示有线程的性能降低程度已经严重影响到系统的公平性。可以通过调节可用MSHRs 数目来限制侵略性最强(或受影响最小)的线程向共享存储系统发送访存请求的速率,直到各线程的减速比基本保持一致水平,即unfairness 小于设定阈值,恢复受限制线程发送访存请求的能力。这个方法从源头上限制对共享存储资源的不公平性使用,从而无需从单个共享存储资源特别提出公平性的调度策略。
由于对DRAM 进行访存的速度提升远不及处理器速度的提升,访存DRAM 所带来的延迟常常是影响性能的一个关键因素。一个解决方案是,预测线程可能需要的数据,在处理器实际用到该数据之前就发送访存请求从DRAM 取回数据。该技术称之为预取(prefetching),已被证明确实能够有效改善系统性能,并被用于大多数商业处理器中。
然而,各个线程发向DRAM 的预取请求,同样存在对于系统资源的争夺和线程间的干扰,从而抵消由于预取部件所带来的性能改善。Ebrahimi 等人在文献中提出了分层预取侵略性控制( hierarchical prefetcher aggressiveness control ,HPAC),类似于文献[24]中的FST,HPAC 通过从源头上限制预取请求的发送来改善系统的预取性能。
为了降低问题的复杂性,之前提出的调度策略都是针对没有采用预取技术的情况。为了更好地改善系统性能,我们总是希望调度策略和预取技术能够同时生效。然而,实验发现,即使采用已被证明有效的调度策略,在加入预取技术之后,调度策略仍然可能失效,使系统的性能受到影响。因此,Ebrahimi 等人在文献中的研究,解决了预取技术与调度策略的共存问题,并将文献中提出的FST 和HPAC 相结合。该项研究的基本思想包括如下几点:首先,预取请求涉及的通常只是处理器未来可能用到的数据,而非当前急需的数据,因此,除非某些预取请求有着和普通访存请求同样的重要性,预取请求的优先级应该低于普通的访存请求;其次,在所有访存请求中优先来自延迟敏感型线程的访存请求;并且,对预取请求按重要性分配不同的优先级;最后,FST 中对于处理器发送请求的调节可能与HPAC 对于预取请求的调节存在矛盾,通过协同考虑处理器和预取部件,可以有效降低对系统性能的影响。
Ebrahimi 等人在文献中的探索对于解决系统共享资源的联合调度是很好的启发。这些调度策略将所有共享资源抽象为一个整体,从源头上解决系统的公平性问题,但是并没有充分利用具体共享资源的访存特点。若能够将不同层次的调度策略有效结合起来,将会对对系统的性能有进一步的改善。
4. 研究展望
随着处理器核规模的增长,多线程对于有限的共享资源的争夺将愈发激烈,由此导致的对于系统性能的影响也将更加显着。为了缓解乃至解决这一问题,除了增加可用共享资源外,一个能够公平有效地在多线程间分配共享资源的调度算法也至关重要。学术界对此投入了大量的精力与时间。在各类共享资源中,对于系统性能有着最大影响的是共享缓存和DRAM 带宽。已有的研究也大多基于此,并已经取得了大量研究成果。
在第1 节
- 基于DSP的音频会议信号合成算法研究(05-10)
- 基于定点DSP的MP3间频编码算法研究(07-04)
- DSP的并联电力有源滤波器的仿真研究(02-15)
- PCI总线数据采集系统的硬件研究(09-12)
- PIC单片机在温度测量领域的应用及仿真研究(11-23)
- 嵌入式软PLC 的设计与研究(06-27)