从4004到core i7:处理器的进化史 (3)-1—万事开头难
其中我们假设1和2分别存在mem1和mem2里,运算结果存在mem3里
从上面的伪汇编码,再结合算术的类比,我们想到:
我们必须有一张纸来记住题目和答案->CPU必须有存储器(memory)、寄存器(register)的配合
我们必须会计算加法->CPU中必须有算术-逻辑单元(Arithmetic Logic Unit,ALU)。
我们需要理解纸上的符号->CPU需要有指令译码(instruction decode)器
纸上的符号被理解之后还要被我们转移到脑海中至少短暂地被记住->CPU需要有与存储器直接进行交涉的加载/存储单元(load/store unit)
我们需要从试卷上的一大堆题目中选择一道我们将要完成的题目->CPU需要有取指(instruction fetch)单元
上面的例子中我们已经涉及到了几乎全部的CPU子模块。漏下的可能只是分支单元(branch),I/O单元(I/O controller),以及控制上面这么多逻辑的控制器(controller)了。我们得到了第一个CPU模型,正如第一代CPU设计者们用非常straightforward的思考建造的一样。
以上我们从空间上讨论了第一个CPU应该有些什么单元,下面我再列一下从时序上来说一个指令执行分为哪些阶段:
IF = instruction fetch
ID = instruction decode
OC = operhand calculation
EX = execution
WB = result writeback
将上面这5个步骤老老实实重复一遍,一条指令就执行完了。
注意上面的MR步骤对于存储器的操作是只读的,WB步骤对于存储器的操作是只写的。你解题的时候应该不能擅自修改题目的运算数,或者抄袭一个还不存在的答案吧!!
这第一个CPU模型虽然简陋,却能够工作。我们后续将要讨论的高性能处理器无不是处于对它的优化改良而成。
剧透一下,上面的一段代码的另一个极端写法是下面这样的:
add mem1,mem2,mem3.
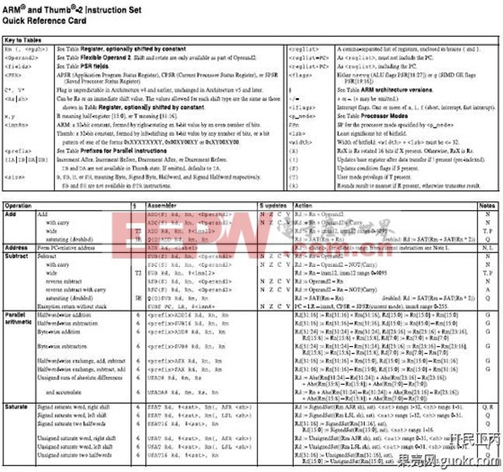
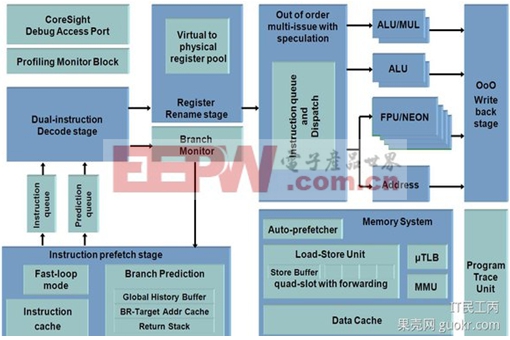
突然发现这一个帖子略长还无图无真相,又懒得找80x86的图,就那下面这两张充充数吧,看看码农和硬农眼中的CPU是多么的不同
- Nut/OS和μC/OS—II的实时调度算法比较 (04-07)
- 基于AT89C51+DSP的双CPU伺服运动控制器的研究(05-26)
- 大容量无线传输技术中高性能DSP 的启动方法(05-04)
- 双CPU在多I/O口系统中的应用(07-05)
- Windows操作系统多核CPU内核线程管理方法(01-21)
- 基于DSP和80C196双CPU构成的高速实时控制系统(01-11)