从4004到core i7:处理器的进化史(3)-4-第一次加速
前面有位童鞋表示对POWER很感兴趣,在这里现在不讲,只贴一张7的die photo,上面已经透露了很多有用的信息了~
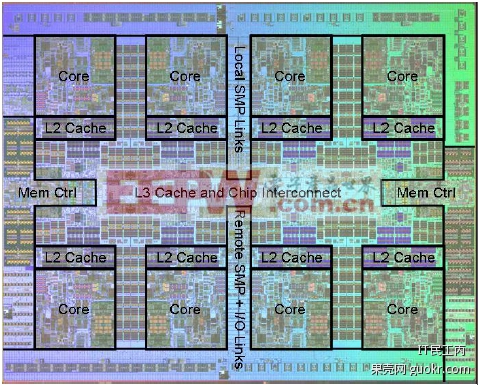
45nm
1,200,000 transistors
8 core-32 thread
32MB L3$
32 slot max
呼~终于忙得差不多鸟~
在这个帖子中,我们会看到处理器设计中的第一次重大飞跃:流水线(pipeline)
为了理解什么是流水线,我们先来看一看一条汽车装配线上的情况:
假设一辆汽车从无到有需要以下4个步骤:
焊接车身
底盘与车身结合
装入发动机
装上轮子
我们再假设发动机、车身的钢板、轮子等等零件都是事先准备好的,它们的存储量是充足的。
假设我们有一台机床,上面有各种机械手,那么我们会怎么造汽车呢?
焊接车身-》底盘与车身结合-》装入发动机-》装上轮子
假设上面每一个环节需要1分钟,那么我们的生产速度是0.25辆/分钟。
当然我们不会这么做,因为福特早就替我们想好了更高效的解决方案:
准备4台机床,每台机床都仅仅具备一个环节的工具即可。每台车在完成一个环节的组装后就立即流向下一个环节。
这样我们可以保证4台机床每一台都不会空闲,并且得到了相当可观的生产速度提升:1辆/分钟。
我们终于有了第一个加速算法:
将整体工作分成N个环节。当这N个环节互相独立的时候,最多可以获得N倍的性能提升。
对于CPU来说,这就相当于主频提升了N 倍!
你可能时常听到所谓的超流水线,就是环节特别多的流水线。
现在你可能可以理解这些流水线被设计出来的初衷了:把任务分割的越细(流水线越深),主频理论上来说就越高。当然,我们会在后面看到,过深过细的流水线反而会损害性能。比如说,intel的netburst。
但是,当这N个环节互相之间产生相互依赖的时候该怎么办呢?
看看以下的伪代码:
...
mov reg1,0
nop(= no operation)
...
nop
mov reg1,1
mov reg2,reg1
nop
nop
...
再回忆一下我们前面说过的指令执行的环节:
IF->ID->OC->EX->WB
假设我们的带流水线CPU恰好就有5个环节分别完成以上的5个步骤,那么在上面的代码中,某时刻:
[ID] mov reg2,reg1
[OC] mov reg1,1
[EX] nop
[WB] nop
下一时刻如果是这样:
[OC] mov reg2,reg1
[EX] mov reg1,1
[WB] nop
就会产生错误:在OC环节进行的是寄存器读,我们本来应该读到reg1=1,但是上面的情况中由于reg1=1没有WB,我们读到了reg=0!
正确地处理应该是这样:
[ID] mov reg2,reg1
[OC]nop
[EX] mov reg1,1
[WB] nop
----------------------------
[ID] mov reg2,reg1
[OC]nop
[EX] nop
[WB] mov reg1,1
-----------------------------
[OC] mov reg2,reg1
[EX] nop
[WB] nop
----------------------------
[EX] mov reg2,reg1
[WB]nop
...
上面的情况叫做数据依赖(data dependency),是降低流水线性能的主要原因。我们对数据依赖的解决办法很简单:
对流水线中的指令更改的寄存器、内存都做记录。在OC环节进行审查,如果该指令读取的寄存器、内存没有挂起的更改(没有还没有WB的更改),就执行读取,否则便要等待直到最近的一条更改读取的指令的WB执行之后才能执行。
对于内存的更改的实际情况要更复杂些,在这个帖子中先不讲,留到后面和超标量网络一起叙述。
在上面的等待过程中,我们在流水线中插入了一些nop指令,这种现象叫做空泡(bubble)。不难想象,在某些有着20多级流水线的CPU中的bubble常常长达十几个环节。
数据依赖产生的最严重的空泡莫过于分支(branch)。你可能经常在C源代码中这样写:
if(sel==1)
{
proc1();
}
else
{
proc2();
}
放到上面的5级流水线中考虑时,我们惊讶地发现:
sel==1这一判断(CMP指令)的结果(常常是状态寄存器的ZF位)要到WB的时候才能知晓,但它影响的却是PC(程序指针)的值,也就是说产生数据依赖的是IF阶段!分支指令可能产生长达5个环节的空泡!
正是由于分支指令对性能的极大损害,现代的CPU常常费尽心思地进行分支预测(branch prediction),期望尽量猜中分支指令执行的结果,尽可能减少极端的长空泡。
不幸的是,分支是任何语言必不可少,甚至是最有用的部分:一个只能顺序向下执行的程序有什么用呢?
你可以想象早期的CPU面对分支语句有多么无力。更加不幸的是,最爱用分支语句的程序恰恰是必不可少的:编译器!传说GCC中就有超过4000个if语句。
下面再从电路的层面上说说pipleline这件事:
CPU的执行引擎(execution
POWER 处理器 CPU 寄存器 pipeline 相关文章:
- 基于PowerPC和嵌入式Linux的VPN网关设计(11-01)
- μC/OS的任务调度实现方法及其在PowerPC上的优化(10-29)
- 基于PowerPC和Linux的VPN网关设计(01-14)
- uCOS-II优先级任务调度在PowerPC上的移植和优化(08-15)
- 全新EDK8.1简化嵌入式设计(06-04)
- 采用Zynq SoC实现Power-Fingerprinting网络安全性(06-04)