基于Xilinx Virtex-6的高速DMA读写设计
数据流向:PC硬盘→PC内存→PCI Express Master DMA Read→下行FIFO数据。
整个DMA读过程如下:(1)复位FPGA逻辑,延时1 ms;去除FPGA逻辑,延时1 ms。(2)检测硬件链路初始化。(3)开启DMA读完成中断。(4)设置DMA读目的地址寄存器,设置DMA读传输长度寄存器。(5)PC硬盘数据转到内存。(6)启动DMA读操作,选择回放路径。(7)等待DMA读完成中断。(8)清除中断,硬盘数据转到内存。(9)DMA读是否结束,是则转至步骤(10);否则转至步骤(4)。(10)终止DMA读,关闭DMA读完成中断,断开回放路径。
下面给出从系统内存到PCI Express Core的DMA读时序,图3是用ChipScope截取的时序图。

T1~T2之间核接收事务接口上m_axis_rx_tvalid与m_axis_rx_tlast共同有效了3次。此处需要说明的是DMA读操作在配置完寄存器后需要先从PC硬盘将数据转到内存开辟的数据缓冲区,此后才能开始DMA读操作,故T1~T2之间核接收事务接口上m_axis_rx_tvalid与m_axis_rx_ tlast有效为配置DMA读地址和启动DMA读操作。当DMA读操作启动后,核的发送事务接口上s_axis_tx_tvalid与s_axis_tx_tlast有效,发送存储器读请求包,当PC收到PCI Express Core发出的存储器读请求包后会根据TLP中的信息回复相应的Cpld完成包。根据PCIExpress总线规范中对PCI Express序的规定,允许接收事务接口在接收Cpld完成包的同时发送事务接口在发送存储器读请求包,见图中T1~T2之间所示。
2.3 PCI Express中断控制
当DMA写结束,即dma_wr_done或dma_rd_done其中之一有效时,用户应该通过配置接口cfg_interrupt和cfg_interrupt_assert来提交中断,当核接收到有效中断时将cfg_interrupt_rdy置为有效,表示中断请求被接受。PC通过读DMA中断寄存器从而认领中断事务,响应处理中断后清除中断。用ChipScope捕获的DMA读写完成中断时序,如图4所示。

3 系统性能测试
系统性能测试结果如表1所示。存储器读写DMA数据有效带宽测试为DMA启动到最后一个存储器写TLP或最后一个存储器读完成包,测试数据总量为8 GB。
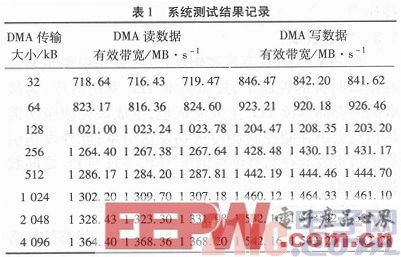
测试平台:Xilinx ML605开发板(Virtex-6 FPGA);Windows7 64位操作系统,Windriver驱动;PCIExpress链路宽度:X8,PCI Express Core版本:V2.5;MaxPayload Size:128 Bytes;Max Read Request Size:512 Byte;Root Complex Read Completion Boundary:64 Byte。
4 结束语
研究了基于Xilinx PCI Express Core的高速DMA读写设计,适用于现代雷达系统和高速数据采集系统的要求,并具有良好的移植和扩展性。文中给出了DMA设计框图,并对系统各部分进行了分析。系统设计中主要研究了PCI Express Master DMA读写设计及中断控制,并给出了DMA读写和中断控制的采样时序,通过系统性能测试数据,可以看出本文所设计的基于Xilinx PCI Express Core的高速DMA读写可以满足高速信号处理的要求。
- DSP+FPGA嵌入式多路视频监控系统硬件平台(04-10)
- FPGA最小系统之:实例2 在Xilinx的FPGA开发板上运行第一个FPGA程序(07-15)
- 利用XPS工具快速生成Virtex FPGA的板级支持包(03-18)
- 利用NI CompactRIO与NI Single-Board RIO实现从快速构造原型到低成本发布(03-19)
- 创建还是购买:什么是您嵌入式设计的最好选择?(07-06)
- Pmod规范,或Arduino伪标准(08-27)