一种基于ARM和CPLD的嵌入式视觉系统设计
集速度要求较高的场合,CPLD部分的程序源代码见本刊网站
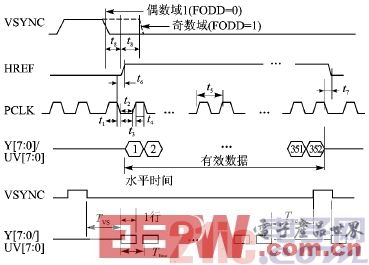
图2 OV6620输出时序图
在Verilog语言中,对上升沿的检测是通过always语句来实现的。例如检测时钟信号cam_pclk的上升沿:

图3 行处理得到的线形图
根据得到的结果,可以计算出更多关于跟踪物体的信息:
① 计算区域面积。计算每条线段的长度l(n),然后将l(n)进行累积叠加,即可获得跟踪区域面积值S。
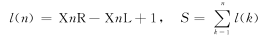
② 计算质心横坐标。
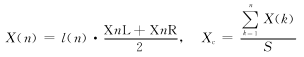
③ 计算质心纵坐标。
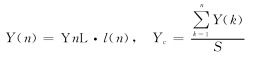
④ 识别物体的形状。根据得到的每行跟踪点的长度,以及同一行中有几段符合要求的连续跟踪点,可以得知物体从摄像头角度看到的形状。特别是在检测平面上线条时,可以识别是否有分支,这一点是帧处理模式无法做到的。
需要指出的是,行处理模式虽然会得到关于跟踪目标的更多信息,但是每行处理的方式增大了处理器的负担,处理速度也没有帧处理快。
4 提高系统的工作速率
目前,系统工作在帧处理模式下的工作速率是25帧/s,作为系统功能的验证,这里采用的算法是颜色跟踪。如果仅做纯粹的图像采集,而不做图像处理,那么系统可以达到OV6620的最高工作速率,即60帧/s。而在图像处理方面,不同的图像处理程序效率对系统的工作频率有较大的影响。下面给出在通用ARM处理器下提高程序效率的几个建议:
① 内嵌(inline)可通过删除子函数调用的开销来提高性能。如果函数在别的模块中不被调用,一个好的建议是用static标识函数;否则,编译器将在内嵌译码里把该函数编译成非内嵌的。
② 在ARM系统中,函数调用过程中参数个数≤4时,通过R0~R3传递;参数个数>4时,通过压栈方式传递(需要额外的指令和慢速的存储器操作)。通常限制参数的个数,使它为4或更少。如果不可避免,则把常用的前4个参数放在R0~R3中。
③ 在for(), while() do…while()的循环中,用“减到0”代替“加到某个值”。比如:
for (loop = 1; loop <= total; loop++) //ADD和CMP
替换为:for (loop = total; loop != 0; loop--) //SUBS
第1种方式比较需要2条指令ADD和CMP,而第2种方式只需一条指令SUBS。
④ ARM核不含除法硬件,除法通常用一个运行库函数来实现,运行需要很多个周期。一些除法操作在编译时作为特例来处理,例如除以2的操作用左移代替余数的操作符“%”,通常使用模算法。如果这个值的模不是2的n次幂,则将花费大量的时间和代码空间避免这种情况的发生。具体办法是使用if()作状态检查。
比如,count的范围是0~59:
count = (count+1) % 60;
用下面语句代替:
if (++count >= 60)
count = 0;
⑤ 避免使用大的局部结构体或数组,可以考虑用malloc/free代替。
⑥ 避免使用递归。
结语
本文介绍了一种基于ARM和CPLD的嵌入式视觉系统,可以实现颜色跟踪。在硬件设计上,图像采集和图像处理分离,更利于系统功能的升级。而视觉处理算法更注重处理的效率和实时性,同时根据不同的需要有两种模式可供选择。最后给出了提高程序效率的一些建议和方法。与基于 PC机的视觉系统相比,该系统功耗低、体积小,适合应用于移动机器人等领域。
- Linux嵌入式系统开发平台选型探讨(11-09)
- 基于ARM体系的嵌入式系统BSP的程序设计方案(04-11)
- 在Ubuntu上建立Arm Linux 开发环境(04-23)
- 达芬奇数字媒体片上系统的架构和Linux启动过程(06-02)
- SQLite嵌入式数据库系统的研究与实现(02-20)
- 革新2410D开发板试用手记(04-21)