用C51编写单片机延时函数
时间:11-13
来源:互联网
点击:
参考了51单片机 Keil C 延时程序的简单研究,自己也亲身测试和计算了一些已有的延时函数。
这里假定单片机是时钟频率为12MHz,则一个机器周期为:1us.
参考了51单片机 Keil C 延时程序的简单研究后,我们可知道, 在Keil C中获得最为准确的延时函数将是
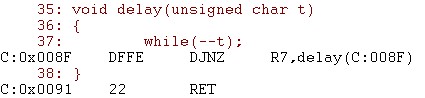
执行DJNZ指令需要2个机器周期,RET指令同样需要2个机器周期,根据输入t,在不计算调用delay()所需时间的情况下,具体时间延时如下:
当在main函数中调用delay(1)时, 进行反汇编如下:
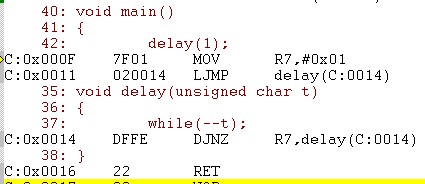
调用delay()时,多执行了两条指令,其中MOV R, #da
Keil C仿真截图与计算过程:


加上调用时间,准确的计算时间延时与Keil C仿真对比如下:(可见,仿真结果和计算结果是很接近的)
也就是说,这个延时函数的精度为2us,最小的时间延时为7us,最大的时间延时为3+255×2+2=515us.
实际中使用11.0592MHz的时钟,这个延时函数的精度将为2.2us,最小时间延时为7.7us, 最大时间延时为566.5us.
这个时间延时函数,对于与DS18B20进行单总线通信,已经足够准确了。
现在,我们将时钟换成11.0592MHz这个实际用到的频率,每个机器周期约为1.1us.
现在让我们来分析一下这个之前用过的延时函数:
它的反汇编代码如下:
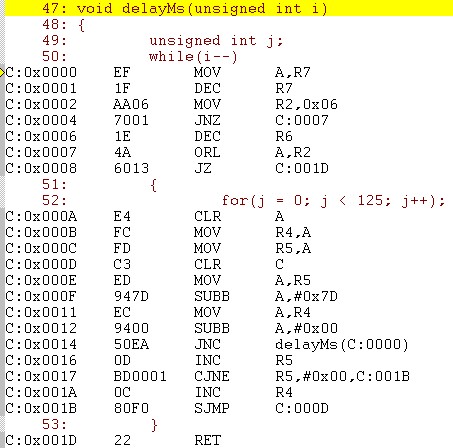
分析: T表示一个机器周期(调用时间相对于这个ms级的延时来说,可忽略不计)
对于delayMs(1), 执行到第7行就跳到21行, 共需时12T, 即13.2us
对于delayMs(2), 需时9T+13T+124×10T+7T+12T = 9T+13T+1240T+7T+12T =1281T =1409.1us.
对于delayMs(3), 需时9T×(3-1)+(13T+124×10T+7T)×(3-1)+12T
=1269T×(3-1)+12T=2550T=2805us.
对于delayMs(N),N>1, 需时1269T×(N-1)+12T = 1269NT-1257T=(1395.9N-1382.7)us.
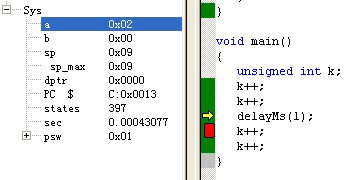
利用Keil C仿真delayMs(1) = 0.00166558s = 1.67ms 截图如下:

由分析可知具体的计算延时时间与Keil C仿真延时对比如下:
经过以上分析,可见用C语言来做延时并不是不太准确,只是不容易做到非常准确而已,若有一句语句变了,延时时间很可能会不同,因为编译程序生成的汇编指令很可能不同。
PS:
对于每条51单片机汇编指令的字长和所需机器周期汇总如下:转自:http://bbs.mcustudy.com/printpage.asp?BoardID=2&ID=1454
Appendix E - 8051 Instruction Set
Arithmetic Operations
MnemonicDescriptionSizeCycles
ADD A,Rn Add register to Accumulator (ACC).11
ADD A,direct Add direct byte to ACC.21
ADD A,@Ri Add indirect RAM to ACC.11
ADD A,#da
ADDC A,Rn Add register to ACC with carry.11
ADDC A,direct Add direct byte to ACC with carry.21
ADDC A,@Ri Add indirect RAM to ACC with carry.11
ADDC A,#da
SUBB A,Rn Subtract register from ACC with borrow.11
SUBB A,direct Subtract direct byte from ACC with borrow21
SUBB A,@Ri Subtract indirect RAM from ACC with borrow.11
SUBB A,#da
INC A Increment ACC.11
INC Rn Increment register.11
INC direct Increment direct byte.21
INC @Ri Increment indirect RAM.11
DEC A Decrement ACC.11
DEC Rn Decrement register.11
DEC direct Decrement direct byte.21
DEC @Ri Decrement indirect RAM.11
INC DPTR Increment da
MUL AB Multiply A and B Result: A <- low byte, B <- high byte.14
div AB Divide A by B Result: A <- whole part, B <- remainder. 14
DA A Decimal adjust ACC.11
Logical Operations
MnemonicDescriptionSizeCycles
ANL A,Rn AND Register to ACC.11
ANL A,direct AND direct byte to ACC.21
ANL A,@Ri AND indirect RAM to ACC.11
ANL A,#da
ANL direct,A AND ACC to direct byte.21
ANL direct,#da
ORL A,Rn OR Register to ACC.11
ORL A,direct OR direct byte to ACC.21
ORL A,@Ri OR indirect RAM to ACC.11
ORL A,#da
ORL direct,A OR ACC to direct byte.21
ORL direct,#da
XRL A,Rn Exclusive OR Register to ACC.11
XRL A,direct Exclusive OR direct byte to ACC.21
XRL A,@Ri Exclusive OR indirect RAM to ACC.11
XRL A,#da
XRL direct,A Exclusive OR ACC to direct byte.21
XRL direct,#da
CLR A Clear ACC (set all bits to zero).11
CPL A Compliment ACC.11
RL A Rotate ACC left.11
RLC A Rotate ACC left through carry.11
RR A Rotate ACC right.11
RRC A Rotate ACC right through carry.11
SWAP A Swap nibbles within ACC.11
Da
MnemonicDescriptionSizeCycles
MOV A,Rn Move register to ACC.11
MOV A,direct Move direct byte to ACC.21
MOV A,@Ri Move indirect RAM to ACC.11
MOV A,#da
MOV Rn,A Move ACC to register.11
MOV Rn,direct Move direct byte to register.22
MOV Rn,#da
MOV direct,A Move ACC to direct byte.21
MOV direct,Rn Move register to direct byte.22
MOV direct,direct Move direct byte to direct byte.32
MOV direct,@Ri Move indirect RAM to direct byte.22
MOV direct,#da
MOV @Ri,A Move ACC to indirect RAM.11
MOV @Ri,direct Move direct byte to indirect RAM.22
MOV @Ri,#da
MOV DPTR,#da
MOVC A,@A+DPTR Move co
MOVC A,@A+PC Move co
MOVX A,@Ri Move external RAM to ACC (8 bit address).12
MOVX A,@DPTR Move external RAM to ACC (16 bit address).12
MOVX @Ri,A Move ACC to external RAM (8 bit address).12
MOVX @DPTR,A Move ACC to external RAM (16 bit address).12
PUSH direct Push direct byte on
POP direct Pop direct byte from stack.22
XCH A,Rn Exchange register with ACC.11
XCH A,direct Exchange direct byte with ACC.21
XCH A,@Ri Exchange indirect RAM with ACC.11
XCHD A,@Ri Exchange low order nibble of indirect RAM with low order nibble of ACC.11
Boolean Variable Manipulation
MnemonicDescriptionSizeCycles
CLR C Clear carry flag.11
CLR bit Clear direct bit.21
SETB C Set carry flag.11
SETB bit Set direct bit.21
CPL C Compliment carry flag.11
CPL bit Compliment direct bit.21
ANL C,bit AND direct bit to carry flag.22
ANL C,/bit AND compliment of direct bit to carry.22
ORL C,bit OR direct bit to carry flag.22
ORL C,/bit OR compliment of direct bit to carry.22
MOV C,bit Move direct bit to carry flag.21
MOV bit,C Move carry to direct bit.22
JC rel Jump if carry is set.22
JNC rel Jump if carry is not set.22
JB bit,rel Jump if direct bit is set.32
JNB bit,rel Jump if direct bit is not set.32
JBC bit,rel Jump if direct bit is set & clear bit.32
Program Branching
MnemonicDescriptionSizeCycles
ACALL addr11 Absolute subroutine call.22
LCALL addr16 Long subroutine call.32
RET Return from subroutine.12
RETI Return from
这里假定单片机是时钟频率为12MHz,则一个机器周期为:1us.
参考了51单片机 Keil C 延时程序的简单研究后,我们可知道, 在Keil C中获得最为准确的延时函数将是
 voiddelay(unsignedchart)
voiddelay(unsignedchart) {
{ while(--t);
while(--t); }
}
执行DJNZ指令需要2个机器周期,RET指令同样需要2个机器周期,根据输入t,在不计算调用delay()所需时间的情况下,具体时间延时如下:
| t | Delay Time (us) |
| 1 | 2×1+2 =4 |
| 2 | 2×2+2=6 |
| N | 2×N+2=2(N+1) |
当在main函数中调用delay(1)时, 进行反汇编如下:
调用delay()时,多执行了两条指令,其中MOV R, #da
Keil C仿真截图与计算过程:
加上调用时间,准确的计算时间延时与Keil C仿真对比如下:(可见,仿真结果和计算结果是很接近的)
| t | Delay Time (us) | 仿真11.0592Mhz时钟(us) |
| 1 | 3+2×1+2 =7 | 7.7(实际) | 7.60 |
| 2 | 3+2×2+2=9 | 9.9 | 9.76 |
| N | 3+2×N+2=2N+5 | (2N+5)*1.1 | / |
| 3 | 11 | 12.1 | 11.94 |
| 15 | 35 | 38.5 | 37.98 |
| 100 | 205 | 225.5 | 222.44 |
| 255 | 515 | 566.5 | 558.81 |
也就是说,这个延时函数的精度为2us,最小的时间延时为7us,最大的时间延时为3+255×2+2=515us.
实际中使用11.0592MHz的时钟,这个延时函数的精度将为2.2us,最小时间延时为7.7us, 最大时间延时为566.5us.
这个时间延时函数,对于与DS18B20进行单总线通信,已经足够准确了。
现在,我们将时钟换成11.0592MHz这个实际用到的频率,每个机器周期约为1.1us.
现在让我们来分析一下这个之前用过的延时函数:
//延时函数,对于11.0592MHz时钟,例i=10,则大概延时10ms.voiddelayMs(unsignedinti){unsignedintj;while(i--) {for(j=0;j<125;j++);
{for(j=0;j<125;j++); }}
}}
它的反汇编代码如下:
分析: T表示一个机器周期(调用时间相对于这个ms级的延时来说,可忽略不计)
1C:0000MOVA,R7;1T
2DECR7;1T低8位字节减1
3MOVR2,0x06;2T
4JNZC:0007;2T若低8位字节不为0,则跳到C:0007
5DECR6;1T低8位字节为0,则高8位字节减1
6C:0007ORLA,R2;1T
7JZC:001D;2T若高8位也减为0,则RET
8CLRA;1TA清零
9MOVR4,A;1TR4放高位
10MOVR5,A;1TR5放低位
11C:000DCLRC;1TC清零
12MOVA,R5;1T
13SUBBA,#0x7d;1TA=A-125
14MOVA,R4;1T
15SUBBA,#0x00;1TA
16JNCC:0000;2TA为零则跳到C:0000
17INCR5;1TR5增1
18CJNER5,#0x00,C:001B;2TR5>0,跳转到C:000D
19INCR4;1T
20C:001BSJMPC:000D;2T
21C:001DRET
对于delayMs(1), 执行到第7行就跳到21行, 共需时12T, 即13.2us
对于delayMs(2), 需时9T+13T+124×10T+7T+12T = 9T+13T+1240T+7T+12T =1281T =1409.1us.
对于delayMs(3), 需时9T×(3-1)+(13T+124×10T+7T)×(3-1)+12T
=1269T×(3-1)+12T=2550T=2805us.
对于delayMs(N),N>1, 需时1269T×(N-1)+12T = 1269NT-1257T=(1395.9N-1382.7)us.
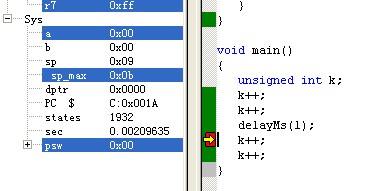
利用Keil C仿真delayMs(1) = 0.00166558s = 1.67ms 截图如下:
由分析可知具体的计算延时时间与Keil C仿真延时对比如下:
| i | Time Delay | 仿真延时 |
| 1 | 13.2us | 1.67ms |
| 2 | 1409.1us | 3.31ms |
| 3 | 2805us | 4.96ms |
| N | (1395.9N-1382.7)us | |
| 10 | 12.6ms | 16.50ms |
| 20 | 26.5ms | 32.98ms |
| 30 | 40.5ms | 49.46ms |
| 50 | 68.4ms | 82.43ms |
| 100 | 138.2ms | 164.84ms |
| 200 | 277.8ms | 329.56ms |
| 500 | 696.6ms | 824.13ms |
| 1000 | 1394.5ms | 1648.54ms |
| 1500 | 2092.5ms | 2472.34ms |
| 2000 | 2790.4ms | 3296.47ms |
| 5 | 5.6ms | 8.26ms |
| 73 | 100.5ms | 120.34ms |
| 720 | 1003.7ms = 1s | 1186.74ms |
计算delayMs(10)得到延时时间为:12576.3us约等于12.6ms,接近我们认为的10ms。
计算结果和仿真结果只要delayMs(1)有很大出入, 其它都接近, 在接受范围内.经过以上分析,可见用C语言来做延时并不是不太准确,只是不容易做到非常准确而已,若有一句语句变了,延时时间很可能会不同,因为编译程序生成的汇编指令很可能不同。
PS:
对于每条51单片机汇编指令的字长和所需机器周期汇总如下:转自:http://bbs.mcustudy.com/printpage.asp?BoardID=2&ID=1454
Appendix E - 8051 Instruction Set
Arithmetic Operations
MnemonicDescriptionSizeCycles
ADD A,Rn Add register to Accumulator (ACC).11
ADD A,direct Add direct byte to ACC.21
ADD A,@Ri Add indirect RAM to ACC.11
ADD A,#da
ADDC A,Rn Add register to ACC with carry.11
ADDC A,direct Add direct byte to ACC with carry.21
ADDC A,@Ri Add indirect RAM to ACC with carry.11
ADDC A,#da
SUBB A,Rn Subtract register from ACC with borrow.11
SUBB A,direct Subtract direct byte from ACC with borrow21
SUBB A,@Ri Subtract indirect RAM from ACC with borrow.11
SUBB A,#da
INC A Increment ACC.11
INC Rn Increment register.11
INC direct Increment direct byte.21
INC @Ri Increment indirect RAM.11
DEC A Decrement ACC.11
DEC Rn Decrement register.11
DEC direct Decrement direct byte.21
DEC @Ri Decrement indirect RAM.11
INC DPTR Increment da
MUL AB Multiply A and B Result: A <- low byte, B <- high byte.14
div AB Divide A by B Result: A <- whole part, B <- remainder. 14
DA A Decimal adjust ACC.11
Logical Operations
MnemonicDescriptionSizeCycles
ANL A,Rn AND Register to ACC.11
ANL A,direct AND direct byte to ACC.21
ANL A,@Ri AND indirect RAM to ACC.11
ANL A,#da
ANL direct,A AND ACC to direct byte.21
ANL direct,#da
ORL A,Rn OR Register to ACC.11
ORL A,direct OR direct byte to ACC.21
ORL A,@Ri OR indirect RAM to ACC.11
ORL A,#da
ORL direct,A OR ACC to direct byte.21
ORL direct,#da
XRL A,Rn Exclusive OR Register to ACC.11
XRL A,direct Exclusive OR direct byte to ACC.21
XRL A,@Ri Exclusive OR indirect RAM to ACC.11
XRL A,#da
XRL direct,A Exclusive OR ACC to direct byte.21
XRL direct,#da
CLR A Clear ACC (set all bits to zero).11
CPL A Compliment ACC.11
RL A Rotate ACC left.11
RLC A Rotate ACC left through carry.11
RR A Rotate ACC right.11
RRC A Rotate ACC right through carry.11
SWAP A Swap nibbles within ACC.11
Da
MnemonicDescriptionSizeCycles
MOV A,Rn Move register to ACC.11
MOV A,direct Move direct byte to ACC.21
MOV A,@Ri Move indirect RAM to ACC.11
MOV A,#da
MOV Rn,A Move ACC to register.11
MOV Rn,direct Move direct byte to register.22
MOV Rn,#da
MOV direct,A Move ACC to direct byte.21
MOV direct,Rn Move register to direct byte.22
MOV direct,direct Move direct byte to direct byte.32
MOV direct,@Ri Move indirect RAM to direct byte.22
MOV direct,#da
MOV @Ri,A Move ACC to indirect RAM.11
MOV @Ri,direct Move direct byte to indirect RAM.22
MOV @Ri,#da
MOV DPTR,#da
MOVC A,@A+DPTR Move co
MOVC A,@A+PC Move co
MOVX A,@Ri Move external RAM to ACC (8 bit address).12
MOVX A,@DPTR Move external RAM to ACC (16 bit address).12
MOVX @Ri,A Move ACC to external RAM (8 bit address).12
MOVX @DPTR,A Move ACC to external RAM (16 bit address).12
PUSH direct Push direct byte on
POP direct Pop direct byte from stack.22
XCH A,Rn Exchange register with ACC.11
XCH A,direct Exchange direct byte with ACC.21
XCH A,@Ri Exchange indirect RAM with ACC.11
XCHD A,@Ri Exchange low order nibble of indirect RAM with low order nibble of ACC.11
Boolean Variable Manipulation
MnemonicDescriptionSizeCycles
CLR C Clear carry flag.11
CLR bit Clear direct bit.21
SETB C Set carry flag.11
SETB bit Set direct bit.21
CPL C Compliment carry flag.11
CPL bit Compliment direct bit.21
ANL C,bit AND direct bit to carry flag.22
ANL C,/bit AND compliment of direct bit to carry.22
ORL C,bit OR direct bit to carry flag.22
ORL C,/bit OR compliment of direct bit to carry.22
MOV C,bit Move direct bit to carry flag.21
MOV bit,C Move carry to direct bit.22
JC rel Jump if carry is set.22
JNC rel Jump if carry is not set.22
JB bit,rel Jump if direct bit is set.32
JNB bit,rel Jump if direct bit is not set.32
JBC bit,rel Jump if direct bit is set & clear bit.32
Program Branching
MnemonicDescriptionSizeCycles
ACALL addr11 Absolute subroutine call.22
LCALL addr16 Long subroutine call.32
RET Return from subroutine.12
RETI Return from
C51单片机延时函 相关文章:
- Windows CE 进程、线程和内存管理(11-09)
- RedHatLinux新手入门教程(5)(11-12)
- uClinux介绍(11-09)
- openwebmailV1.60安装教学(11-12)
- Linux嵌入式系统开发平台选型探讨(11-09)
- Windows CE 进程、线程和内存管理(二)(11-09)