用于实现嵌入式安全的开源硬件
环的方式只实现一个乘法器并实现控制逻辑是合理的设计选择。
遵循标准的设计思路,我们将IP内核实现为存储器映射的外设。内核行为可以通过驱动软件使用控制寄存器改变(图4)。由于主环要求4个操作数,因此需要提供内存进行存储。中断线允许硬件就某些事件提醒处理器。
普通32位总线接口可以很容易扩展到多种流行的总线标准,如AXI或Wishbone。下面给出了最终设计的框图(n代表操作数的宽度)。
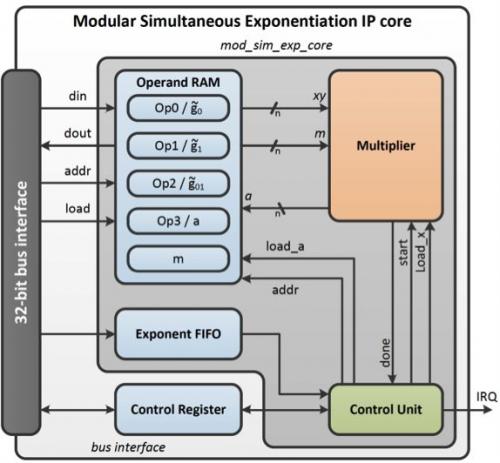
图4:我们开发的并行求幂IP内核的框图。
模乘
现在我们的工作将简化为设计一个乘法器,并且它能根据我们的需要方便地进行定制。当操作数长度大于512位(对我们的应用来说这是显然的情况)时,一种被称为脉动阵列蒙哥马利的乘法器(2)是最有效的实现。此外,它很容易转换成硬件,从而简化生成通用描述的任务。
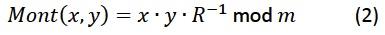
Mont(x,y)可以通过计算x的每一位的中间结果(a)进行运算。因此在经过n位后,乘法运算就完成了。a的每一位都可以用加法器和乘法器进行运算,最后一起形成脉动阵列单元(图5)。当大量单元级联时,为了中断进位链,我们将它们组成级。这样我们就可以控制设计的最大可达到频率,而这个频率主要受限于这个进位链。另外,还允许流水线运算。作为蒙哥马利算法一部分的右移操作可以确保a永远不会大于n+2位。
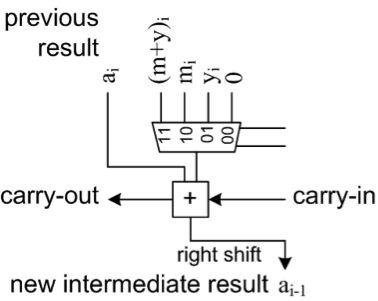
图5:一个脉动阵列单元计算中间结果a的一个位。
流水线操作见下图所示(图6)。每个圆代表一级。圆内的数字代表当时由那个级正在执行的步骤(x的哪一位)。非活动级用虚线表示。我们可以看到,一个级只能每2τc计算一步。这是右移操作的原因。τc表示一个级实际完成一个步骤所花的时间。在本例中,τc就是1个时钟周期。
图6:脉动流水线操作。
移位寄存器用于将x的位移进脉动流水线。两个额外加法器在必要时计算m+y(这是脉动阵列要求的)和a-m(确保结果小于m)。最终乘法器结构如下所示(图7)。
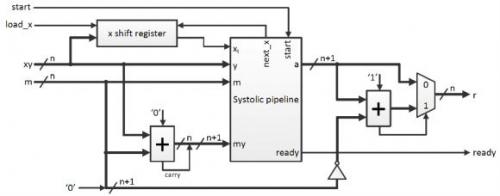
图7:蒙哥马利乘法器结构。
性能
乘法器资源使用率取决于操作数(n)的长度和流水线的级数(k)。
对FPGA来说可以表示为:
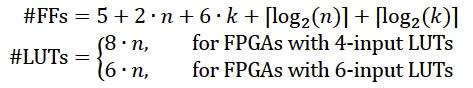
对于大的n来说,整个IP内核只使用另外一小部分FF和LUT比如用于控制逻辑和总线接口。然而,它也需要多个RAM单元来存储操作数。
执行乘法的时钟周期数也取决于n和k:
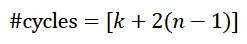
不过如前所述,级数——因此这些级的长度——对乘法器的最大可达时钟频率也有影响。这可以从图7看出来(n=2048)。
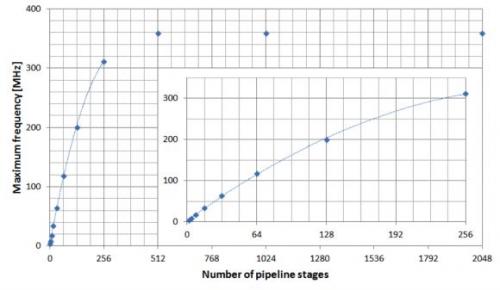
图8:流水线级长度对最高时钟频率的影响。
在使用这个设计时,可以有几种方法:
1.我们预先知道我们的工作频率。然后就足以选择级数以便让时钟频率至少能那么高。选择更多的级数只会导致耗用更多的资源(触发器)。
2.尽量缩短运算时间。这将由级数和最大时钟频率来确定。如果我们认为设计将在这个频率运行(理论上),我们可以获得下图所示的运算时间(n=1536)。我们可以看到,对我们的器件(Virtex 6)来说,当级长为4位时可以获得最短运算时间。
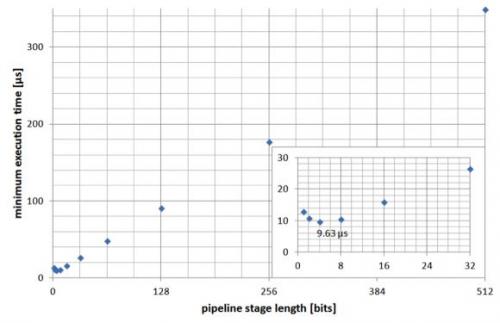
图9:流水线级长对最短执行时间的影响。
我们想要尽可能地减小时间与面积乘积。事实上,我们可以专注于最大限度地减小时间与FF数量的乘积,因为LUT数量基本上是常数。下图显示了不同流水线级长下的时间与FF数量乘积。当级长为8位时达到最小值。
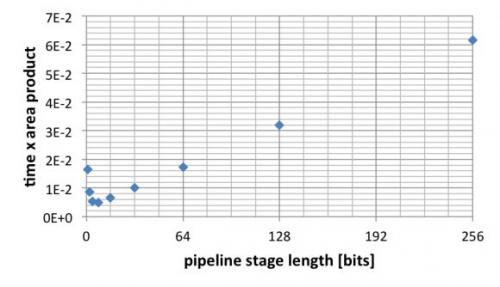
图10:流水线级长对时间与面积乘积的影响。
首次测试
基于NFC的ZKPK
作为第一次实际测试,我们实现了基于NFC的简化Schnorr ZKPK,详见我们的嵌入式测试平台介绍。这种个嵌入式平台是验证方,而PC(连接有PN532电路板)用作证明方。
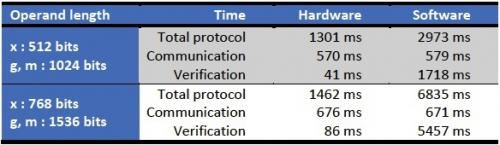
下表给出了不同操作数长度下的时序结果。很明显,当使用我们的硬件IP内核时,操作数长度对总的协议时间基本上没有影响。增加操作数长度会稍稍增加通信时间(这是预料中的)。然而,验证所需的时间将大大增加。
我们需要指出的是,通信占总时间的很大一部分。像产生随机数等一般数据操作也需要一定的时间。然而,我们的IP内核还无法克服这些挑战。
软件控制方案对比全自动操作
实现完整的并行求幂内核是一个英明的决策吗?为什么不只是乘法器和一些控制软件来实现算法1?因为我们可以将我们的IP内核用作乘法器,我们能够非常容易的测试它。我们可以在相同的系统上比较这两种方法。
即使我们将操作数存储在IP内核的RAM中(因此没有额外的总线业务量),全自动操作的速度仍要比软件控制方案快一个数量级(见图2)。这是意料之中的。Linux不是一种实时操作系统。在操作系统处理中断之前,或者应用程序访问它们需要的资源(本例中为我们的存储器映射外设)之前,可能需要等待一定的时间。如果你知道一次求幂要求大约(7/4)t乘法(见算法1),这种“损失时间”会很快累加起来。
如果你知道